Zagadnienia
3. Podstawy C++: instrukcje
Podstawy C++: instrukcje
3.1. Historia C++
-
Algol 60 (13-to osobowy zespół, 1960-63).
-
Simula 67 (Ole-Johan Dahl, Bjorn Myhrhaug, Kristen Nygaard, Norweski Ośrodek Obliczeniowy w Oslo, 1967).
-
C (Dennis M. Ritchie, Bell Laboratories , New Jersey, 1972).
-
C z klasami (Bjarne Stroustrup, Bell Laboratories, New Jersey, 1979-80).
-
C++ (j.w., 1983).
-
Komisja X3J16 powołana do standaryzacji C++ przez ANSI (ANSI C++, 1990).
-
Standard C++ ISO/IEC 14882:1998, znany jako C++98 (1998).
-
Nowy standard C++0x (rok publikacji nadal nieznany).
Historia C++ sięga odległych czasów - Algolu 60, języka który stał się pierwowzorem dla większości współczesnych języków. Jednym z języków powstałych na bazie Algolu-60 była Simula-67, czyli pierwszy język obiektowy. Wydaje się, że Simula-67 wyprzedziła swoje czasy - idea obiektowości pod koniec lat 60-tych nie podbiła informatycznego świata. Tym nie mniej, idee rodzącego się paradygmatu programowania zaczęły przenikać do świata akademickiego, Simula-67 była używana do kształcenia studentów w niektórych krajach. Tak się złożyło, że jednym ze studentów informatyki, którzy mieli okazję poznać ten język był Duńczyk Bjarne Stroustrup. Gdy po studiach przeniósł się do Stanów Zjednoczonych i tam pracował programując w C, zauważył, że bardzo mu brakuje w pracy narzędzi znanych mu z Simuli. Postanowił dodać do C makropolecenia, które by pozwalały programować w C używając pojęć programowania obiektowego. Tak powstał język C z klasami. To rozwiązanie okazało się na tyle dobre, że szybko zdobyło popularność najpierw wśród znajomych Bjarne'a Stroustrupa, później krąg użytkowników znacznie się powiększył. Popularność tego rozwiązania zaowocowała stworzeniem pełnoprawnego (a więc nie będącego tylko zestawem makropoleceń do kompilatora innego języka) języka programowania C++. Nazwa pochodzi od operatora ++ występującego w C, oznaczającego zwiększanie wartości zmiennej. W ten sposób podkreślono, że ten nowy język jest rozszerzeniem języka C. Język C++ cały czas jest rozwijany. Obecna wersja standardu została zatwierdzona w 1998 roku. Na tej wersji oparty jest niniejszy wykład. Obecnie trwają prace nad nową wersją standardu języka, gdzie rozważa się wiele interesujących rozszerzeń, ale zakończenie tych prac opóźnia się i nie jest jasne, które z proponowanych rozszerzeń zostaną ostatecznie zaakceptowane.
3.2. Elementy C w C++
-
Uwaga: to nie jest opis języka C!
-
C++ jest kompilowanym językiem ze statycznie sprawdzaną zgodnością typów.
-
Program w C++ może się składać z wielu plików (zwykle pełnią one rolę modułów).
W tej części wykładu zajmujemy się nieobiektową częścią C++. Nie oznacza to, że ta część jest poświęcona opisowi języka C. Wprawdzie C++ powstało jako rozszerzenie języka C i zapewnia niemal pełną zgodność z tym językiem, to jednak wiele rzeczy zapisuje się w C++ inaczej niż w C (na przykład czytanie i wypisywanie). W naszym wykładzie zajmujemy się tylko językiem C++, zatem ignorujemy wszelkie konstrukcje C nieużywane w C++.
Zanim zaczniemy dokładnie opisywać poszczególne konstrukcje języka C++ podamy kilka podstawowych informacji o tym języku. C++ jest językiem kompilowanym, co oznacza, że każdy program, zanim zostanie uruchomiony, musi być przetłumaczony na język maszynowy za pomocą kompilatora. Takie rozwiązanie ma liczne zalety. Po pierwsze, kompilator jest w stanie podczas kompilacji wykryć (proste) błędy w programie - dzięki temu zwiększa się szansa na napisanie poprawnego programu. Po drugie, takie podejście pozwala na znacznie efektywniejsze wykonywanie programów.
