Zagadnienia
1. Zagadnienie własne I
Cztery początkowe wykłady poświęcimy zagadnieniu własnemu. Naszym zadaniem będzie obliczenie, a raczej numeryczna aproksymacja wartości własnych danej macierzy kwadratowej (jednej, kilku, lub wszystkich). W ogólniejszym sformułowaniu możemy chcieć obliczyć również odpowiednie wektory własne.
Pierwszy wykład będzie dotyczyć przede wszystkim wrażliwości wartości i wektorów własnych na zaburzenia macierzy. Jak wiemy z podstawowego wykładu analizy numerycznej, jest to istotne z punktu widzenia numerycznej jakości algorytmów.
1.1. Podstawy teoretyczne
Zaczniemy od przypomnienia podstawowych pojęć i faktów z algebry liniowej dotyczących zagadnienia własnego, z których skorzystamy w dalszej części wykładu.
Definicja 1.1
Liczbę ![]() (zespoloną) nazywamy wartością
własną macierzy kwadratowej
(zespoloną) nazywamy wartością
własną macierzy kwadratowej ![]() jeśli istnieje
niezerowy wektor
jeśli istnieje
niezerowy wektor ![]() taki, że
taki, że
Wektor ![]() nazywamy wektorem własnym
odpowiadającym wartości własnej
nazywamy wektorem własnym
odpowiadającym wartości własnej ![]() .
.
Równoważnie, ![]() jest wartością własną macierzy
jest wartością własną macierzy ![]() gdy jest zerem jej wielomianu charakterystycznego, tzn. gdy
wyznacznik
gdy jest zerem jej wielomianu charakterystycznego, tzn. gdy
wyznacznik
gdzie ![]() jest macierzą identycznościową
jest macierzą identycznościową ![]() .
Krotnością algebraiczną wartości własnej
.
Krotnością algebraiczną wartości własnej ![]() nazywamy jej krotność jako zera wielomianu charakterystycznego.
nazywamy jej krotność jako zera wielomianu charakterystycznego.
Zbiór wszystkich wektorów własnych odpowiadających danej
wartości własnej ![]() , uzupełniony o wektor zerowy,
czyli zbiór
, uzupełniony o wektor zerowy,
czyli zbiór ![]() ,
jest podprzestrzenią liniową
,
jest podprzestrzenią liniową ![]() zwaną podprzestrzenią
własną odpowiadającą
zwaną podprzestrzenią
własną odpowiadającą ![]() . Wymiar tej podprzestrzeni
to krotność geometryczna wartości własnej
. Wymiar tej podprzestrzeni
to krotność geometryczna wartości własnej ![]() .
.
Wektory własne odpowiadające różnym wartościom własnym są liniowo niezależne.
Macierze ![]() są podobne gdy istnieje
nieosobliwa macierz
są podobne gdy istnieje
nieosobliwa macierz ![]() taka, że
taka, że ![]() .
Oczywiście, relacja ,,bycia macierzami podobnymi” jest symetryczna.
.
Oczywiście, relacja ,,bycia macierzami podobnymi” jest symetryczna.
Macierze podobne mają te same wartości własne. Jeśli bowiem
![]() to
to ![]() ,
tzn.
,
tzn. ![]() jest wartością własną
jest wartością własną ![]() , a odpowiadający
jej wektor własny to
, a odpowiadający
jej wektor własny to ![]() .
.
Macierz ![]() jest diagonalizowalna gdy jest podobna
do macierzy diagonalnej, czyli gdy istnieje nieosobliwa
jest diagonalizowalna gdy jest podobna
do macierzy diagonalnej, czyli gdy istnieje nieosobliwa
![]() taka, że
taka, że
Zauważmy, że wtedy możemy równoważnie zapisać
![]() , albo
, albo ![]() dla
dla
![]() . Stąd elementy diagonalne macierzy
. Stąd elementy diagonalne macierzy ![]() są wartościami własnymi macierzy
są wartościami własnymi macierzy ![]() (gdzie ta sama wartość
własna powtarza się tyle razy ile wynosi jej krotność),
a kolumny macierzy
(gdzie ta sama wartość
własna powtarza się tyle razy ile wynosi jej krotność),
a kolumny macierzy ![]() są odpowiednimi wektorami własnymi.
są odpowiednimi wektorami własnymi.
