Zagadnienia
1. Zbieżność według rozkładu – zbieżność miar probabilistycznych w przestrzeniach metrycznych
Celem tego rozdziału jest wprowadzenie pewnego nowego typu zbieżności zmiennych losowych, tzw. zbieżności według rozkładu. Zacznijmy od pewnych
intuicji związanych z tym pojęciem. Jak sama nazwa wskazuje, zbieżność ta odnosi się do rozkładów zmiennych losowych. Zatem, aby ją zdefiniować
(na początek, dla rzeczywistych zmiennych losowych), potrzebujemy metody
pozwalającej stwierdzić czy dwa rozkłady prawdopodobieństwa na ![]() są ,,bliskie”. Jeśli tak na to spojrzeć, to automatycznie narzuca się użycie
tzw. całkowitej wariacji miary. Ściślej, definiujemy odległość dwóch miar probabilistycznych
są ,,bliskie”. Jeśli tak na to spojrzeć, to automatycznie narzuca się użycie
tzw. całkowitej wariacji miary. Ściślej, definiujemy odległość dwóch miar probabilistycznych ![]() ,
, ![]() na
na ![]() jako całkowitą wariację ich różnicy:
jako całkowitą wariację ich różnicy:
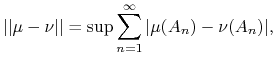 |
gdzie supremum jest wzięte po wszystkich rozbiciach prostej rzeczywistej na przeliczalną liczbę zbiorów borelowskich ![]() .
I teraz mówimy, że
.
I teraz mówimy, że ![]() zbiega do
zbiega do ![]() jeśli
jeśli ![]() gdy
gdy ![]() .
.
To podejście jest jednak zbyt restrykcyjne i zbieżność według rozkładu wprowadzimy w inny sposób.
W całym niniejszym rozdziale, ![]() jest przestrzenią metryczną,
jest przestrzenią metryczną, ![]() oznacza klasę podzbiorów borelowskich
oznacza klasę podzbiorów borelowskich ![]() oraz
oraz
Definicja 1.1
Niech ![]() będzie ciągiem miar probabilistycznych na
będzie ciągiem miar probabilistycznych na ![]() (rozkładów prawdopodobieństwa na
(rozkładów prawdopodobieństwa na ![]() ). Mówimy, że ciąg
). Mówimy, że ciąg
![]() jest zbieżny według rozkładu do
jest zbieżny według rozkładu do ![]() (lub słabo zbieżny do
(lub słabo zbieżny do ![]() ), jeżeli dla każdej funkcji
), jeżeli dla każdej funkcji ![]() mamy
mamy ![]() . Oznaczenie:
. Oznaczenie: ![]() .
.
Dowód poprawności definicji: Musimy udowodnić, że jeśli ![]() oraz
oraz ![]() , to
, to ![]() . Innymi słowy, musimy wykazać następujący fakt.
. Innymi słowy, musimy wykazać następujący fakt.
Stwierdzenie 1.1
Załóżmy, że ![]() ,
, ![]() są takimi rozkładami w
są takimi rozkładami w ![]() , że dla każdej funkcji
, że dla każdej funkcji ![]() ,
, ![]() . Wówczas
. Wówczas ![]() .
.
Przytoczmy pomocniczy fakt z Topologii I.
Lemat 1.1
Niech ![]() będzie domkniętym podzbiorem
będzie domkniętym podzbiorem ![]() . Wówczas dla każdego
. Wówczas dla każdego ![]() istnieje
istnieje ![]() jednostajnie ciągła spełniająca
jednostajnie ciągła spełniająca ![]() oraz
oraz
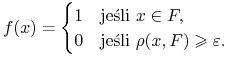 |
Dowód Stwierdzenia 1.1:
Wystarczy udowodnić, że dla każdego domkniętego ![]() zachodzi
zachodzi ![]() (teza wynika wówczas prosto z lematu o
(teza wynika wówczas prosto z lematu o ![]() układach). Dla każdego
układach). Dla każdego ![]() i
i ![]() , Lemat 1.1 daje funkcję
, Lemat 1.1 daje funkcję ![]() o odpowiednich własnościach. Widzimy, iż dla każdego
o odpowiednich własnościach. Widzimy, iż dla każdego ![]() ,
, ![]() , zatem
, zatem
Przykłady:
-
Załóżmy, że
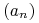 jest ciągiem punktów z
jest ciągiem punktów z 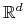 oraz
oraz 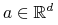 . Wówczas
. Wówczas 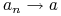 wtedy i tylko wtedy, gdy
wtedy i tylko wtedy, gdy 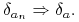 Istotnie, wtedy i tylko wtedy, gdy dla każdej funkcji
Istotnie, wtedy i tylko wtedy, gdy dla każdej funkcji 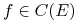 mamy
mamy 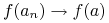 , czyli
, czyli 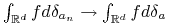 .
