Zagadnienia
8. Metody asymptotyczne
Zbieżność ciągów zmiennych losowych. Metoda delty. Asymptotyczna normalność estymatorów. Stacjonarność i ergodyczność. Ciągi przyrostów martyngałowych. Centralne Twierdzenie Graniczne dla przyrostów martyngałowych. (1 wykład)
8.1. Zbieżność zmiennych losowych
Omówimy pokrótce trzy pojęcia zbieżności zmiennych losowych.
Niech ![]() – przestrzeń probabilistyczna.
Rozważmy ciąg zmiennych losowych
– przestrzeń probabilistyczna.
Rozważmy ciąg zmiennych losowych ![]() o wartościach w
o wartościach w ![]() .
.
Definicja 8.1
Ciąg zmiennych losowych ![]() zbiega prawie napewno do zmiennej losowej
zbiega prawie napewno do zmiennej losowej ![]() gdy
gdy
W zapisie skróconym będziemy pisali
Definicja 8.2
Ciąg zmiennych losowych ![]() zbiega według prawdopodobieństwa do zmiennej losowej
zbiega według prawdopodobieństwa do zmiennej losowej ![]() gdy
gdy
gdzie ![]() oznacza normę w
oznacza normę w ![]() .
.
W zapisie skróconym będziemy pisali
Definicja 8.3
Ciąg zmiennych losowych ![]() zbiega według rozkładu do zmiennej losowej
zbiega według rozkładu do zmiennej losowej ![]() gdy
ciąg dystrybuant
gdy
ciąg dystrybuant ![]() zbiega do dystrybuanty
zbiega do dystrybuanty ![]() w każdym punkcie ciągłości
w każdym punkcie ciągłości ![]() .
.
W zapisie skróconym będziemy pisali
gdzie ![]() jest rozkładem zmiennej losowej
jest rozkładem zmiennej losowej ![]() .
.
Uwaga 8.1
Jeśli
ciąg różnic ![]() zbiega do 0 według prawdopodobieństwa i
ciąg
zbiega do 0 według prawdopodobieństwa i
ciąg ![]() zbiega według rozkładu do zmiennej losowej
zbiega według rozkładu do zmiennej losowej ![]() , to również
, to również ![]() zbiega według rozkładu do
zbiega według rozkładu do ![]()
Uwaga 8.2
Trzy powyższe zbieżności są od siebie zależne. Mamy
Aby zamknąć powyższy diagram należy dopuścić zmianę przestrzeni probabilistycznej i skorzystać z następującego twierdzenia o reprezentacji prawie napewno.
Twierdzenie 8.1
(Skorochod)
Jeśli ciąg zmiennych losowych ![]() zbiega według rozkładu do zmiennej losowej
zbiega według rozkładu do zmiennej losowej ![]() to istnieje przestrzeń probabilistyczna
to istnieje przestrzeń probabilistyczna
![]() i określone na niej zmienne losowe
i określone na niej zmienne losowe ![]() i
i ![]() ,
, ![]() takie, że
takie, że
![]() ma ten sam rozkład co
ma ten sam rozkład co ![]() , a
, a ![]() co
co ![]() i
ciąg zmiennych losowych
i
ciąg zmiennych losowych ![]() zbiega prawie napewno do zmiennej losowej
zbiega prawie napewno do zmiennej losowej ![]() .
.
Sformułujemy teraz kilka przydatnych w ekonometrii twierdzeń o zbieżności zmiennych losowych.
Twierdzenie 8.2
O odwzorowaniu ciągłym.[2, 16]
Niech ![]() oznacza zbiór punktów nieciągłości funkcji
oznacza zbiór punktów nieciągłości funkcji
Wówczas
jeśli ciąg zmiennych losowych ![]() zbiega według rozkładu, prawdopodobieństwa lub prawie napewno do zmiennej losowej
zbiega według rozkładu, prawdopodobieństwa lub prawie napewno do zmiennej losowej ![]() takiej, że
takiej, że
to
ciąg zmiennych losowych ![]() zbiega odpowiednio według rozkładu, prawdopodobieństwa lub prawie napewno do zmiennej losowej
zbiega odpowiednio według rozkładu, prawdopodobieństwa lub prawie napewno do zmiennej losowej ![]() .
.