Szczególne własności mają macierze hermitowskie albo,
w przypadku rzeczywistym, macierze symetryczne, bowiem dla
nich istnieją bazy ortonormalne (odpowiednio w ![]() lub
lub ![]() )
wektorów własnych. Odpowiednie twierdzenie przypominamy jedynie
w przypadku rzeczywistym, który ma zasadnicze znaczenie
w obliczeniach praktycznych.
)
wektorów własnych. Odpowiednie twierdzenie przypominamy jedynie
w przypadku rzeczywistym, który ma zasadnicze znaczenie
w obliczeniach praktycznych.
Twierdzenie 1.1
Niech ![]() będzie macierzą symetryczną o współczynnikach
rzeczywistych,
będzie macierzą symetryczną o współczynnikach
rzeczywistych,
Wtedy istnieje w ![]() baza ortonormalna wektorów własnych
macierzy
baza ortonormalna wektorów własnych
macierzy ![]() , tzn. istnieje układ wektorów własnych
, tzn. istnieje układ wektorów własnych
![]() taki, że
taki, że
Oczywiście, odpowiednie wartości własne ![]() ,
,
![]() , są też rzeczywiste.
, są też rzeczywiste.
Powyższa własność macierzy symetrycznych oznacza tyle, że są one diagonalizowalne przy pomocy macierzy ortogonalnych. Rzeczywiście, oznaczając
mamy ![]() oraz
oraz
1.2. Teoria zaburzeń dla macierzy niesymetrycznych
Zobaczmy najpierw, czy mamy w ogóle szansę numerycznego rozwiązania zadania znalezienia wartości własnych macierzy. W tym celu zbadamy jego uwarunkowanie, czyli wrażliwość na małe względne zaburzenia współczynników macierzy.
1.2.1. Wstępny przykład
W ogólności, uwarunkowanie naszego zadania może być niestety dowolnie duże.
Przykład 1.1
Niech macierz
![J_{\varepsilon}\,:=\,\left[\begin{array}[]{ccccc}\mu&1&0&\cdots&0\\
0&\mu&1&&\vdots\\
\vdots&&\ddots&\ddots&0\\
0&&&\mu&1\\
\varepsilon&0&\cdots&0&\mu\end{array}\right]\,\in\,\mathbb{C}^{{n,n}}.](wyklady/mo2/mi/mi172.png) |
Dla ![]() , macierz
, macierz ![]() jest pojedynczą klatką Jordana,
której jedyną wartością własną jest
jest pojedynczą klatką Jordana,
której jedyną wartością własną jest ![]() (o krotności algebraicznej
(o krotności algebraicznej
![]() i krotności geometrycznej
i krotności geometrycznej ![]() ). Jeśli teraz zaburzymy wyraz w lewym
dolnym rogu o
). Jeśli teraz zaburzymy wyraz w lewym
dolnym rogu o ![]() to otrzymana macierz
to otrzymana macierz ![]() ma już
ma już
![]() różnych wartości własnych. Rzeczywiście,
jej wielomian charakterystyczny
różnych wartości własnych. Rzeczywiście,
jej wielomian charakterystyczny
ma pierwiastki
Względne zaburzenie macierzy na poziomie ![]() powoduje więc
względne zaburzenie wartości własnych na poziomie
powoduje więc
względne zaburzenie wartości własnych na poziomie ![]() .
Stąd, dla
.
Stąd, dla ![]() , uwarunkowanie rośnie do
, uwarunkowanie rośnie do
![]() gdy
gdy ![]() .
.
Oczywiście, otrzymane oszacowanie nie oznacza, że w powyższym
przykładzie w ogóle nie potrafimy aproksymować wartości własnej.
Tracimy jednak na liczbie poprawnie obliczonych cyfr znaczących wyniku.
Niech ![]() . Wtedy przy dokładności arytmetyki
. Wtedy przy dokładności arytmetyki ![]() możemy
spodziewać się jedynie wyniku z dokładnością do czterech cyfr
znaczących, a przy dokładności
możemy
spodziewać się jedynie wyniku z dokładnością do czterech cyfr
znaczących, a przy dokładności ![]() z dokładnością do
ośmiu cyfr znaczących. Co więcej, im większy format
z dokładnością do
ośmiu cyfr znaczących. Co więcej, im większy format ![]() klatki
Jordana tym gorzej.
klatki
Jordana tym gorzej.