C++ jest też językiem ze statyczną kontrolą typów. Oznacza to, że każda zmienna (parametr, funkcja itp.) musi być zadeklarowana przed użyciem, a jej deklaracja musi określać jej typ, czyli zbiór wartości, które może przyjmować. Takie podejście jest typowe dla języków kompilowanych i pozwala kompilatorowi wykrywać znacznie więcej błędów na etapie kompilacji (jak np. próba dodania liczby do napisu) oraz generować efektywniejszy kod.
Programy pisane na ćwiczeniach zwykle mieszczą się w jednym pliku. Oczywiście nie jest to typowe dla większych programów. Duże programy należy dzielić na mniejsze części, tak by móc łatwiej nimi zarządzać. Na przykład możemy podzielić pracę tak, by różne pliki były tworzone przez różnych programistów (to zresztą ma miejsce nawet w pozornie jedno-plikowych programach z zajęć, korzystają one przecież ze standardowych bibliotek). W C++ nie ma wprawdzie pojęcia modułu czy pakietu jak w wielu innych językach, ale można dowolnie dzielić tworzony program na pliki.
3.3. Notacja
-
Elementy języka (słowa kluczowe, separatory) zapisano są pismem prostym, pogrubionym (np. {).
-
Elementy opisujące konstrukcje języka zapisano pismem pochyłym, bez pogrubienia (np. wyrażenie).
-
Jeżeli dana konstrukcja może w danym miejscu wystąpić lub nie, to po jej nazwie jest napis
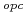 (umieszczony jako indeks).
(umieszczony jako indeks). -
Jeżeli dana konstrukcja może w danym miejscu wystąpić 0 lub więcej razy, to po jej nazwie jest napis
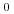 (umieszczony jako indeks).
(umieszczony jako indeks). -
Jeżeli dana konstrukcja może wystąpić w danym miejscu raz lub więcej razy, to po jej nazwie jest napis
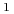 (umieszczony jako indeks).
(umieszczony jako indeks). -
Poszczególne wiersze odpowiadają poszczególnym wersjom omawianej konstrukcji składniowej.
Opisując poszczególne instrukcje C++ będziemy posługiwać się specjalną notacją, dość typową. Pozwala ona rozróżniać elementy języka od metaelementów oraz opisywać opcjonalność lub wielokrotne powtarzanie konstrukcji.
3.4. Instrukcje języka C++
Instrukcje języka programowania stanowią o tym, co da się w tym języku wyrazić. Zestaw instrukcji C++ jest dość typowy. Zamieszczamy tu informacyjnie listę wszystkich instrukcji, w dalszej części wykładu będziemy omawiać je szczegółowo.
| . | instrukcja: | |
| . | . | instrukcja_etykietowana |
| . | . | instrukcja_wyrażeniowa |
| . | . | blok |
| . | . | instrukcja_warunkowa |
| . | . | instrukcja_wyboru |
| . | . | instrukcja_pętli |
| . | . | instrukcja_deklaracyjna |
| . | . | instrukcja_próbuj |
| . | . | instrukcja_skoku |
3.4.1. Instrukcja wyrażeniowa
| . | instrukcja_wyrażeniowa: | |
| . | . |
-
Efektem jej działania są efekty uboczne wyliczania wartości wyrażenia (sama wartość po jej wyliczeniu jest ignorowana).
-
Zwykle instrukcjami wyrażeniowymi są przypisania i wywołania funkcji, np.:
i = 23*k +1;wypisz_dane(Pracownik); -
Szczególnym przypadkiem jest instrukcja pusta:
;
użyteczna np. do zapisania pustej treści instrukcji pętli.
Jest to jedna z najważniejszych instrukcji w C++. Spełnia rolę trzech różnych instrukcji z Pascala (pustej, przypisania i wywołania procedury)! A jednocześnie łatwo ją zapisać omyłkowo (aczkolwiek w pełni poprawnie składniowo) tak, by nic nie robiła. Przyjrzyjmy się jej więc dokładniej.
Najprostsza jej postać to sam średnik (przy pominiętym wyrażeniu). W tej postaci pełni rolę instrukcji pustej. Wbrew pozorom czasem instrukcja pusta bywa przydatna, na przykład przy zapisywaniu prostych pętli (pętle omówimy wkrótce).
