Zagadnienia
9. Układy równań nieliniowych. Metoda Newtona
Zajmiemy się teraz nową, trudniejszą klasą zadań: metodami rozwiązywania układów równań nieliniowych
gdzie ![]() .
.
W matematyce stosowanej bardzo wiele modeli zyskuje na realizmie, gdy uwzględnić w nich zjawiska nieliniowe. Takie modele są jednak znacznie trudniejsze — zarówno w analizie, jak i w komputerowych symulacjach. Nieustanny wzrost mocy obliczeniowej komputerów, jaki obserwujemy w ciągu ostatnich kilkudziesięciu lat powoduje, że rozwiązywanie dużych układów nawet silnie nieliniowych równań stało się możliwe nawet dla posiadaczy ,,zwykłych” komputerów osobistych.
Od razu zauważmy, że już na poziomie matematycznej poprawności tego zadania możemy napotkać kłopoty, albowiem to zadanie może nie mieć rozwiązań, może mieć dokładnie jedno rozwiązanie, albo skończenie wiele rozwiązań, albo nieskończenie wiele izolowanych rozwiązań, albo… i tak dalej, i tak dalej.
Aby więc szukać jakiegokolwiek rozwiązania powyższego równania, musimy najpierw mieć pewność, że ono istnieje. Nie będziemy się tą kwestią tu zajmować, traktując ją jako domenę matematyki czystej, bez numerycznego zacięcia.
Z kursu Matematyki obliczeniowej I znamy kilka metod rozwiązywania nieliniowego równania skalarnego, ![]() : metodę bisekcji, stycznych, siecznych, …. Okazuje się, że niektóre z nich da się w mniej lub bardziej naturalny sposób uogólnić na przypadek wielowymiarowy. W niniejszym rozdziale wyjaśnimy, jak metodę stycznych (Newtona) uogólnić na przypadek wielowymiarowy.
: metodę bisekcji, stycznych, siecznych, …. Okazuje się, że niektóre z nich da się w mniej lub bardziej naturalny sposób uogólnić na przypadek wielowymiarowy. W niniejszym rozdziale wyjaśnimy, jak metodę stycznych (Newtona) uogólnić na przypadek wielowymiarowy.
9.1. Szybkość zbieżności
Rozważmy ciąg ![]() taki, że
taki, że ![]() gdy
gdy ![]() .
.
Definicja 9.1 (Zbieżność wykładnicza)
Powiemy, że ![]() wykładniczo z rzędem co najmniej
wykładniczo z rzędem co najmniej ![]() , jeśli
, jeśli
| (9.1) |
Jeśli wykładnik zbieżności ![]() , mówimy wtedy o zbieżności kwadratowej; gdy
, mówimy wtedy o zbieżności kwadratowej; gdy ![]() , zbieżność nazywamy sześcienną (albo: kubiczną). W praktyce, zbieżność kwadratową uznaje się za satysfakcjonująco szybką, a zbieżność kubiczną — za bardzo szybką. Jednak nie zawsze taką szybkość zbieżności można uzyskać; rozsądnym praktycznym minimum jest zbieżność liniowa, w której błąd w każdym kroku maleje o stały czynnik:
, zbieżność nazywamy sześcienną (albo: kubiczną). W praktyce, zbieżność kwadratową uznaje się za satysfakcjonująco szybką, a zbieżność kubiczną — za bardzo szybką. Jednak nie zawsze taką szybkość zbieżności można uzyskać; rozsądnym praktycznym minimum jest zbieżność liniowa, w której błąd w każdym kroku maleje o stały czynnik:
Definicja 9.2 (Zbieżność liniowa)
Powiemy, że ![]() przynajmniej liniowo, jeśli
przynajmniej liniowo, jeśli
Jednak gdy ![]() , zbieżność liniowa może być w praktyce nieakceptowalnie wolna.
, zbieżność liniowa może być w praktyce nieakceptowalnie wolna.
Oczywiście powyższe nie wyczerpuje wszystkich możliwych szybkości zbieżności. Mianowicie, ciąg może być zbieżny szybciej niż liniowo (choć niekoniecznie zaraz kwadratowo):
Definicja 9.3 (Zbieżność superliniowa)
Powiemy, że ![]() superliniowo, jeśli
superliniowo, jeśli
Czasem trudno o samym ciągu powiedzieć, jaki ma wykładnik zbieżności, natomiast łatwiej jest wskazać ciąg o znanym wykładniku zbieżności, który majoryzuje błąd popełniany na każdej iteracji.