Twierdzenie 8.3
(Slutsky)
Niech ![]() i
i ![]() ciagi zmiennych losowych o wartościach macierzowych,
ciagi zmiennych losowych o wartościach macierzowych, ![]() macierzowa zmienna losowa i
macierzowa zmienna losowa i ![]() macierz (deterministyczna). Wówczas, jeśli
macierz (deterministyczna). Wówczas, jeśli
to:
gdzie ![]() to dowolna macierz losowa taka, że
to dowolna macierz losowa taka, że
gdy ![]() .
.
Dowód.
Ponieważ ![]() zbiega do stałej, to
zbiega do stałej, to
Działania ![]() są ciągłe zatem z twierdzenia o odwzorowaniu ciągłym (8.2)
otrzymujemy tezę twierdzenia.
są ciągłe zatem z twierdzenia o odwzorowaniu ciągłym (8.2)
otrzymujemy tezę twierdzenia.
W przypadku odwracania macierzy zbiorem punktów nieciągłości jest zbiór macierzy o wyznaczniku 0.
Zatem wystarczy zauważyć, że prawdopodobieństwo, że odwracalna macierz deterministyczna ma zerowy wyznacznik jest równe 0.
Uwaga 8.3
Niech ![]() i
i ![]() to wektory kolumnowe, czyli macierze
to wektory kolumnowe, czyli macierze ![]() , a
, a ![]() i
i ![]() macierze
macierze ![]() .
Wówczas, jeśli
.
Wówczas, jeśli
to
Twierdzenie 8.4
Metoda delty.
Niech ![]() ciąg zmiennych losowych o wartościach w
ciąg zmiennych losowych o wartościach w ![]() , X zmienna losowa o wartościach w
, X zmienna losowa o wartościach w ![]() ,
,
![]() punkt z
punkt z ![]() , a
, a ![]() funkcja różniczkowalna w
funkcja różniczkowalna w ![]() .
Wówczas, jeśli
.
Wówczas, jeśli
to
8.2. Estymatory jako ciągi zmiennych losowych
Załóżmy, że proces generujący dane ![]() ,
, ![]() , pochodzi z parametrycznej rodziny procesów
, pochodzi z parametrycznej rodziny procesów
![]() , gdzie zbiór parametrów
, gdzie zbiór parametrów ![]() jest podzbiorem
jest podzbiorem ![]()
Ustalmy funkcję ![]() i rodzinę estymatorów
i rodzinę estymatorów
wartości funkcji ![]() w punkcie
w punkcie ![]() .
Niech
.
Niech ![]() będzie estymatorem
będzie estymatorem ![]() , wyznaczonym na podstawie próbki
rozmiaru
, wyznaczonym na podstawie próbki
rozmiaru ![]() , tzn.
, tzn.
Definicja 8.4
Ciąg estymatorów ![]() nazywamy nazywamy zgodnym gdy
nazywamy nazywamy zgodnym gdy
Definicja 8.5
Zgodny ciąg estymatorów ![]() nazywamy nazywamy asymptotycznie normalnym gdy
nazywamy nazywamy asymptotycznie normalnym gdy
Uwaga 8.5
Macierz ![]() oznaczamy
oznaczamy ![]() i nazywamy asymptotyczną wariancją estymatora
i nazywamy asymptotyczną wariancją estymatora ![]() .
.
8.3. Stacjonarność i ergodyczność procesów stochastycznych
8.3.1. Definicje i podstawowe własności
Niech ![]() będzie
będzie ![]() -wymiarowym procesem stochastycznym (ciągiem zmiennych losowych)
określonym na przestrzeni probabilistycznej
-wymiarowym procesem stochastycznym (ciągiem zmiennych losowych)
określonym na przestrzeni probabilistycznej ![]() .
.
Definicja 8.6
Proces stochastyczny ![]() jest (silnie) stacjonarny gdy dla dowolnych
jest (silnie) stacjonarny gdy dla dowolnych ![]() łączne rozkłady
łączne rozkłady
są identyczne.
Wniosek 8.1
Jeśli proces stochastyczny ![]() jest stacjonarny i
jest stacjonarny i ![]() należą do
należą do ![]() , to dla wszystkich
, to dla wszystkich ![]()
Definicja 8.7
Stacjonarny proces stochastyczny ![]() ma własność mieszania gdy dla dowolnych ograniczonych funkcji borelowskich
ma własność mieszania gdy dla dowolnych ograniczonych funkcji borelowskich
![]() i
i ![]() oraz indeksów
oraz indeksów ![]()
Definicja 8.8
Stacjonarny proces stochastyczny ![]() jest ergodyczny gdy
jest ergodyczny gdy
Twierdzenie 8.5
Twierdzenie ergodyczne.