// Wyszukanie pierwszego zera w tablicy t int i; for(i=0; i<n && t[i]!=0; i++) ;Ważne żeby zapamiętać, że w C++ instrukcja pusta nie jest pusta (składa się ze średnika).
Typowe zastosowanie instrukcji wyrażeniowej polega na zapisaniu w niej wyrażenia przypisania i zakończeniu go znakiem
średnika.
Wyliczenie takiej instrukcji polega na wyliczeniu wartości wyrażenia i … zignorowaniu tej wartości.
Kiedy to ma sens? Wtedy, gdy wyliczenie wyrażenia ma efekty uboczne. Podstawowym wyrażeniem, którego wyliczenie
ma efekt uboczny jest wyrażenie przypisujące. Na przykład i=0 jest takim wyrażeniem. Zrobienie z niego instrukcji wyrażeniowej jest bardzo proste - wystarczy dodać średnik.
i = 0;W C++ nie ma instrukcji przypisania, jest wyrażenie przypisujące. Nie jest to wielka różnica (wszak instrukcja wyrażeniowa zamienia dowolne wyrażenie na instrukcję), ale często wygodnie jest móc zapisać przypisanie jako wyrażenie. Wartością wyrażenia przypisującego jest przypisywana wartość. Zatem chcąc przypisać tę samą wartość do kilku zmiennych, można to zrobić w C++ jedną instrukcją:
i = j = k = 0;Inną sytuacją, gdy traktowanie przypisania jako wyrażenia jest wygodne, jest zapamiętywanie wartości użytej w warunku logicznym. Załóżmy, że operacja
getc() daje kolejny znak z wejścia, oraz że chcemy pominąć kolejne znaki odstępu i zapamiętać pierwszy, różny od odstępu znak. Możemy to zapisać tak:
while((c = getc()) != ' '); // Instrukcja pusta jako treść pętli
Trzecia ważna forma instrukcji wyrażeniowej służy wywołaniu funkcji, które chcemy traktować jako procedury. W C++ są tylko funkcje, nie ma procedur, ale nie ma też obowiązku odczytywania wartości wyniku funkcji, można więc wywołać funkcję jako procedurę. Co więcej można zadeklarować funkcję, która nie daje wyniku - czyli funkcję pełniącą rolę procedury. Załóżmy, że
mamy taką bezparametrową funkcję-procedurę o nazwie wypisz. Jej wywołanie można zapisać następująco:
wypisz();Efektem tej instrukcji wyrażeniowej będą efekty działania funkcji
wypisz.
Oczywiście nie każde wyrażenie warto zamieniać na instrukcję wyrażeniową. Oto całkowicie poprawny i całkowicie bezużyteczny przykład instrukcji wyrażeniowej - wyliczenie podanego tu wyrażenia nie ma żadnych efektów ubocznych, więc równie dobrze można by tu wstawić instrukcję pustą lub po prostu usunąć tę instrukcję.
13;Powszechnym błędem jest zapominanie o podaniu pustych nawiasów po nazwie wywoływanej funkcji bezargumentowej. Sama nazwa funkcji jest poprawnym wyrażeniem w C++ (jego wartością jest wskaźnik do funkcji), ale wyliczenie takiego wyrażenia nie daje żadnych efektów ubocznych, więc jest całkowicie bezużyteczne w instrukcji wyrażeniowej.
wypisz; // powinno być wypisz();Na szczęście większość kompilatorów generuje w takiej sytuacji ostrzeżenie.
Powiedziawszy o zaletach traktowania przypisania jako wyrażenia koniecznie musimy jednocześnie ostrzec o niebezpieczeństwach związanych ze stosowaniem efektów ubocznych. Choć sam język tego nie zabrania pamiętajmy, żeby nigdy nie nadużywać efektów ubocznych. Zilustrujemy to ostrzeżenie przykładami:
i = 1; t[i] = i = 0; // przypisanie 0 do t[1] czy t[0]? f(i=1,i=2); // jaką wartość ma i po wywołaniu funkcji f?