Definicja 9.4 (r–zbieżność)
Powiemy, że ![]() r–wykładniczo/r–liniowo/r–superliniowo, jeśli istnieje ciąg
r–wykładniczo/r–liniowo/r–superliniowo, jeśli istnieje ciąg ![]() taki, że
taki, że
oraz ![]() , odpowiednio, wykładniczo/liniowo/superliniowo.
, odpowiednio, wykładniczo/liniowo/superliniowo.
Aby móc porównywać (jakościowo) różne metody iteracyjne rozwiązywania równań nieliniowych — o różnych kosztach jednej iteracji i o różnych wykładnikach zbieżności — wprowadza się pojęcie wskaźnika efektywności metody.
Definicja 9.5 (Efektywność metody iteracyjnej)
Wskaźnik efektywności ![]() metody iteracyjnej, zbieżnej wykładniczo z wykładnikiem
metody iteracyjnej, zbieżnej wykładniczo z wykładnikiem ![]() , której jedna iteracja kosztuje
, której jedna iteracja kosztuje ![]() flopów, definiujemy jako [17]
flopów, definiujemy jako [17]
Wskaźnik efektywności metody służy szybkiemu jakościowemu porównywaniu metod. Motywacją dla takiej definicji jest wymaganie, by przy zadanym (tym samym) całkowitym koszcie iteracji ![]() obu metod, porównać uzyskane wykładniki redukcji błędu. Jeśli bowiem metoda jest rzędu
obu metod, porównać uzyskane wykładniki redukcji błędu. Jeśli bowiem metoda jest rzędu ![]() , to błąd początkowy po
, to błąd początkowy po ![]() iteracjach zostanie zredukowany do poziomu
iteracjach zostanie zredukowany do poziomu ![]() . Ponieważ całkowity koszt
. Ponieważ całkowity koszt ![]() iteracji wynosi
iteracji wynosi ![]() , to
, to ![]() .
Definiując w ten sposób efektywność metody iteracyjnej, czynimy jednak pewne oproszczenie, polegające na tym, że pomijamy wpływ stałych na redukcję błędu (patrz oszacowanie (9.1)). Z tego powodu na przykład (formalnie) każda metoda zbieżna liniowo formalnie miałaby taką samą efektywność — równą 1 — choć oczywiście realna sprawność różnych metod liniowych może być różna, m.in. właśnie w zależności od stałej redukcji błędu.
.
Definiując w ten sposób efektywność metody iteracyjnej, czynimy jednak pewne oproszczenie, polegające na tym, że pomijamy wpływ stałych na redukcję błędu (patrz oszacowanie (9.1)). Z tego powodu na przykład (formalnie) każda metoda zbieżna liniowo formalnie miałaby taką samą efektywność — równą 1 — choć oczywiście realna sprawność różnych metod liniowych może być różna, m.in. właśnie w zależności od stałej redukcji błędu.
Rozważmy dwa przykłady dużych układów równań nieliniowych, motywowanych — podobnie jak już kilka razy wcześniej w trakcie tego przedmiotu — zadaniami z równań różniczkowych cząstkowych.