Powyższy przykład pokazuje również, że praktycznie niemożliwe jest numeryczne wyznaczenie struktury macierzy. Nawet drobne zaburzenie macierzy powoduje bowiem, że pojedyncza klatka Jordana staje się macierzą diagonalizowalną.
1.2.2. Wrażliwość wartości własnych
Dalej będziemy już zakładać, że macierz ![]() jest diagonalizowalna,
czyli że jej postać Jordana jest macierzą diagonalną.
Wtedy mamy następujące oszacowanie Bauera-Fike'a.
jest diagonalizowalna,
czyli że jej postać Jordana jest macierzą diagonalną.
Wtedy mamy następujące oszacowanie Bauera-Fike'a.
Twierdzenie 1.2
Niech ![]() będzie macierzą diagonalizowalną
o wartościach własnych
będzie macierzą diagonalizowalną
o wartościach własnych ![]() ,
, ![]() ,
,
Niech dalej ![]() będzie dowolną wartością własną macierzy
`sąsiedniej'
będzie dowolną wartością własną macierzy
`sąsiedniej' ![]() . Wtedy
. Wtedy
gdzie ![]() oraz
oraz ![]() jest normą
macierzy indukowaną przez dowolną normę
jest normą
macierzy indukowaną przez dowolną normę ![]() -tą wektora.
-tą wektora.
Dowód
Załóżmy bez zmniejszenia ogólności, że ![]() jest różne od każdej
wartości własnej
jest różne od każdej
wartości własnej ![]() .
Niech
.
Niech ![]() będzie wektorem własnym odpowiadającym wartości
własnej
będzie wektorem własnym odpowiadającym wartości
własnej ![]() macierzy
macierzy ![]() . Wtedy
. Wtedy
| (1.1) |
Oznaczając ![]() mamy dalej
mamy dalej
| (1.2) |
czyli
Ponieważ
![]() to ostatecznie
to ostatecznie
Dla macierzy diagonalizowalnych zaburzenia wartości własnych są więc
lipschitzowską funkcją zaburzeń macierzy, przy czym stała Lipschitza
wynosi ![]() .
.
Podane oszacowanie jest globalne dla wszystkich wartości własnych.
Zaburzenia macierzy ![]() mogą jednak w różny sposób przenosić się
na zaburzenia różnych wartości własnych. Od czego to zależy?
Tak jak w dowodzie twierdzenia Bauera-Fike'a, niech
mogą jednak w różny sposób przenosić się
na zaburzenia różnych wartości własnych. Od czego to zależy?
Tak jak w dowodzie twierdzenia Bauera-Fike'a, niech
Biorąc jedynie ![]() -tą współrzędną po obu stronach
równania (1.2) dostajemy
-tą współrzędną po obu stronach
równania (1.2) dostajemy
| (1.3) |
gdzie ![]() jest znormalizowaną
jest znormalizowaną ![]() -tą kolumną macierzy
-tą kolumną macierzy
tzn. ![]() .
W szczególności,
.
W szczególności, ![]() oraz
oraz
(ortogonalność ze względu na zwykły iloczyn skalarny).
Stąd, jeśli ![]() i
i ![]() nie są ortogonalne to
nie są ortogonalne to
Dla ustalenia uwagi załóżmy teraz, że minimum w twierdzeniu
1.2 jest osiągane dla ![]() , a podprzestrzenią własną
wartości własnej
, a podprzestrzenią własną
wartości własnej ![]() jest
jest
gdzie wektory własne ![]() tworzą bazę
ortonormalną w
tworzą bazę
ortonormalną w ![]() . Jeśli wektor
. Jeśli wektor ![]() jest
`dostatecznie blisko' podprzestrzeni własnej
jest
`dostatecznie blisko' podprzestrzeni własnej ![]() (co, jak pokażemy w następnym podrozdziale, jest prawdą dla
dostatecznie małego zaburzenia
(co, jak pokażemy w następnym podrozdziale, jest prawdą dla
dostatecznie małego zaburzenia ![]() ) to
) to ![]() można
w przybliżeniu oszacować z góry przez maksymalną wartość
wyrażenia
można
w przybliżeniu oszacować z góry przez maksymalną wartość
wyrażenia
po wszystkich ![]() takich, że
takich, że ![]() .
