Zagadnienia
2. Metoda najmniejszych kwadratów (MNK)
Metoda najmniejszych kwadratów (MNK). Sformułowanie zadania. Wyznaczanie optymalnych wartości parametrów. Oszacowanie błędu przybliżenia. Algebraiczne własności MNK. (1 wykład)
2.1. Wprowadzenie
Zadanie.
Dane jest ![]() ciągów
ciągów ![]() -elementowych o wyrazach rzeczywistych:
-elementowych o wyrazach rzeczywistych:
Wyznaczyć współczynniki ![]() ,
które minimalizują błąd przybliżenia
,
które minimalizują błąd przybliżenia ![]() przez kombinację liniową
przez kombinację liniową ![]()
Czyli mamy rozwiązać zadanie optymalizacyjne
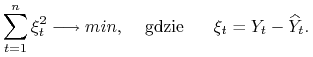 |
W zastosowaniach ekonometrycznych ![]() nazywa się zmienną modelową w odróżnieniu od zmiennej empirycznej
nazywa się zmienną modelową w odróżnieniu od zmiennej empirycznej ![]() .
.
W dalszym ciągu będziemy stosować zapis macierzowy:![]() będzie zapisywać jako wektor kolumnowy czyli macierz
będzie zapisywać jako wektor kolumnowy czyli macierz ![]()
![Y=\left(\begin{array}[]{l}Y_{1}\\
\dots\\
Y_{n}\end{array}\right),](wyklady/ekn/mi/mi74.png) |
![]() jako macierz
jako macierz ![]() , której kolumnami są
, której kolumnami są ![]()
![X=\left(\begin{array}[]{llll}X_{{1,1}}&X_{{1,2}}&\dots&X_{{1,m}}\\
X_{{2,1}}&X_{{2,2}}&\dots&X_{{2,m}}\\
\dots&\dots&\dots&\dots\\
X_{{n,1}}&X_{{n,2}}&\dots&X_{{n,m}}\end{array}\right),](wyklady/ekn/mi/mi111.png) |
szukane parametry ![]() jako wektor kolumnowy
jako wektor kolumnowy ![]()
![B=\left(\begin{array}[]{l}b_{1}\\
\dots\\
b_{m}\end{array}\right),](wyklady/ekn/mi/mi69.png) |
podobnie składnik resztowy (residualny) ![]() jako wektor kolumnowy
jako wektor kolumnowy ![]()
![\xi=\left(\begin{array}[]{l}\xi _{1}\\
\dots\\
\xi _{n}\end{array}\right).](wyklady/ekn/mi/mi81.png) |
Wówczas możemy zapisać
Suma kwadratów reszt (SKR) wynosi
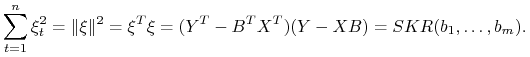 |
Zauważmy, że funkcja
jest funkcją kwadratową o wartościach nieujemnych, a zatem osiąga swoje minimum.
Twierdzenie 2.1
Jeżeli ciągi ![]() , … ,
, … , ![]() są liniowo niezależne to
są liniowo niezależne to ![]() przyjmuje minimum dokładnie w jednym punkcie
przyjmuje minimum dokładnie w jednym punkcie
| (2.1) |
Minimum to wynosi
Dowód.
Krok 1. Najpierw pokażemy, że macierz ![]() jest odwracalna a zatem wzór 2.1 jest poprawny.
jest odwracalna a zatem wzór 2.1 jest poprawny.
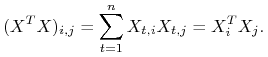 |
![]() macierz
macierz ![]() jest macierzą Grama wektorów
jest macierzą Grama wektorów ![]() . Zatem jeżeli
. Zatem jeżeli ![]() są liniowo niezależne to macierz
są liniowo niezależne to macierz
![]() jest nieujemnie określona, a zatem odwracalna (por. [1] §VI.11 Wniosek 11.4).
jest nieujemnie określona, a zatem odwracalna (por. [1] §VI.11 Wniosek 11.4).
Krok 2.
Pokażemy, że ![]() to punkt w którym przyjmowane jest minimum globalne.
to punkt w którym przyjmowane jest minimum globalne.
Zauważmy, że drugi człon jest równy 0
a trzeci jest nieujemny dla niezerowych ![]() ponieważ macierz
ponieważ macierz
![]() jest nieujemnie określona. Zatem dla
jest nieujemnie określona. Zatem dla ![]()
Krok 3. Wyznaczamy ![]() .
.
Ponieważ jak pokazaliśmy powyżej ![]() to
to
Wniosek 2.1
Dla ![]() zachodzą następujące zależności:
zachodzą następujące zależności:
1. Wektor składników resztowych ![]() jest prostopadły do wszystkich kolumn
jest prostopadły do wszystkich kolumn ![]()
2. Wektor składników resztowych ![]() jest prostopadły do wektora
jest prostopadły do wektora ![]()
3. Uogólnione twierdzenie Pitagorasa
Dowód.