3.4.2. Instrukcja etykietowana
| . | instrukcja_etykietowana: | |
| . | . | identyfikator : instrukcja |
| . | . | case stałe_wyrażenie : instrukcja |
| . | . | default : instrukcja |
-
Pierwszy rodzaj instrukcji etykietowanej dotyczy instrukcji
gotoi nie będzie tu omawiany. -
Instrukcje etykietowane
caseidefaultmogą wystąpić jedynie wewnątrz instrukcji wyboru. -
Wyrażenie stałe stojące po etykiecie
casemusi być typu całkowitego.
Instrukcja etykietowana to po prostu dowolna instrukcja poprzedzona etykietą. Charakterystyczne dla C++ jest to, że owa etykieta może przyjąć jedną z kilku form.
Po pierwsze może być po prostu identyfikatorem. W tej postaci
instrukcja etykietowana służy jako wskazanie miejsca, do którego należy skoczyć w instrukcji goto (instrukcji skoku). Ponieważ instrukcja skoku jest powszechnie uważana za szkodliwą i od dawna nie występuje w nowych językach programowania
pomijamy ją (i tę postać instrukcji etykietowanej) w naszym wykładzie.
Druga i trzecia postać instrukcji etykietowanej dotyczy instrukcji wyboru (instrukcji oznaczonej w C++ słowem kluczowym switch). Dlatego omówienie tych instrukcji znajduje się w omówieniu instrukcji wyboru. Tu zaznaczmy tylko, że
obie te formy instrukcji etykietowanej mogą występować wyłącznie wewnątrz instrukcji wyboru, a wyrażenie stałe występujące
po słowie kluczowym case
3.4.3. Instrukcja złożona (blok)
| . | blok: | |
| . | . |
-
Służy do zgrupowania wielu instrukcji w jedną.
-
Nie ma żadnych separatorów oddzielających poszczególne instrukcje.
-
Deklaracja też jest instrukcją.
-
Instrukcja złożona wyznacza zasięg widoczności.
Instrukcja złożona (zwana czasem blokiem) służy do grupowania wielu instrukcji w jedną oraz do wyznaczania zasięgu deklaracji zmiennych. Grupowanie instrukcji jest często potrzebne ze względu na składnię języka, która w wielu miejscach (np. jako treść pętli) wymaga pojedynczej instrukcji. Jeśli chcemy w takim miejscu umieścić kilka (lub więcej) instrukcji, to musimy użyć instrukcji złożonej. Ta instrukcja jest pomocna także wówczas, gdy chcemy zadeklarować zmienną, która ma być widoczna tylko w najbliższym otoczeniu deklaracji.
Warto zwrócić uwagę, że składnia C++ nie wymaga żadnych separatorów pomiędzy poszczególnymi instrukcjami - każda instrukcja C++ kończy się średnikiem lub prawym nawiasem klamrowym, nie ma więc potrzeby stosowania dodatkowych separatorów. W instrukcji złożonej może występować dowolna liczba instrukcji składowych (w szczególności może ich być 0, ale nie jest to użyteczny przypadek).
Wykonanie instrukcji złożonej polega na wykonaniu po kolei instrukcji składowych (zostaną wykonane
wszystkie, o ile w czasie ich wykonywania nie pojawi się instrukcja zmieniająca przepływ sterowania
w programie - taka jak np. return;).
Ważne jest zauważenie, że w C++ deklaracja zmiennej (można również deklarować klasy, struktury,
wyliczenia lub nazywać typy za pomocą typedef ale te deklaracje zwykle są globalne)
też jest instrukcją. Czyli można zadeklarować zmienną lokalnie - wewnątrz bloku. Taka zmienna
jest widoczna od miejsca deklaracji do końca bloku. Jeśli przy deklaracji podano inicjalizator,
to przy zmiennych automatycznych będzie on wykonywany za każdym razem, gdy sterowanie dojdzie
do tej deklaracji, zaś dla zmiennych statycznych deklaracja zostanie wykonana tylko raz, przed
wejściem do bloku. Lokalnie zadeklarowana zmienna automatyczna jest niszczona, gdy sterowanie
opuszcza blok. Z powyższych rozważań wynika, że zmienne lokalne w bloku mogą być deklarowane
w dowolnym jego miejscu (nie koniecznie na początku, choć zwykle tak się dzieje).
