Zagadnienia
15. Wydajność
15.1. Strojenie bazy danych
Strojenie bazy danych obejmuje dwa aspekty:
-
optymalizację wykorzystania procesora, pamięci i przestrzeni dyskowej przez operacje na bazie danych;
-
optymalizację wykonywania zapytań (np. w Postgresie polecenia CREATE INDEX, VACUUM, VACUUM ANALYSE, CLUSTER i EXPLAIN).
15.2. Indeksy nad kolumnami tabeli
Potrzebne są co najmniej indeksy dla klucza głównego tabeli oraz każdego klucza obcego.
Do dużych zapytań często potrzebne są indeksy złożone, których klucze składają się z kilku kolumn. Sztuka korzystania z indeksów złożonych polega na odpowiednim wyborze kolejności kolumn w indeksie. Zamiast korzystać z intuicyjnie ,,naturalnej” kolejności kolumn należy zacząć od kolumny dającej największą redukcję.
Rozważmy na przykład indeks obejmujący kolumny kodu firmy, numeru konta oraz typu transakcji w tabeli pozycji dziennika bazy danych dla księgowości finansowej. Jeśli istnieją tylko dwie firmy, kolumna numeru konta redukuje liczbę wierszy wynikowych znacznie bardziej niż kolumna kodu firmy.
Podobnie typ transakcji redukuje dalej wiersze wynikowe bardziej niż kod firmy. Tak więc właściwa kolejność kolumn w indeksie to kod konta, typ transakcji i na końcu kod firmy.
Budowa optymalnych indeksów może o rząd wielkości zmienić czas wykonania zapytania.
15.3. Wybór indeksów
Podczas pisania zdań SQL w raportach warto mieć w pamięci kilka wskazówek:
-
Upewnij się, że istnieje indeks dla każdej kolumny używanej w złączeniu. Indeks może obejmować inne kolumny z tabeli pod warunkiem, że kolumna złączenia występuje na pierwszym miejscu.
-
Co najmniej jedna z kolumn złączenia powinna mieć unikalny indeks. Jest to naturalna reguła przy złączeniach opartych na związkach z diagramu związków encji. Jedna z kolumn w złączeniu będzie wtedy jednoznacznym identyfikatorem (kluczem głównym) tabeli.
-
Zredukuj korzystanie z podzapytań skorelowanych w SQL — staraj się używać złączeń. Optymalizator SQL jest bowiem zwykle nastawiony na złączenia, zwłaszcza gdy istnieją odpowiednie indeksy. Zależy to jednak od konkretnej implementacji.
15.3.1. Rozmieszczenie wierszy tabeli
Poleceniem CLUSTER można zmienić kolejność wierszy w tabeli na zgodną z podanym indeksem. Ma to sens głównie dla indeksów nieunikalnych, gdy występuje wiele wierszy o tej samej wartości indeksu, lub też w sytuacjach, gdy indeks jest używany do wybierania wierszy z pewnego zakresu klucza indeksowego.
15.4. Denormalizacja
Normalizacja upraszcza zachowanie integralności danych dzięki wyeliminowaniu ich dublowania. Prowadzi to jednak zwykle do zwiększenia liczby tabel używanych w pojedynczej funkcji, a co za tym idzie liczby złączeń — najbardziej kosztownej operacji.
Weźmy na przykład typowy dla komputeryzacji zwyczaj kodowania wszystkiego. Używa się kodów dla kolorów, kategorii, klas, stopni jakości — czyli każdej cechy, która może być opisana jedną z listy predefiniowanych wartości.
W znormalizowanej strukturze bazy danych dla każdego rozdzaju kodu jest potrzebna osobna tabela danych słownikowych, zawierająca opis tego kodu. Normalizacji dokonuje się po to, aby w razie zmiany opisu modyfikacja była wykonywana tylko w jednym miejscu.
Nie zawsze jednak elementy takich list ulegają częstym zmianom. Ponadto jeśli producent samochodów wprowadza nową barwę, np. cynober, to inne kolory dalej są aktualne. W praktyce więc do takich list dodaje się nowe elementy, ale nie modyfikuje istniejących. Opisy kodów można by więc przechowywać zarówno w głównej tabeli, jak i w tabeli słownikowej.