Ad 1. Z definicji ![]() mamy
mamy
Ad 2. ![]() jest kombinacją liniową
jest kombinacją liniową ![]() zatem
zatem
Ad 3. Ponieważ ![]() i
i ![]() są prostopadłe to
są prostopadłe to
Uwaga 2.1
Gdy ciągi ![]() , … ,
, … , ![]() są liniowo zależne to
wybieramy spośród nich maksymalny podzbiór liniowo niezależny
są liniowo zależne to
wybieramy spośród nich maksymalny podzbiór liniowo niezależny
![]() , … ,
, … , ![]() (
(![]() ). Niech
). Niech ![]() będzie
będzie ![]() macierzą, której kolumnami są
macierzą, której kolumnami są ![]() .
.
Zmienna modelowa jest wyznaczona jednoznacznie (niezależnie od wyboru ciągów liniowo niezależnych)
gdzie
Natomiast ![]() przyjmuje minimum na podprzestrzeni afinicznej
złożonej z punktów postaci
przyjmuje minimum na podprzestrzeni afinicznej
złożonej z punktów postaci
gdzie
![B^{\ast}_{j}=\left\{\begin{array}[]{ccc}\widetilde{B}_{{min,{i}}}&\mbox{gdy}&j=j_{i},\\
0&\mbox{gdy}&j\not\in\{ j_{1},\dots,j_{k}\},\end{array}\right.](wyklady/ekn/mi/mi114.png) |
a wektory ![]() opisują zależności między ciągami
opisują zależności między ciągami ![]()
Ponadto spełnione są punkty 1,2 i 3 z powyższego wniosku.
2.2. Odrobina algebry liniowej
Oznaczmy przez ![]() podprzestrzeń liniową przestrzeni
podprzestrzeń liniową przestrzeni ![]() rozpiętą przez kolumny macierzy
rozpiętą przez kolumny macierzy ![]() ,
,
Lemat 2.1
Macierz kwadratowa ![]()
jest macierzą rzutu prostopadłego na podprzestrzeń ![]() ,
a macierz
,
a macierz
macierzą rzutu prostokątnego na podprzestrzeń ![]() (dopełnienie ortogonalne
(dopełnienie ortogonalne ![]() ).
).
Dowód.
Mnożenie przez macierz ![]() zachowuje wektory z
zachowuje wektory z ![]()
i anihiluje wektory prostopadłe do ![]()
Natomiast mnożenie przez macierz ![]() anihiluje wektory z
anihiluje wektory z ![]() i zachowuje wektory prostopadłe do
i zachowuje wektory prostopadłe do ![]()
Lemat 2.2
1. Macierze ![]() i
i ![]() są symetryczne i idempotentne
są symetryczne i idempotentne
2. Rząd macierzy ![]() wynosi
wynosi ![]() , a
, a ![]()
![]() .
.
3. Ślad macierzy ![]() wynosi
wynosi ![]() , a
, a ![]()
![]() .
.
4. Istnieje taka ![]() macierz unitarna
macierz unitarna ![]() (tzn.
(tzn. ![]() ), że
macierze
), że
macierze ![]() i
i ![]() są diagonalne o wyrazach 0 lub 1.
są diagonalne o wyrazach 0 lub 1. ![]() ma na przekątnej
ma na przekątnej ![]() jedynek, a
jedynek, a ![]()
![]() .
.
Dowód.
Ad.1. ![]() i
i ![]() są macierzami rzutów zatem
są macierzami rzutów zatem ![]() i
i ![]() . Symetria wynika z faktu, że transpozycja jest przemienna z odwracaniem macierzy
. Symetria wynika z faktu, że transpozycja jest przemienna z odwracaniem macierzy
Ad.2. Rząd macierzy jest równy wymiarowi obrazu, zatem
Ad.3. ![]() jest macierzą rzutu na podprzestrzeń
jest macierzą rzutu na podprzestrzeń ![]() wymiarową, a zatem ma
wymiarową, a zatem ma ![]() wartości własnych równych 1 i
wartości własnych równych 1 i ![]() równych 0. Natomiast
równych 0. Natomiast ![]() jest macierzą rzutu na podprzestrzeń
jest macierzą rzutu na podprzestrzeń ![]() wymiarową, a zatem ma
wymiarową, a zatem ma ![]() wartości własnych równych 1 i
wartości własnych równych 1 i ![]() równych 0. Ponieważ ślad jest to suma wartości własnych to wynosi on odpowiednio
równych 0. Ponieważ ślad jest to suma wartości własnych to wynosi on odpowiednio ![]() i
i ![]() .
.
Ad.4. Niech wektory ![]() tworzą bazę ortonormalną podprzestrzeni
tworzą bazę ortonormalną podprzestrzeni ![]() , a
, a
![]() bazę podprzestrzeni
bazę podprzestrzeni ![]() . Niech
. Niech ![]() będzie macierzą o kolumnach
będzie macierzą o kolumnach ![]() .
Wówczas
.
Wówczas
Zatem wszystkie trzy macierze są diagonalne i zero-jedynkowe.