Przykład 9.1 (stacjonarne równanie Allena–Cahna)
Rozważmy równanie
Dla uproszczenia przyjmiemy, że ![]() jest kwadratem jednostkowym. Wprowadzając dyskretyzację tego równania najprostszą11Po raz kolejny przypomnijmy, że (z wyjątkiem trywialnych przypadków) najprostsze metody dyskretyzacji, choć bardzo ułatwiają programowanie, to jednak są zwykle najmniej efektywnym sposobem rozwiązywania równań różniczkowych, jeśli wziąć pod uwagę koszt obliczeniowy potrzebny do uzyskania satysfakcjonującego przybliżenia rozwiązania. metodą — metodą różnic skończonych na jednorodnej siatce — patrz przykład 5.2 — otrzymujemy, po uwzględnieniu warunku brzegowego, nieliniowy układ równań algebraicznych,
jest kwadratem jednostkowym. Wprowadzając dyskretyzację tego równania najprostszą11Po raz kolejny przypomnijmy, że (z wyjątkiem trywialnych przypadków) najprostsze metody dyskretyzacji, choć bardzo ułatwiają programowanie, to jednak są zwykle najmniej efektywnym sposobem rozwiązywania równań różniczkowych, jeśli wziąć pod uwagę koszt obliczeniowy potrzebny do uzyskania satysfakcjonującego przybliżenia rozwiązania. metodą — metodą różnic skończonych na jednorodnej siatce — patrz przykład 5.2 — otrzymujemy, po uwzględnieniu warunku brzegowego, nieliniowy układ równań algebraicznych,
gdzie ![]() jest operatorem liniowym zdefiniowanym w przykładzie 5.2, natomiast dla zadanej macierzy
jest operatorem liniowym zdefiniowanym w przykładzie 5.2, natomiast dla zadanej macierzy ![]()
(Przypomnijmy, że dokonujemy tutaj utożsamienia macierzy ![]() z wektorem długości
z wektorem długości ![]() , ktorego elementami są kolejne wiersze macierzy.)
, ktorego elementami są kolejne wiersze macierzy.)
Przykład 9.2 (ewolucyjne równanie Allena–Cahna)
Rozważmy równanie
Dla uproszczenia przyjmiemy, że ![]() jest kwadratem jednostkowym. Wprowadzając dyskretyzację tego równania najprostszą metodą — metodą różnic skończonych na jednorodnej siatce po zmiennej przestrzennej oraz niejawnym schematem Eulera po zmiennej czasowej (patrz wykład z Numerycznych równań różniczkowych, otrzymujemy, po uwzględnieniu warunku brzegowego, nieliniowy układ równań algebraicznych z niewiadomą
jest kwadratem jednostkowym. Wprowadzając dyskretyzację tego równania najprostszą metodą — metodą różnic skończonych na jednorodnej siatce po zmiennej przestrzennej oraz niejawnym schematem Eulera po zmiennej czasowej (patrz wykład z Numerycznych równań różniczkowych, otrzymujemy, po uwzględnieniu warunku brzegowego, nieliniowy układ równań algebraicznych z niewiadomą ![]() ,
,
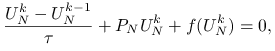 |
gdzie ![]() jest operatorem liniowym zdefiniowanym w przykładzie 5.2, a
jest operatorem liniowym zdefiniowanym w przykładzie 5.2, a ![]() jest zadane jak w poprzednim przykładzie. (Przypomnijmy, że dokonujemy tutaj utożsamienia macierzy
jest zadane jak w poprzednim przykładzie. (Przypomnijmy, że dokonujemy tutaj utożsamienia macierzy ![]() z wektorem długości
z wektorem długości ![]() , ktorego elementami są kolejne wiersze macierzy.)
Zostawiając po lewej stronie tylko wyrazy z niewiadomymi, dostajemy równanie
, ktorego elementami są kolejne wiersze macierzy.)
Zostawiając po lewej stronie tylko wyrazy z niewiadomymi, dostajemy równanie
a więc takie, w którym — dla dostatecznie małych ![]() — część nieliniowa staje się mała w porównaniu z
— część nieliniowa staje się mała w porównaniu z ![]() .
.
9.2. Metoda Banacha
Wiele równań nieliniowych można w naturalny sposób sformułować jako zagadnienie punktu stałego,
dla którego najprostszą metodą iteracyjną jest doskonale nam znana metoda Banacha (iteracji prostej),
Przypomnijmy (bez dowodu) twierdzenie o zbieżności tej metody:
Twierdzenie 9.1 (o zbieżności metody Banacha)
Niech ![]() będzie niepusty, ograniczony i domknięty, i niech
będzie niepusty, ograniczony i domknięty, i niech ![]() będzie kontrakcją, tzn.
będzie kontrakcją, tzn.
Wtedy ![]() ma dokładnie jeden punkt stały
ma dokładnie jeden punkt stały ![]() oraz dla dowolnego
oraz dla dowolnego ![]() iteracja
iteracja
jest zbieżna do ![]() , przy czym dla każdego
, przy czym dla każdego ![]() ,
,
Z powyższego twierdzenia wynika więc, że iteracja Banacha jest zbieżna przynajmniej liniowo ze współczynnikiem redukcji błędu ![]() .