Jeśli proces stochastyczny ![]() jest stacjonarny i
jest stacjonarny i ![]() należą do
należą do ![]() , to
zachodzdzą implikacje
, to
zachodzdzą implikacje
gdzie
a. ![]() ma własność mieszania,
ma własność mieszania,
b. ![]() jest ergodyczny,
jest ergodyczny,
c. średnie zbiegają do wartości oczekiwanej
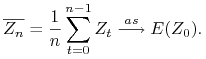 |
Uwaga 8.6
Jeśli proces stochastyczny ![]() jest stacjonarny i ma własność mieszania a
jest stacjonarny i ma własność mieszania a ![]() jest funkcją borelowską to
proces
jest funkcją borelowską to
proces ![]() też jest stacjonarny i ma własność mieszania.
też jest stacjonarny i ma własność mieszania.
Zatem jeśli ![]() należą do
należą do ![]() to
to
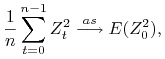 |
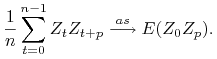 |
Wniosek 8.2
Dla procesów stacjonarnych i ergodycznych średnie próbkowe są zgodnymi estymatorami.
8.3.2. Przykłady
Definicja 8.9
Proces ![]() nazywamy gaussowskim białym szumem gdy
nazywamy gaussowskim białym szumem gdy
Lemat 8.1
Biały szum jest stacjonarny i ergodyczny.
Dowód.
Dla dowolnych indeksów ![]() i
i ![]() wektor
wektor
![]() ma rozkład
ma rozkład ![]() . Rozkład ten nie zależy od
. Rozkład ten nie zależy od ![]() co implikuje stacjonarność.
co implikuje stacjonarność.
Aby pokazać własność mieszania zauważmy, że dla ![]() zmienne losowe
zmienne losowe
![]() i
i ![]() są niezależne.
Zatem dla
są niezależne.
Zatem dla ![]() odpowiednio dużych
odpowiednio dużych
Uwaga 8.7
Powyższe rozumowanie można zastosować dla dowolnego procesu iid tzn. o wyrazach niezależnych i o jednakowym rozkładzie.
Proces autoregresyjny
Niech ![]() będzie gaussowskim białym szumem. Dodatkowo założymy, ze
będzie gaussowskim białym szumem. Dodatkowo założymy, ze ![]() .
Proces
.
Proces ![]() zdefiniujemy rekurencyjnie:
zdefiniujemy rekurencyjnie:
gdzie ![]() rzeczywiste parametry,
rzeczywiste parametry, ![]() ,
, ![]() .
Tak zdefiniowany proces nazywa się autoregresyjnym rzędu 1 (
.
Tak zdefiniowany proces nazywa się autoregresyjnym rzędu 1 (![]() ).
).
Lemat 8.2
Proces ![]() jest stacjonarny i ergodyczny.
jest stacjonarny i ergodyczny.
Dowód.
Krok 1.
Pokażemy, że wszystkie ![]() mają rozkład normalny o parametrach
mają rozkład normalny o parametrach ![]() i
i ![]()
Zastosujemy indukcję po ![]() .
.
Jak łatwo zauważyć ![]() ma rozkład normalny oraz
ma rozkład normalny oraz
Załóżmy, że
Ponieważ ![]() i
i ![]() mają rozkłady normalne i są niezależne to
mają rozkłady normalne i są niezależne to ![]() ma rozkład normalny.
Ponadto
ma rozkład normalny.
Ponadto
Krok 2.
Pokażemy, że ![]() .
.
Zastosujemy indukcję po ![]() .
.
Dla ![]() mamy
mamy
Załóżmy, że
Wówczas
Krok 3.
Stacjonarność.
Z poprzednich dwóch ”kroków” wynika, że rozkład wektora
![]() nie zależy od
nie zależy od ![]() . Rzeczywiście
. Rzeczywiście
gdzie ![]() jest wektorem o
jest wektorem o ![]() współrzędnych, które są wszystkie równe 1,
współrzędnych, które są wszystkie równe 1, ![]() ,
a
,
a ![]() jest macierzą
jest macierzą ![]() o wyrazach
o wyrazach
![]() , czyli
, czyli
![R_{p}=\left(\begin{array}[]{ccccc}1&\rho&\rho^{2}&\dots&\rho^{{p}}\\
\rho&1&\rho&\dots&\rho^{{p-1}}\\
\dots&\dots&\dots&\dots&\dots\\
\rho^{{p-1}},&\rho^{{p-2}}&\rho^{{p-3}}&\dots&\rho\\
\rho^{p},&\rho^{{p-1}}&\rho^{{p-2}}&\dots&1\end{array}\right).](wyklady/ekn/mi/mi867.png) |
Krok 4.