. -
Załóżmy, że
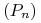 jest ciągiem miar probabilistycznych na
jest ciągiem miar probabilistycznych na 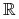 , zadanym przez
, zadanym przez
Wówczas
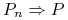 , gdzie
, gdzie 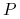 jest rozkładem jednostajnym na
jest rozkładem jednostajnym na ![[0,1]](wyklady/rp2/mi/mi302.png) . Istotnie, dla dowolnej funkcji
. Istotnie, dla dowolnej funkcji 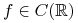 ,
,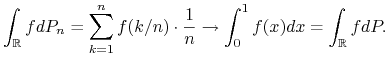
Ważna uwaga: Z tego, że ![]() nie wynika, że dla dowolnego
nie wynika, że dla dowolnego ![]() mamy
mamy ![]() . Np. weźmy
. Np. weźmy ![]() oraz ciąg
oraz ciąg ![]() liczb rzeczywistych taki, że
liczb rzeczywistych taki, że ![]() oraz
oraz ![]() . Jak już wiemy,
. Jak już wiemy, ![]() , ale
, ale
Twierdzenie 1.1
Niech ![]() ,
, ![]() (
(![]() będą miarami probabilistycznymi na
będą miarami probabilistycznymi na ![]() . Następujące warunki są równoważne.
. Następujące warunki są równoważne.
a) ![]() .
.
b) Dla każdej funkcji ![]() jednostajnie ciągłej,
jednostajnie ciągłej, ![]() .
.
c) Dla każdego domkniętego ![]() ,
, ![]() .
.
d) Dla każdego otwartego ![]() ,
, ![]() .
.
e) Dla każdego ![]() takiego, że
takiego, że ![]() , mamy
, mamy ![]() .
.
Dowód:
a) ![]() b) – oczywiste.
b) – oczywiste.
b) ![]() c) Ustalmy
c) Ustalmy ![]() i niech
i niech ![]() . Na mocy Lematu 1.1 istnieje
. Na mocy Lematu 1.1 istnieje ![]() jednostajnie ciągła, przyjmująca wartości w
jednostajnie ciągła, przyjmująca wartości w ![]() , równa
, równa ![]() na
na ![]() oraz
oraz ![]() na
na ![]() . Mamy
. Mamy
Zatem ![]() , i z dowolności
, i z dowolności ![]() wynika, co trzeba.
wynika, co trzeba.
c) ![]() a) Wystarczy udowodnić, że dla każdej funkcji
a) Wystarczy udowodnić, że dla każdej funkcji ![]() ,
,
| (1.1) |
gdyż po zastąpieniu ![]() przez
przez ![]() dostaniemy
dostaniemy ![]() , a więc w rzeczywistości mamy równość, gdyż
, a więc w rzeczywistości mamy równość, gdyż ![]() .
.
Zauważmy, że jeśli ![]() , to istnieją
, to istnieją ![]() oraz
oraz ![]() takie, że
takie, że ![]() przyjmuje wartości w przedziale
przyjmuje wartości w przedziale ![]() . Co więcej, jeśli wykażemy (1.1) dla
. Co więcej, jeśli wykażemy (1.1) dla ![]() , to nierówność będzie także zachodzić dla
, to nierówność będzie także zachodzić dla ![]() . Innymi słowy, możemy bez straty ogólności założyć, że
. Innymi słowy, możemy bez straty ogólności założyć, że ![]() dla każdego
dla każdego ![]() .
.