Niech więc
.
Niech więc ![]() ,
przy czym
,
przy czym ![]() .
Wobec tego, że dla każdego
.
Wobec tego, że dla każdego ![]() mamy
mamy
interesujące nas `max' jest najmniejsze gdy
![]() .
Stąd dostajemy
.
Stąd dostajemy
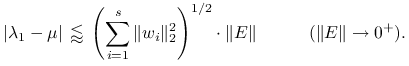 |
Ponieważ ![]() oraz
oraz ![]() jest ortogonalny do
jest ortogonalny do ![]() , otrzymana
nierówność sugeruje, że wartość własna
, otrzymana
nierówność sugeruje, że wartość własna ![]() może
być bardzo wrażliwa na zaburzenia macierzy gdy odpowiadająca
jej podprzestrzeń własna
może
być bardzo wrażliwa na zaburzenia macierzy gdy odpowiadająca
jej podprzestrzeń własna
![]() jest `prawie ortogonalna' do
jest `prawie ortogonalna' do
![]() .
Dobrze ilustruje to następujący przykład.
.
Dobrze ilustruje to następujący przykład.
Przykład 1.2
Rozpatrzmy macierz
gdzie ![]() jest `małe'. Wartości własne
jest `małe'. Wartości własne ![]() wynoszą
wynoszą ![]() i
i ![]() ,
natomiast wektory własne
,
natomiast wektory własne ![]() i
i ![]() są prawie
liniowo zależne. Zaburzając macierz przez dodanie
są prawie
liniowo zależne. Zaburzając macierz przez dodanie ![]() do wyrazu w lewym dolnym rogu dostajemy macierz o wartościach
własnych
do wyrazu w lewym dolnym rogu dostajemy macierz o wartościach
własnych ![]() i
i ![]() , a odpowiadające im wektory własne wynoszą
, a odpowiadające im wektory własne wynoszą
![]() i
i ![]() . Dodajmy, że w tym przypadku
. Dodajmy, że w tym przypadku
![]() jest proporcjonalne do
jest proporcjonalne do ![]() .
.
1.2.3. Wrażliwość wektorów własnych
Przez zaburzenie wektora własnego będziemy rozumieć odległość
wektora ![]() od podprzestrzeni własnej
od podprzestrzeni własnej ![]() , tzn.
, tzn.
albo, równoważnie, długość rzutu ortogonalnego ![]() wektora
wektora ![]() na podprzestrzeń
na podprzestrzeń
Pokażemy, że podobnie jak przypadku wartości własnych, zaburzenie
wektorów własnych jest lipszitzowską funkcją ![]() .
W tym celu, wybierzmy w
.
W tym celu, wybierzmy w ![]() dowolną bazę
ortonormalną
dowolną bazę
ortonormalną
Niech ![]() będzie macierzą przejścia z bazy
będzie macierzą przejścia z bazy
![]() do
do ![]() ,
,
Wtedy
Wobec równości (1.3) mamy
Ponieważ na podstawie twierdzenia Bauera-Fike'a mamy
otrzymujemy następującą przybliżoną nierówność
| (1.4) |
Uwaga. W przykładzie 1.2 istotnemu zaburzeniu uległy
wartości własne, natomiast wektory własne nie. Jest to
zrozumiałe w świetle ostatniego wyniku. W przypadku macierzy
![]() mamy bowiem
mamy bowiem ![]() i w konsekwencji wrażliwość
wektorów własnych zależy tylko od różnicy
i w konsekwencji wrażliwość
wektorów własnych zależy tylko od różnicy ![]() .
.
Poniższy przykład dla macierzy symetrycznej (!) pokazuje jak ważne dla wrażliwości wektorów własnych jest odseparowanie różnych wartości własnych.
Przykład 1.3
Wartościami własnymi macierzy symetrycznej
są ![]() i
i ![]() , a odpowiadająca baza wektorów własnych
to
, a odpowiadająca baza wektorów własnych
to ![]() i
i ![]() . Dla macierzy zaburzonej na poziomie
. Dla macierzy zaburzonej na poziomie
![]() (czyli różnicy wartości własnych),
(czyli różnicy wartości własnych),
wartościami własnymi są ![]() i
i ![]() ,
a bazę wektorów własnych tworzą
,
a bazę wektorów własnych tworzą ![]() i
i ![]() . Baza wektorów własnych została obrócona
o możliwie maksymalny kąt
. Baza wektorów własnych została obrócona
o możliwie maksymalny kąt ![]() .