.
Przykład 9.3
Stosując niejawny schemat Eulera12Por. np. wykład z Numerycznych równań różniczkowych. Podobna metoda — pod nazwą metody łamanych Eulera — bywa wykorzystywana w dowodzie twierdzenia o istnieniu rozwiązania równania różniczkowego. Nas tutaj interesuje ona wyłącznie jako metoda numeryczna.
do przybliżonego rozwiązania układu równań różniczkowych zwyczajnych ![]() musimy dla znanego
musimy dla znanego ![]() znaleźć
znaleźć ![]() jako punkt stały odwzorowania
jako punkt stały odwzorowania
Jeśli ![]() jest lipschitzowska ze stałą
jest lipschitzowska ze stałą ![]() w normie
w normie ![]() ze względu na drugi argument (por. twierdzenie Picarda–Lindelöfa), to
ze względu na drugi argument (por. twierdzenie Picarda–Lindelöfa), to
zatem ![]() jet kontrakcją na
jet kontrakcją na ![]() , gdy
, gdy ![]() , czyli gdy krok czasowy
, czyli gdy krok czasowy ![]() schematu Eulera jest dostatecznie mały względem
schematu Eulera jest dostatecznie mały względem ![]() .
.
Czasami wygodniej jest skorzystać z ,,lokalnej” wersji twierdzenia o zbieżności metody Banacha:
Twierdzenie 9.2 (o lokalnej zbieżności metody Banacha)
Niech ![]() , gdzie
, gdzie ![]() jest otwarty i niepusty, i niech dla zadanego
jest otwarty i niepusty, i niech dla zadanego ![]() istnieje kula
istnieje kula ![]() taka, że
taka, że ![]() oraz
oraz ![]() jest na
jest na ![]() kontrakcją ze stałą
kontrakcją ze stałą ![]() .
.
Jeśli dodatkowo ![]() , to w
, to w ![]() istnieje dokładnie jeden punkt stały
istnieje dokładnie jeden punkt stały ![]() odwzorowania
odwzorowania ![]() , a metoda iteracji prostej jest doń zbieżna przynajmniej liniowo ze stałą redukcji błędu
, a metoda iteracji prostej jest doń zbieżna przynajmniej liniowo ze stałą redukcji błędu ![]() .
.
Dowód
Wystarczy wykazać, że ![]() i skorzystać z poprzedniego twierdzenia. Na mocy warunku kontrakcji w
i skorzystać z poprzedniego twierdzenia. Na mocy warunku kontrakcji w ![]() , dla
, dla ![]() mamy
mamy
zatem faktycznie ![]() .
.
9.3. Metoda Newtona
W przypadku równania skalarnego, ![]() , metoda stycznych (zwana też metodą Newtona) rozwiązywania równania
, metoda stycznych (zwana też metodą Newtona) rozwiązywania równania ![]() jest zadana wzorem
jest zadana wzorem
Przez analogię, gdy ![]() można więc byłoby zdefiniować wielowymiarową metodę Newtona wzorem
można więc byłoby zdefiniować wielowymiarową metodę Newtona wzorem
| (9.2) |
gdzie ![]() oznaczałoby macierz pochodnej
oznaczałoby macierz pochodnej ![]() w punkcie
w punkcie ![]() . Jak za chwilę się przekonamy, jest to rzeczywiście bardzo dobry pomysł, a tak określona metoda zachowuje (z zachowaniem właściwych proporcji) wszystkie cechy metody Newtona znane nam z przypadku skalarnego!
. Jak za chwilę się przekonamy, jest to rzeczywiście bardzo dobry pomysł, a tak określona metoda zachowuje (z zachowaniem właściwych proporcji) wszystkie cechy metody Newtona znane nam z przypadku skalarnego!