Ustalmy taką funkcję ![]() i weźmy dodatnią liczbę całkowitą
i weźmy dodatnią liczbę całkowitą ![]() . Rozważmy zbiory
. Rozważmy zbiory
Oczywiście ![]() oraz zbiory
oraz zbiory ![]() są parami rozłączne. Ponadto,
są parami rozłączne. Ponadto,
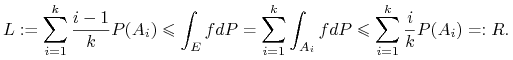 |
Zauważmy, że
i ![]() jest zstępującym ciągiem zbiorów domkniętych. Zatem
jest zstępującym ciągiem zbiorów domkniętych. Zatem ![]() ,
, ![]() , i podstawiając dostajemy
, i podstawiając dostajemy
oraz
Przeprowadzamy analogiczne oszacowania dla ![]() : w szczególności mamy
: w szczególności mamy
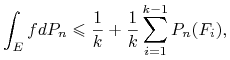 |
skąd wynika, na mocy c),
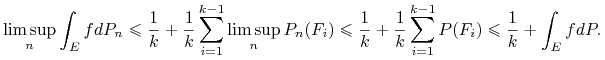 |
Wystarczy tylko zbiec z ![]() do nieskończoności.
do nieskończoności.
c) ![]() d): oczywiste po przejściu do dopełnień zbiorów.
d): oczywiste po przejściu do dopełnień zbiorów.
c) ![]() e) Załóżmy, że
e) Załóżmy, że ![]() spełnia warunek
spełnia warunek ![]() . Ponieważ
. Ponieważ ![]() oraz
oraz ![]() , mamy
, mamy ![]() . Z drugiej strony, korzystając z c) oraz d), mamy
. Z drugiej strony, korzystając z c) oraz d), mamy
a zatem wszędzie mamy równości: to oznacza tezę podpunktu e).
e) ![]() c) Weźmy dowolny domknięty zbiór
c) Weźmy dowolny domknięty zbiór ![]() . Dla każdego
. Dla każdego ![]() zbiór
zbiór ![]() jest domknięty. Ponadto, zbiór
jest domknięty. Ponadto, zbiór ![]() jest co najwyżej przeliczalny; zatem istnieje ciąg
jest co najwyżej przeliczalny; zatem istnieje ciąg ![]() liczb dodatnich malejący do
liczb dodatnich malejący do ![]() taki, że
taki, że ![]() dla każdego
dla każdego ![]() . Ponieważ
. Ponieważ ![]() , mamy więc
, mamy więc ![]() dla każdego
dla każdego ![]() , a zatem, korzystając z e), przy ustalonym
, a zatem, korzystając z e), przy ustalonym ![]() ,
,
Zbiegając z ![]() , mamy
, mamy ![]() oraz
oraz ![]() , na mocy tego, iż
, na mocy tego, iż ![]() jest domknięty.
jest domknięty.
Stwierdzenie 1.2
Załóżmy, że ![]() ,
, ![]() są rozkładami prawdopodobieństwa w
są rozkładami prawdopodobieństwa w ![]() (
(![]() ), o dystrybuantach
), o dystrybuantach ![]() ,
, ![]() , odpowiednio. Wówczas
, odpowiednio. Wówczas ![]() wtedy i tylko wtedy, gdy
wtedy i tylko wtedy, gdy ![]() dla każdego punktu
dla każdego punktu ![]() , w którym
, w którym ![]() jest ciągła.
jest ciągła.
Dowód:
![]() Weźmy punkt
Weźmy punkt ![]() ciągłości dystrybuanty
ciągłości dystrybuanty ![]() i niech
i niech ![]() . Zauważmy, iż
. Zauważmy, iż ![]() ; w przeciwnym razie
; w przeciwnym razie ![]() miałaby nieciągłość w punkcie
miałaby nieciągłość w punkcie ![]() (istotnie, mielibyśmy
(istotnie, mielibyśmy
Zatem na mocy podpunktu e) Twierdzenia 1.1, ![]() .
.
![]() Najpierw udowodnimy
Najpierw udowodnimy
Lemat 1.2
Załóżmy, że ![]() jest przestrzenią metryczną,
jest przestrzenią metryczną, ![]() jest
jest ![]() -układem takim, że każdy zbiór otwarty jest sumą skończoną lub przeliczalną zbiorów z
-układem takim, że każdy zbiór otwarty jest sumą skończoną lub przeliczalną zbiorów z ![]() . Jeśli
. Jeśli ![]() ,
, ![]() (
(![]() ) są miarami probabilistycznymi na
) są miarami probabilistycznymi na ![]() takimi, że dla każdego
takimi, że dla każdego ![]() mamy
mamy ![]() , to
, to ![]() .