Ergodyczność.
Dla ![]() wektor
wektor ![]() ma
ma ![]() -wymiarowy rozkład normalny
-wymiarowy rozkład normalny
gdzie macierz ![]() otrzymujemy z macierzy
otrzymujemy z macierzy ![]() przez wycięcie kolumn i wierszy od
przez wycięcie kolumn i wierszy od ![]() -giego do
-giego do ![]() -ego.
-ego.
gdzie ![]() macierz
macierz ![]() nie zależy od
nie zależy od ![]() ,
, ![]()
![A=\left(\begin{array}[]{ccccc}\rho^{{m}}&\rho^{{m+1}}&\rho^{{m+2}}&\dots&\rho^{{m+l}}\\
\rho^{{m-1}}&\rho^{{m}}&\rho^{{m+1}}&\dots&\rho^{{m+l-1}}\\
\dots&\dots&\dots&\dots&\dots\\
\rho^{{1}},&\rho^{{2}}&\rho^{{3}}&\dots&\rho^{{l+1}}\\
{1},&\rho^{{1}}&\rho^{{2}}&\dots&\rho^{{l}}\end{array}\right).](wyklady/ekn/mi/mi822.png) |
Zatem
W oparciu o powyższą granicę pokażemy własność mieszania.
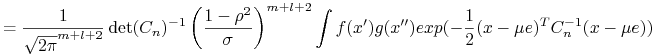 |
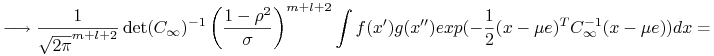 |
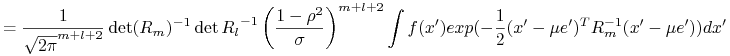 |
8.4. Martyngały i przyrosty martyngałowe
Definicja 8.10
![]() -wymiarowy proces stochastyczny
-wymiarowy proces stochastyczny ![]() nazywamy martyngałem gdy
nazywamy martyngałem gdy
Definicja 8.11
![]() -wymiarowy proces stochastyczny
-wymiarowy proces stochastyczny ![]() nazywamy ciągiem przyrostów martyngałowych gdy
nazywamy ciągiem przyrostów martyngałowych gdy
Uwaga 8.8
Jeśli proces ![]() jest martyngałem, to proces
jest martyngałem, to proces ![]() , gdzie
, gdzie
jest ciągiem przyrostów martyngałowych.
Uwaga 8.9
Jeśli proces ![]() jest ciągiem przyrostów martyngałowych a
jest ciągiem przyrostów martyngałowych a ![]() dowolną stałą, to proces
dowolną stałą, to proces ![]() , gdzie
, gdzie
jest martyngałem.
Lemat 8.3
Jeśli proces ![]() jest ciągiem przyrostów martyngałowych i
jest ciągiem przyrostów martyngałowych i ![]() należą do
należą do ![]() to są one nieskorelowane
to są one nieskorelowane
Dowód.
Zapiszemy wektory ![]() i
i ![]() ,
, ![]() , jako wektory kolumnowe.
, jako wektory kolumnowe.
![]() zatem
zatem
Przykład
Biały szum ![]() jest ciągiem przyrostów martyngałowych, a błądzenie przypadkowe czyli proces
jest ciągiem przyrostów martyngałowych, a błądzenie przypadkowe czyli proces
![]()
jest martyngałem.
Twierdzenie 8.6
Centralne Twierdzenie Graniczne ([2] Twierdzenie 23.1).
Jeśli stacjonarny i ergodyczny proces ![]() jest ciągiem przyrostów martyngałowych i
jest ciągiem przyrostów martyngałowych i ![]() należą do
należą do ![]() , to
, to
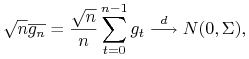 |
gdzie ![]() .
.
Uwaga 8.10
Powyższe twierdzenie jest uogólnieniem CTG Linderberga-Levy'ego, w którym pominięta została niezależnośc składników.