Oczywiście nie można deklarować w jednym bloku dwu zmiennych o tej samej nazwie. Jeśli na zewnątrz bloku jest zadeklarowany identyfikator użyty w deklaracji lokalnej, to jest on przesłonięty od miejsca deklaracji do końca bloku. Oto przykład:
struct ff{int k;} f;
//...
f.k++; // poprawne
int f=f.k; // niedozwolone
f++; // poprawne
3.4.4. Instrukcja warunkowa
| . | instrukcja_warunkowa: | |
| . | . | if (warunek) instrukcja |
| . | . | if (warunek) instrukcja else instrukcja |
| . | warunek: | |
| . | . | wyrażenie |
-
Wyrażenie musi być typu logicznego, arytmetycznego lub wskaźnikowego.
-
Wartość warunku jest niejawnie przekształcana na typ
bool. -
Jeśli wartość wyrażenia jest liczbą lub wskaźnikiem, to wartość różna od zera jest interpretowana jak
true, wpp. zafalse. -
elsedotyczy ostatnio spotkanegoifbezelse. -
Warunek może być także deklaracją (z pewnymi ograniczeniami) mającą część inicjującą, jej zasięgiem jest cała instrukcja warunkowa.
-
Instrukcja składowa może być deklaracją (jej zasięgiem zawsze jest tylko ta instrukcja składowa).
Instrukcja warunkowa służy warunkowemu wykonaniu instrukcji.
Wykonanie instrukcji warunkowej zaczyna się od obliczenia wartości wyrażenia i niejawnego przekształcenia jej do typu bool.
Jeśli tak otrzymana wartością jest true, to wykonywana jest pierwsza podinstrukcja, jeśli zaś tą wartością jest false
to, o ile jest część else, wykonywana jest druga podinstrukcja.
if (i>=0) cout << "nieujemne"; else cout << ujemne";
Ciekawostką (odziedziczoną po C) jest to, że typem wyrażenia pełniącego rolę warunku może być typ liczbowy lub nawet wskaźnikowy.
Jeśli wartość takiego wyrażenia jest różna od zera (dla wskaźników oznacza to wskaźnik o wartości różnej od NULL), to jest
ono traktowane jako warunek prawdziwy (a w przeciwnym przypadku jako fałszywy).
if (i) i = 0;
if (p) i = *p; else i = 0;
Jeśli jedna instrukcja warunkowa jest zagnieżdżona w drugiej i nie każda z nich ma część else, to powstaje
problem składniowy, z którą instrukcją warunkową powiązać tę część else.
if (i>=0)
if (i>0)
cout << "dodatnie";
else // do której instrukcji if?
cout << "??";
W C++ przyjęto, tak jak prawdopodobnie w każdym języku programowania, że else jest doklejany do bliższej mu poprzedzającej
instrukcji if. Zatem ostatni przykład można uzupełnić następująco.
if (i>=0)
if (i>0)
cout << "dodatnie";
else // (i>=0) && !(i>0)
cout << "równe zero";
Oczywiście gdyby chodziło o odwrotne dowiązanie części else łatwo to osiągnąć za pomocą instrukcji złożonej.
if (i>=0)
{if (i>0)
cout << "dodatnie";}
else // !(i>=0)
cout << "ujemne";
Subtelności związane z deklarowaniem zmiennych w warunku lub w przypadku zapisania instrukcji deklaracji jako podinstrukcji instrukcji warunkowej pomijamy.
3.4.5. Instrukcja wyboru
| . | instrukcja_wyboru: | |
| . | . | switch (wyrażenie) instrukcja |
-
Powoduje przekazanie sterowania do jednej z podinstrukcji występujących w instrukcji, o etykiecie wyznaczonej przez wartość wyrażenia.
-
Wyrażenie musi być typu całkowitego.
-
Podinstrukcje (wewnątrz instrukcji) mogą być etykietowane jedną (kilkoma) etykietami przypadków:
case wyrażenie_stałe : -
Wszystkie stałe przypadków muszą mieć różne wartości.