.
1.3. Teoria zaburzeń dla macierzy symetrycznych
W tej części będziemy zakładać, że macierz jest rzeczywista i symetryczna,
Ponieważ elementy ![]() i
i ![]() macierzy
macierzy ![]() są
w praktycznych obliczeniach reprezentowane przez tą samą zmienną,
zasadne jest założenie, że macierz zaburzona
są
w praktycznych obliczeniach reprezentowane przez tą samą zmienną,
zasadne jest założenie, że macierz zaburzona ![]() jest
również symetryczna,
jest
również symetryczna, ![]() .
.
1.3.1. Wrażliwość wartości własnych
Przypomnijmy twierdzenie 1.1, które mówi, że dla macierzy
symetrycznej istnieje baza ortonormalna ![]() jej wektorów własnych.
Ponieważ dla macierzy ortogonanych mamy
jej wektorów własnych.
Ponieważ dla macierzy ortogonanych mamy ![]() ,
,
To zaś, razem z twierdzeniem 1.2 implikuje, że każda
watość własna ![]() macierzy sąsiedniej
macierzy sąsiedniej ![]() spełnia nierówność
spełnia nierówność
Możemy jednak pokazać dużo więcej. Zachodzi bowiem następujące twierdzenie Weyla.
Twierdzenie 1.3
Niech ![]() będą wartościami
własnymi macierzy
będą wartościami
własnymi macierzy ![]() , a
, a
![]() wartościami własnymi macierzy
sąsiedniej
wartościami własnymi macierzy
sąsiedniej ![]() , gdzie
, gdzie ![]() . Wtedy dla wszystkich
. Wtedy dla wszystkich
![]() mamy
mamy
Dowód twierdzenia opiera się na następującej pożytecznej nierówności.
Lemat 1.1
Dla dowolnej rzeczywistej macierzy symetrycznej ![]() mamy
mamy
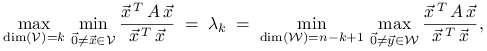 |
(1.5) |
przy czym odpowiednie maksimum i minimum osiągane są dla
![]() oraz
oraz
![]() .
.
Dowód
Niech ![]() i
i ![]() będą dowolnymi podprzestrzeniami
o wskazanych wymiarach. Ponieważ suma wymiarów wynosi
będą dowolnymi podprzestrzeniami
o wskazanych wymiarach. Ponieważ suma wymiarów wynosi ![]() to
istnieje wektor niezerowy
to
istnieje wektor niezerowy ![]() .
W konsekwencji
.
W konsekwencji
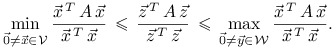 |
Biorąc maximum po ![]() i minimum po
i minimum po ![]() dostajemy,
że w (1.5) lewa strona nie jest większa od prawej.
Aby pokazać odwrotną nierówność, zauważmy,
że dla
dostajemy,
że w (1.5) lewa strona nie jest większa od prawej.
Aby pokazać odwrotną nierówność, zauważmy,
że dla ![]() i
i ![]() mamy odpowiednio
mamy odpowiednio
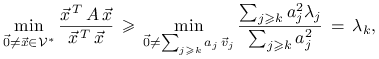 |
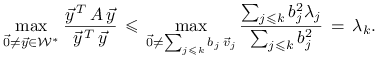 |
Dla dowodu twierdzenia 1.3 zastosujemy
lemat 1.5 najpierw do macierzy ![]() ,
a potem do macierzy
,
a potem do macierzy ![]() . Otrzymujemy odpowiednio
. Otrzymujemy odpowiednio
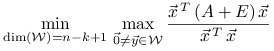 |
||||
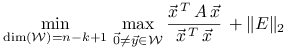 |
||||
oraz podobnie nierówność odwrotną
![]() , czyli ostatecznie
, czyli ostatecznie
Zanotujmy jeszcze, że wielkość
znana jest pod nazwą ilorazu Rayleigh'a.