.
Udowodnimy, że dla każdego zbioru otwartego ![]() ,
, ![]() . Ustalmy więc zbiór otwarty
. Ustalmy więc zbiór otwarty ![]() oraz
oraz ![]() . Z założeń lematu istnieje skończony ciąg
. Z założeń lematu istnieje skończony ciąg ![]() elementów
elementów ![]() taki, że
taki, że
Mamy ![]() , skąd, na mocy wzoru włączeń i wyłączeń,
, skąd, na mocy wzoru włączeń i wyłączeń,
Wystarczy skorzystać z tego, że ![]() było dowolne.
było dowolne.
Wracamy do dowodu stwierdzenia. Dla każdego ![]() istnieje co najwyżej przeliczalnie wiele hiperpłaszczyzn
istnieje co najwyżej przeliczalnie wiele hiperpłaszczyzn ![]() prostopadłych do osi
prostopadłych do osi ![]() , o dodatniej mierze
, o dodatniej mierze ![]() ; niech
; niech ![]() oznacza dopełnienie sumy wszystkich takich hiperpłaszczyzn (sumujemy także po
oznacza dopełnienie sumy wszystkich takich hiperpłaszczyzn (sumujemy także po ![]() ). Jak łatwo zauważyć,
). Jak łatwo zauważyć, ![]() jest gęstym podzbiorem
jest gęstym podzbiorem ![]() oraz każdy punkt z
oraz każdy punkt z ![]() jest punktem ciągłości
jest punktem ciągłości ![]() . Zbiór
. Zbiór
jest ![]() -układem i każdy zbiór otwarty jest sumą skończoną lub przeliczalną zbiorów z
-układem i każdy zbiór otwarty jest sumą skończoną lub przeliczalną zbiorów z ![]() .
Mamy
.
Mamy
Wystarczy skorzystać z poprzedniego lematu.
∎Definicja 1.2
Załóżmy, że ![]() ,
, ![]() (
(![]() ) są zmiennymi losowymi o wartościach w
) są zmiennymi losowymi o wartościach w ![]() oraz
oraz ![]() jest miarą probabilistyczną na
jest miarą probabilistyczną na ![]() .
.
(i) Mówimy, że ciąg ![]() jest zbieżny według rozkładu do
jest zbieżny według rozkładu do ![]() , jeśli
, jeśli ![]() . Oznaczenie:
. Oznaczenie: ![]() lub
lub ![]() .
.
(ii) Mówimy, że ciąg ![]() jest zbieżny według rozkładu do
jest zbieżny według rozkładu do ![]() , jeśli
, jeśli ![]() . Oznaczenie
. Oznaczenie ![]() lub
lub ![]() .
.
Uwagi:
-
W definicji zbieżności według rozkładu, zmienne
 mogą być określone na różnych przestrzeniach probabilistycznych.
mogą być określone na różnych przestrzeniach probabilistycznych. -
Słaba zbieżność odnosi się wyłącznie do rozkładów zmiennych losowych. Na przykład, rozważmy ciąg
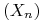 , zadany na przestrzeni probabilistycznej
, zadany na przestrzeni probabilistycznej ![([0,1],\mathcal{B}([0,1]),|\cdot|)](wyklady/rp2/mi/mi219.png) wzorem
wzorem![X_{{2n-1}}=1_{{[0,1/2]}},\,\,\,\, X_{{2n}}=1_{{[1/2,1]}},\,\qquad n=1,\, 2,\,\ldots.](wyklady/rp2/mi/mi169.png)
Jak łatwo zauważyć,
nie jest ani zbieżny prawie na pewno, ani według prawdopodobieństwa. Natomiast z punktu widzenia słabej zbieżności, jest to ciąg stały: 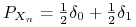 . Ciąg ten zbiega słabo do
. Ciąg ten zbiega słabo do 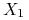 oraz do
oraz do 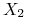 .
.