-
Może wystąpić (co najwyżej jedna) etykieta:
default :Nie musi być ostatnią etykietą, bo i tak zawsze najpierw są analizowane etykietycase. -
Podczas wykonywania instrukcji
switchoblicza się wartość wyrażenia, a następnie porównuje się ją ze wszystkimi stałymi występującymi pocase. Jeśli któraś z nich równa się wartości warunku, to sterowanie jest przekazywane do instrukcji poprzedzonej etykietą z tą wartością, wpp. jeśli jest etykietadefault, do instr. poprzedzonej tą etykietą, wpp. sterowanie przechodzi bezpośrednio za instr.switch. Ponieważ sterowanie przekracza etykietycaseidefault, prawie zawsze trzeba jawnie kończyć wykonywanie obsługi przypadku instrukcjąbreak!. -
Wyrażenie może być także deklaracją (z pewnymi ograniczeniami), której zasięgiem jest dana instrukcja.
-
Ta deklaracja musi zawierać część inicjalizującą.
-
Instrukcja może być deklaracją, (jej zasięgiem zawsze jest tylko ta instrukcja).
-
Wartość wyrażenia jest niejawnie przekształcana na typ całkowity lub wyliczeniowy.
Czasem wybór jednej z dwu operacji nie wystarcza, wtedy często można zastosować instrukcję wyboru switch.
Nie jest ona niestety tak wygodna jak np. w Pascalu. Jej wykonanie polega na wyliczeniu wartości wyrażenia (musi
ono być typu całkowitego lub wyliczeniowego), a następnie na wyszukaniu w instrukcji składowej (która praktycznie
zawsze jest instrukcją złożoną) instrukcji z etykietą case i wyrażeniem o szukanej wartości. Jeśli taka
instrukcja się znajdzie (może być co najwyżej jedna taka instrukcja), to sterowanie przechodzi bezpośrednio
za tę etykietę. Jeśli takiej etykiety nie ma, a jest instrukcja z etykietą default, to sterowanie
przechodzi do niej, w przeciwnym przypadku sterowanie przechodzi za instrukcję switch.
Przy wyborze podinstrukcji pasującej do wyrażenia kolejność instrukcji składowych nie ma znaczenia. W szczególności
instrukcja z etykietą default nie musi być ostatnia (choć zwykle, dla czytelności, umieszcza się ją
na końcu).
Jeśli dla kilku wartości wyrażenia ma być wykonany ten sam zestaw czynności, to te instrukcje poprzedzamy
ciągiem etykiet case. Na przykład chcąc wykonać tę samą akcję dla wartości zmiennej i tak -1 jak i 1 można zapisać
stosowną instrukcję wyboru następująco:
switch (i){
case -1: case 1: i =- i;
}
Nie ma niestety możliwości ani pominięcia powtarzających się słów kluczowych case, ani podania
przedziału wartości, dla których ma się wykonać operacja. To ostatnie powoduje, że jeśli chcemy wybrać wykonywane
operacje dla przedziałów wartości np. 0..99, 100..199, 200..299, to instrukcja wyboru staje się bezużyteczna (trzeba
wtedy wybrać instrukcję warunkową). Jest to dość rozczarowujące w porównaniu np. z Pascalem.
Tym co zapewne powoduje najwięcej kłopotów przy używaniu instrukcji switch jest jej nieintuicyjna semantyka (oparta
na semantyce instrukcji skoku). Otóż po wybraniu odpowiedniej etykiety i wykonaniu instrukcji nią opatrzonej sterowanie
nie przechodzi za instrukcję switch, lecz przechodzi do kolejnych instrukcji znajdujących się
po niej w instrukcji switch!. W kolejnym przykładzie dla znaku ch mającego wartość 'C' wykonają się
oba przypisania, czyli wynik końcowy będzie taki sam, jak dla ch == 'b'.
switch (ch){
case 'C': cout << "stopnie Celsjusza";
case 'K': cout << "stopnie Kelvina";
}
Jeśli chcemy, żeby ta instrukcja przypisywała różne wartości dla znaków 'a' i 'b' musimy zastosować instrukcję
break;, tak jak to pokazano w następnym przykładzie.
switch (ch){
case 'a': i = 1; break;
case 'b': i = 2; break;
}
Pisanie break; na końcu ostatniej podinstrukcji w switch nie jest konieczne, ale jest dobrym zwyczajem,
przydającym się, gdy za jakiś czas dopisuje się kolejną podinstrukcję na końcu instrukcji switch.