1.3.2. Wrażliwość wektorów własnych
Niech ![]() będzie podprzestrzenią własną
odpowiadającą wartości własnej
będzie podprzestrzenią własną
odpowiadającą wartości własnej ![]() macierzy
macierzy ![]() , a
, a
![]() wektorem własnym odpowiadającym wartości
własnej
wektorem własnym odpowiadającym wartości
własnej ![]() macierzy sąsiedniej
macierzy sąsiedniej ![]() . Niech dalej
. Niech dalej
![]() będzie kątem pomiędzy
będzie kątem pomiędzy ![]() i podprzestrzenią
i podprzestrzenią
![]() . Wtedy
. Wtedy
Rzeczywiście, to wynika bezpośrednio z twierdzenia 1.3,
nierówności (1.4) oraz faktu, że macierz ![]() w (1.4) jest identycznością.
Pokażemy teraz nierówność dokładną.
w (1.4) jest identycznością.
Pokażemy teraz nierówność dokładną.
Twierdzenie 1.4
Dowód
Dla ustalenia uwagi załóżmy, że ![]() oraz odpowiednia
podprzestrzeń własna
oraz odpowiednia
podprzestrzeń własna
![]() .
Przedstawmy wektor własny
.
Przedstawmy wektor własny ![]() ,
, ![]() ,
w jednoznaczny sposób w postaci
,
w jednoznaczny sposób w postaci
gdzie ![]() i
i ![]() ,
,
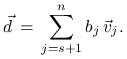 |
Możemy też założyć, bez straty ogólności, że ![]() i
i ![]() , tzn.
, tzn. ![]() .
.
Przekształcając równanie
![]() dostajemy
dostajemy
Ponieważ każdy z wektorów ![]() dla
dla ![]() należy
do jądra macierzy symetrycznej
należy
do jądra macierzy symetrycznej ![]() to
wektor
to
wektor ![]() jest ortogonalny do
jest ortogonalny do ![]() i tym samym możemy zapisać
i tym samym możemy zapisać
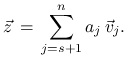 |
Mamy dalej
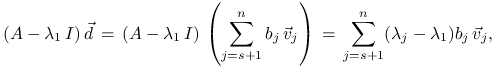 |
a stąd ![]() i
i
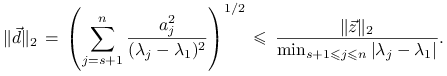 |
Z kolei z równości
![]() dostajemy
dostajemy
skąd
Gdybyśmy teraz wiedzieli, że
| (1.6) |
to moglibyśmy napisać
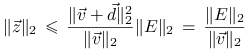 |
i ostatecznie
Pozostaje więc do pokazania równość (1.6).
W tym celu, weźmy ![]() ,
gdzie
,
gdzie ![]() ,
, ![]() i
i
![]() . Wtedy
. Wtedy
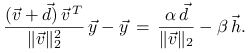 |
Dla danych ![]() i
i ![]() , wektor po prawej stronie ma największą
normę gdy
, wektor po prawej stronie ma największą
normę gdy ![]() , przy czym bierzemy plus
wtedy i tylko wtedy gdy
, przy czym bierzemy plus
wtedy i tylko wtedy gdy ![]() i
i ![]() mają różne znaki.
Dlatego poszukiwana norma wynosi
mają różne znaki.
Dlatego poszukiwana norma wynosi
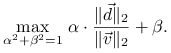 |
Zamieniając zmienne na ![]() ,
, ![]() łatwo
dostajemy, że optymalne
łatwo
dostajemy, że optymalne ![]() spełnia
spełnia
![]() ,
, ![]() , a stąd
dostajemy wynik
, a stąd
dostajemy wynik
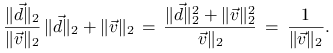 |
Pokazaliśmy, że wektory własne są mało wrażliwe na zaburzenia
macierzy o ile wartości własne są odseparowane od siebie
na poziomie dużo większym niż ![]() . W szczególności, jeśli
dodatkowo
. W szczególności, jeśli
dodatkowo ![]() ,
, ![]() , to mamy jednolite oszacowanie
, to mamy jednolite oszacowanie
Przypomnijmy jeszcze przykład 1.3 pokazujący, że warunek odseparowania wartości własnych jest konieczny.