Tabela z danymi słownikowymi jest wciąż przydatna do weryfikacji danych przy wstawianiu lub modyfikacji. A przy okazji, często używany argument o możliwości błędów literowych staje się przestarzały, gdyż do wprowadzania opisów będziemy stosować wybór z listy. Tabela słownikowa przydaje się wtedy do wyświetlania listy wyborów.
Zaprojektowanie wydajnej bazy danych wymaga więc czasem kompromisu między szybkim dostępem a dublowaniem danych. Zdublowane dane wymagają bardziej złożonych algorytmów zachowania integralności, a to powoduje większą złożoność programów.
Przed przyspieszeniem dostępu należy zbadać rodzaje dostępu wymagane przez kluczowe funkcje i skutki korzystania wyłącznie ze znormalizowanych struktur.
15.5. Pamięć buforowa (cache)
Podstawowe cele przy optymalizacji wykorzystania zasobów serwera bazy danych to trzymanie potrzebnej informacji w pamięci operacyjnej (RAM) i unikanie niepotrzebnych dostępów do dysku.
W PostgreSQL używa się dzielonej pamięci zawierającej bufory. Standardowo przydziela się 64 bufory po 8kB każdy. Pamięć ta jest przydzielana podczas startu programu postmaster — serwera Postgresa.
Backend DBMS najpierw szuka żądanej informacji w pamięci buforowej. Dopiero gdy nie znajdzie zgłasza żądanie do systemu operacyjnego. Informacja jest wtedy ładowana z pamięci buforowej jądra lub z dysku.
Dlaczego rozmiar pamięci buforowej jest ważny?
-
Jeśli cała tabela zmieści się w pamięci buforowej, to przeglądanie sekwencyjne jest bardzo szybkie.
-
Natomiast jeśli zabraknie miejsca choćby na jeden blok dyskowy, przy każdym przeglądzie następuje wymiana — wczytanie brakujących bloków z dysku.
-
Jeśli jako strategii wymiany używa się LRU (least recently used, to podczas pierwszego przeglądania usunięty zostanie z pamięci buforowej tylko pierwszy blok (żeby zrobić miejsce dla ostatniego).
-
Jednak już przy drugim przeglądaniu aby ściągnąć do pamięci pierwszy blok zostanie z niej usunięty drugi (bo jest ,,najstarszy”) itd.
Pozornie najlepiej byłoby przydzielić jak największą pamięć buforową. Nie jest to jednak prawda, bo wtedy zaczyna brakować miejsca dla programów:
-
często występuje wymiatanie do pamięci wymiany (swap),
-
czyli pojawiają się częstsze dostępy do dysku!
Należy to więc kontrolować, np. poleceniami vmstat i sar Unixa.
15.6. Dostęp do dysku
Dostęp do bloków dyskowych jest najszybszy wtedy, kiedy znajdują się one blisko aktualnego położenia głowicy. Kierując się tym, systemy operacyjne takie jak Unix próbują odpowiednio rozmieszczać pliki kierując się założeniem, że najczęściej stosowaną metodą dostępu jest sekwencyjne czytanie kolejnych bloków.
PostgreSQL przy czytaniu dużych ilości danych preferuje więc dostęp sekwencyjny, starając się wtedy nie korzystać z indeksów.
Należy jednak pamiętać, że głowica jest używana nie tylko dla plików bazy danych. Dlatego warto pliki bazy danych trzymać na osobnym dysku (rzecz jasna fizycznym, a nie na osobnej partycji dyskowej, bo to nic nie da).
Poleceniem initlocation Postgresa można rozmieszczać bazę danych na różnych dyskach. Można też stosować linki symboliczne ale wtedy są kłopoty z usuwaniem tabel w Postgresie
-
Pliki pg_database.oid i pg_class.relfilenode odwzorowują bazy danych, tabele i indeksy na numeryczne końcówki plików.
Przy dużych bazach danych można też
-
trzymać indeksy na innych dyskach niż ich tabele,
-
rozdzielać często łączone tabele na osobne dyski.
15.7. Dziennik
Oczywiście warto (i powinno się) na osobnym dysku trzymać dziennik: katalog pg_xlog w Postgresie. Dziennik nie używa pamięci buforowej, ponieważ korzysta z zapisu natychmiastowego (immediate write). Transakcja jest kontynuowana dopiero po zakończeniu zapisu do dziennika.