9.3.1. Analiza zbieżności metody Newtona
Wielowymiarową metodę Newtona i różne jej warianty będziemy analizowali przy pewnych dość ogólnych założeniach dotyczących funkcji ![]() . W skrócie, będziemy je nazywali za [9] założeniami standardowymi:
. W skrócie, będziemy je nazywali za [9] założeniami standardowymi:
Zbiór
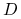 jest otwarty i niepusty, a
jest otwarty i niepusty, a 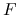 jest różniczkowalna w .
jest różniczkowalna w .Istnieje rozwiązanie
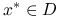 :
: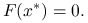
Pochodna
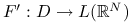 jest lipschitzowska ze stałą
jest lipschitzowska ze stałą 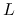 :
: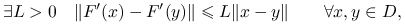
przy czym norma po lewej stronie nierówności jest normą operatorową indukowaną przez normę wektorową w
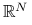 obecną po prawej stronie, tzn. dla liniowego operatora
obecną po prawej stronie, tzn. dla liniowego operatora 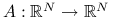 ,
,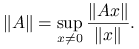
Macierz pochodnej w rozwiązaniu,
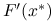 , jest nieosobliwa.
, jest nieosobliwa.
9.3.1.1. Lematy techniczne
Przez ![]() będziemy oznaczali kulę otwartą o środku w
będziemy oznaczali kulę otwartą o środku w ![]() i promieniu
i promieniu ![]() ,
,
Lemat 9.1 (użyteczna wersja twierdzenia o wartości średniej)
Niech będą spełnione założenia standardowe i niech ![]() będzie otwartą kulą w
będzie otwartą kulą w ![]() . Wtedy dla każdego
. Wtedy dla każdego ![]() ,
,
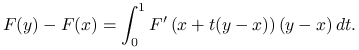 |
Dowód
Ustalmy ![]() . Ponieważ
. Ponieważ ![]() jest wypukły, to
jest wypukły, to ![]() dla
dla ![]() i dla
i dla ![]() jest dobrze określona funkcja
jest dobrze określona funkcja ![]() .
.
Na mocy założeń standardowych ![]() jest ciągła na
jest ciągła na ![]() , zatem także
, zatem także ![]() jest ciągła na
jest ciągła na ![]() (i całkowalna). Teza lematu wynika więc z podstawowego twierdzenia rachunku różniczkowego, że
(i całkowalna). Teza lematu wynika więc z podstawowego twierdzenia rachunku różniczkowego, że
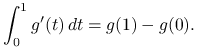 |
Lemat 9.2 (o lokalnym oszacowaniu funkcji i pochodnej)
Przy założeniach standardowych, istnieje dostatecznie małe ![]() takie, że dla dowolnego
takie, że dla dowolnego ![]() zachodzi:
zachodzi:
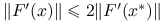 ,
,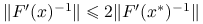 ,
,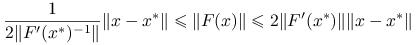 ,
,
Ćwiczenie 9.1
Wykaż, że przy założeniach standardowych ![]() musi być izolowanym rozwiązaniem równania
musi być izolowanym rozwiązaniem równania ![]() .
.
Z lematu 9.2 o oszacowaniu funkcji, istnieje otoczenie ![]() takie, że
takie, że
Jeśli więc dla ![]() leżącego w tym otoczeniu
leżącego w tym otoczeniu ![]() , to znaczyłoby to, że
, to znaczyłoby to, że ![]() , a więc
, a więc ![]() . Czyli w
. Czyli w ![]() nie ma innych rozwiązań niż
nie ma innych rozwiązań niż ![]() .
.
Twierdzenie 9.3 (o zbieżności metody Newtona)
Przy standardowych założeniach, istnieją ![]() (dostatecznie duże) i
(dostatecznie duże) i ![]() (dostatecznie małe) takie, że jeśli
(dostatecznie małe) takie, że jeśli ![]() , to ciąg
, to ciąg ![]() zadany metodą Newtona (9.2) jest dobrze określony,
zadany metodą Newtona (9.2) jest dobrze określony, ![]() , oraz
, oraz ![]() . Co więcej, ciąg ten jest zbieżny kwadratowo:
. Co więcej, ciąg ten jest zbieżny kwadratowo:
| (9.3) |
Dowód
Dowód będzie opierał się na wykazaniu oszacowania (9.3), pozostałe elementy tezy będą jego konsekwencją.
Na wstępie wybierzmy ![]() takie, by zachodził lemat 9.2 o oszacowaniu funkcji i pochodnej. Oznaczając
takie, by zachodził lemat 9.2 o oszacowaniu funkcji i pochodnej. Oznaczając ![]() mamy ze wzoru Newtona
mamy ze wzoru Newtona
Na mocy założeń standardowych i lematu o wartości średniej,
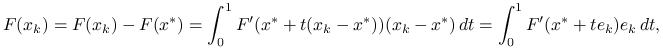 |
zatem
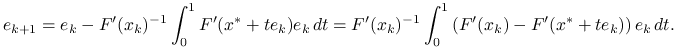 |
Korzystając z lipschitzowskości pochodnej i raz jeszcze z lematu 9.2 o oszacowaniu pochodnej, dostajemy
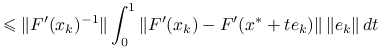 |
|||
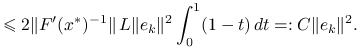 |
Stąd wynika, że jeśli ![]() oraz
oraz ![]() , to także
, to także ![]() , a więc ciąg
, a więc ciąg ![]() jest dobrze określony. Co więcej, gdy
jest dobrze określony. Co więcej, gdy ![]() to
to
a więc ciąg ![]() jest zbieżny (co najmniej liniowo — a w rzeczywistości co najmniej kwadratowo) do zera.
jest zbieżny (co najmniej liniowo — a w rzeczywistości co najmniej kwadratowo) do zera.
Ćwiczenie 9.2
Wykaż, że jeśli w założeniach standardowych zastąpić warunek lipschitzowskości pochodnej warunkiem
(czyli założyć, że ![]() jest w swej dziedzinie hölderowska z wykładnikiem
jest w swej dziedzinie hölderowska z wykładnikiem ![]() ), to metoda Newtona będzie lokalnie zbieżna z wykładnikiem zbieżności co najmniej
), to metoda Newtona będzie lokalnie zbieżna z wykładnikiem zbieżności co najmniej ![]() .
.
Wystarczy powielić dowód twierdzenia przy standardowych założeniach, modyfikując oszacowanie ![]() .
.
Ćwiczenie 9.3
Jak, przy założeniach standardowych, oszacować normę błędu, ![]() , przez normę residuum,
, przez normę residuum, ![]() ?
?
9.3.2. Implementacja metody Newtona
Implementując metodę Newtona, nie będziemy rzecz jasna nigdy explicite wyznaczali macierzy odwrotnej ![]() , tylko rozwiązywali układ równań z macierzą
, tylko rozwiązywali układ równań z macierzą ![]() — tę jednak będziemy już musieli wyznaczyć. Pamiętając także o tym, że metoda Newtona jest metodą iteracyjną, stosując ją będziemy musieli zadbać o postawienie sensownego kryterium zatrzymania metody. Odkładając na bok pytanie o konkretny warunek stopu (por. rozdział 7.5), możemy schematycznie zapisać algorytm realizujący metodę Newtona w następujący sposób:
— tę jednak będziemy już musieli wyznaczyć. Pamiętając także o tym, że metoda Newtona jest metodą iteracyjną, stosując ją będziemy musieli zadbać o postawienie sensownego kryterium zatrzymania metody. Odkładając na bok pytanie o konkretny warunek stopu (por. rozdział 7.5), możemy schematycznie zapisać algorytm realizujący metodę Newtona w następujący sposób:
Schemat metody Newtona
| function Newton(x, F, stop) |
| while not stop do begin |
| oblicz macierz pochodnej |
| rozwiąż |
| x = x - s; |
| end |
| return(x); |
Ćwiczenie 9.4
Macierzowe zadanie własne dla symetrycznej macierzy ![]() , znajdowania pary
, znajdowania pary ![]() spełniającej
spełniającej
można potraktować jako kwadratowe równanie nieliniowe dla ![]() danej na przykład wzorem
danej na przykład wzorem
Zdefiniuj metodę Newtona dla ![]() . Wykaż, że jeśli
. Wykaż, że jeśli ![]() jest jednokrotną wartością własną, to metoda Newtona dla
jest jednokrotną wartością własną, to metoda Newtona dla ![]() będzie lokalnie zbieżna kwadratowo.
będzie lokalnie zbieżna kwadratowo.
Mamy
Zatem metodę Newtona można — jeśli tylko ![]() nieosobliwa — zaimplementować, korzystając na przykład ze wzoru Shermana–Morrisona (por. ćwiczenie 5.23).
nieosobliwa — zaimplementować, korzystając na przykład ze wzoru Shermana–Morrisona (por. ćwiczenie 5.23).