15.8. Oczyszczanie bazy
Czasem sposób organizacji danych na dysku pociąga za sobą konieczność okresowego ,,sprzątania” bazy danych.
Przykładowo polecenie VACUUM w Postgresie służy do usuwania przeterminowanych wierszy z tabel bazy danych.
-
Gdy Postgres modyfikuje wiersz, tworzy jego nową kopię, a starą zaznacza jako ,,przeterminowaną”. Podobnie działa usuwanie.
-
Dzięki temu inne transakcje mogą widzieć bazę danych w ,,starym” stanie.
-
Po zakończeniu transakcji takie przeterminowane wiersze są już zbędne, ale nie są usuwane z tabel, ponieważ zakłada się, że miejsce po nich zostanie wykorzystane w przyszłości na nowo wstawiane wiersze.
-
Po dużych zmainach w tabeli warto takie puste miejsca usunąć. Należy to robić w okresach małego obciążenia, ponieważ tabele muszą zostać w całości zablokowane.
Opcja ANALYZE polecenia VACUUM dodatkowo uaktualnia statystyki używane przez optymalizator zapytań.
15.9. Optymalizacja wykonania zapytań
Polecenie SQL EXPLAIN otrzymuje jako argument zapytanie SQL, lecz zamiast wykonać je, pokazuje plan wykonania zapytania. Można w ten sposób obserwować, czy utworzony indeks jest rzeczywiście wykorzystywany przez optymalizator Postgresa.
Plan pokazuje rodzaj przeszukiwaniu (skanu) dla poszczególnych tabel (skan sekwencyjny, skan indeksowy, …). Jeśli zapytanie używa wielu tabel, to pokazuje się także użyte algorytmy złączenia.
Popatrzmy na przykłady
bd=# explain select * from zwierz;
QUERY PLAN
----------------------------------------------------------
Seq Scan on zwierz (cost=0.00..18.50 rows=850 width=61)
(1 row)
bd=# explain select * from zwierz where waga < 1000;
QUERY PLAN
----------------------------------------------------------
Seq Scan on zwierz (cost=0.00..20.62 rows=283 width=61)
(1 row)
bd=# explain select * from zwierz where waga < 3;
QUERY PLAN
----------------------------------------------------------
Index Scan using zwierz_waga on zwierz
(cost=0.00..3.17 rows=10 width=61)
(1 row)
bd=# explain select * from zwierz, gatunki
bd-# where zwierz.gatunek = gatunki.gatunek
bd-# and waga < 500;
QUERY PLAN
-----------------------------------------------------------------------
Hash Join (cost=29.58..54.09 rows=283 width=120)
Hash Cond: ((zwierz.gatunek)::text = (gatunki.gatunek)::text)
-> Seq Scan on zwierz (cost=0.00..20.62 rows=283 width=61)
Filter: (waga < 500)
-> Hash (cost=18.70..18.70 rows=870 width=59)
-> Seq Scan on gatunki (cost=0.00..18.70 rows=870 width=59)
(6 rows)
Opis planu wykonania (QUERY PLAN) używa operatorów (iteratorów):
-
Przeglądanie (skanowanie) tabel:
-
table-scan
-
index-scan
-
-
Sortowanie podczas skanowania
-
sort-scan
-
15.10. Przetwarzanie zapytania
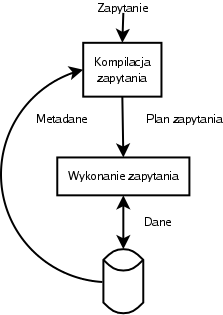
Zapytanie jest przetwarzane w dwóch etapach. Kompilacja zapytania składa się z następujących czynności:
-
Analiza składniowa zapytania (parsing). Sprawdzenie poprawności syntaktycznej i transformacja zapytania na drzewo wyrażeń.
-
Preprocessing: kontrola semantyczna, transformacje drzewa np. na wyrażenia algebry relacji.
-
Optymalizacja: najpierw wybór wybór planu logicznego, a następnie planu fizycznego, sformułowanego w operacjach sprzętowych.
Tak wykonany plan może być wykonany natychmiast lub przechowany w celu późniejszego (być może wielokrotnego) wykonania. Standard SQL obejmuje tę możliwość w postaci instrukcji PREPARE i EXECUTE.