Zauważmy, że ![]() jest funkcją gładką, jej pochodna jest lipschitzowska ze stałą Lipschitza równą… no właśnie, ile? Mamy
jest funkcją gładką, jej pochodna jest lipschitzowska ze stałą Lipschitza równą… no właśnie, ile? Mamy
zatem
A więc — w normie indukowanej normą ![]() —
— ![]() jest lipschitzowska ze stałą równą 1.
jest lipschitzowska ze stałą równą 1.
Pozostaje jeszcze sprawdzić, czy w rozwiązaniu — parze własnej ![]() — macierz pochodnej jest nieosobliwa. Ponieważ dla macierzy symetrycznej
— macierz pochodnej jest nieosobliwa. Ponieważ dla macierzy symetrycznej ![]() , gdzie
, gdzie ![]() jest macierzą diagonalną z wartościami własnymi macierzy
jest macierzą diagonalną z wartościami własnymi macierzy ![]() , a kolumny macierzy ortogonalnej
, a kolumny macierzy ortogonalnej ![]() są wektorami własnymi odpowiadającymi tym wartościom własnym, to
są wektorami własnymi odpowiadającymi tym wartościom własnym, to
Niech ![]() . Wtedy
. Wtedy ![]() dla pewnej stałej
dla pewnej stałej ![]() . Mamy więc, że
. Mamy więc, że ![]() jest macierzą diagonalną, która na diagonali ma zero jedynie na
jest macierzą diagonalną, która na diagonali ma zero jedynie na ![]() -tej pozycji (na mocy założenia, że
-tej pozycji (na mocy założenia, że ![]() jest pojedynczą wartością własną) oraz
jest pojedynczą wartością własną) oraz ![]() , gdzie
, gdzie ![]() oznacza
oznacza ![]() -ty wektor jednostkowy. Nietrudno sprawdzić wprost, że taka macierz jest pełnego rzędu.
-ty wektor jednostkowy. Nietrudno sprawdzić wprost, że taka macierz jest pełnego rzędu.
Ćwiczenie 9.5 (Metoda Schultza wyznaczania macierzy odwrotnej, [15])
Niech ![]() będzie macierzą nieosobliwą i rozważmy iterację
będzie macierzą nieosobliwą i rozważmy iterację
startującą z macierzy kwadratowej ![]() . Wykaż, że jeśli
. Wykaż, że jeśli ![]() , to
, to ![]() gdy
gdy ![]() .
.
Wykaż, że ![]() , a metoda jest w rzeczywistości metodą Newtona zastosowaną do równania macierzowego
, a metoda jest w rzeczywistości metodą Newtona zastosowaną do równania macierzowego ![]() .
.
Przykład 9.4 (Metoda Newtona dla równania Allena–Cahna)
Przypomnijmy (zob. przykład 9.1), że równanie nieliniowe, które nas interesuje w przypadku stacjonarnym ma postać
a w przypadku ewolucyjnym —
Oba przypadki możemy zatem ogarnąć, definiując funkcję
która dla ![]() i
i ![]() daje nam przypadek ewolucyjny, a dla
daje nam przypadek ewolucyjny, a dla ![]() i
i ![]() redukuje się do przypadku stacjonarnego równania Allena–Cahna.
redukuje się do przypadku stacjonarnego równania Allena–Cahna.
Wystarczy więc tylko wyznaczyć pochodną ![]() .
Ponieważ (traktując
.
Ponieważ (traktując ![]() jako funkcję na
jako funkcję na ![]() )
)
to
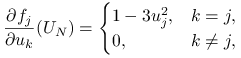 |
zatem ostatecznie
Przykład 9.5 (Numeryczne eksperymenty z metodą Newtona dla równania Allena–Cahna)
Dla uproszczenia, w eksperymentach numerycznych dotyczących działania różnych metod rozwiązywania równania Allena–Cahna opisywanego w przykładzie 9.1, będziemy rozważać dyskretyzacje jednowymiarowego stacjonarnego równania Allena–Cahna,
gdzie ![]() oraz
oraz ![]() .
.
Ćwiczenie 9.6
Przeprowadź podobne eksperymenty numeryczne dla równania Allena–Cahna w kwadracie, jak to opisywano we wcześniejszych przykładach.