Stwierdzenie 1.3
Załóżmy, że ![]() jest przestrzenią ośrodkową oraz
jest przestrzenią ośrodkową oraz ![]() ,
, ![]() ,
, ![]() (
(![]() ) są zmiennymi losowymi o wartościach w
) są zmiennymi losowymi o wartościach w ![]() , przy czym dla każdego
, przy czym dla każdego ![]() , zmienne
, zmienne ![]() oraz
oraz ![]() są określone na tej samej przestrzeni probabilistycznej. Jeśli
są określone na tej samej przestrzeni probabilistycznej. Jeśli ![]() oraz
oraz ![]() , to
, to ![]() .
.
Biorąc ![]() , dostajemy stąd natychmiast następujący fakt.
, dostajemy stąd natychmiast następujący fakt.
Wniosek 1.1
Jeśli ![]() zbiega do
zbiega do ![]() według prawdopodobieństwa, to zbiega także według rozkładu.
według prawdopodobieństwa, to zbiega także według rozkładu.
Dowód Stwierdzenia 1.3
Niech ![]() będzie dowolnym domkniętym podzbiorem przestrzeni
będzie dowolnym domkniętym podzbiorem przestrzeni ![]() i ustalmy
i ustalmy ![]() . Zbiór
. Zbiór ![]() jest domknięty i mamy
jest domknięty i mamy
Zatem
i przechodząc z ![]() do
do ![]() dostajemy
dostajemy ![]() . Z dowolności
. Z dowolności ![]() oraz podpunktu c) Twierdzenia 1.1 wynika teza.
oraz podpunktu c) Twierdzenia 1.1 wynika teza.
Definicja 1.3
Niech ![]() będzie pewnym zbiorem miar probabilistycznych na
będzie pewnym zbiorem miar probabilistycznych na ![]() . Mówimy, że ten zbiór jest ciasny (jędrny) jeśli dla każdego
. Mówimy, że ten zbiór jest ciasny (jędrny) jeśli dla każdego ![]() istnieje zwarty podzbiór
istnieje zwarty podzbiór ![]() przestrzeni
przestrzeni ![]() taki, że
taki, że ![]() dla każdego
dla każdego ![]() .
.
Przykład:
Załóżmy, że ![]() jest rodziną zmiennych losowych o wartościach rzeczywistych, takich, że dla pewnego
jest rodziną zmiennych losowych o wartościach rzeczywistych, takich, że dla pewnego ![]() ,
, ![]() . Wówczas rodzina rozkładów
. Wówczas rodzina rozkładów ![]() jest ciasna.
Istotnie, ustalmy
jest ciasna.
Istotnie, ustalmy ![]() i
i ![]() . Na mocy nierówności Czebyszewa, dla każdego
. Na mocy nierówności Czebyszewa, dla każdego ![]() ,
,
o ile ![]() ; wystarczy więc wziąć
; wystarczy więc wziąć ![]() .
.
Twierdzenie 1.2 (Prochorow)
(i) (Twierdzenie odwrotne) Jeśli ![]() jest zbiorem ciasnym, to z każdego ciągu elementów
jest zbiorem ciasnym, to z każdego ciągu elementów ![]() można wybrać podciąg zbieżny.
można wybrać podciąg zbieżny.
(ii) (Twierdzenie proste) Jeśli ![]() jest przestrzenią polską (tzn. ośrodkową i zupełną) i
jest przestrzenią polską (tzn. ośrodkową i zupełną) i ![]() ma tę własność, że z każdego ciągu można wybrać podciąg zbieżny, to
ma tę własność, że z każdego ciągu można wybrać podciąg zbieżny, to ![]() jest zbiorem ciasnym.
jest zbiorem ciasnym.
Potrzebne nam będą następujące trzy fakty: z Topologii, Analizy Funkcjonalnej oraz Teorii Miary.
Stwierdzenie 1.4
Załóżmy, że ![]() jest przestrzenią metryczną zwartą. Wówczas
jest przestrzenią metryczną zwartą. Wówczas ![]() jest ośrodkowa.
jest ośrodkowa.
Twierdzenie 1.3 (Riesz)
Załóżmy, że ![]() jest dodatnim funkcjonałem liniowym ciągłym, tzn.
jest dodatnim funkcjonałem liniowym ciągłym, tzn.
(i) ![]() dla dowolnych
dla dowolnych ![]() ,
, ![]() .
.
(ii) Istnieje stała ![]() taka, że
taka, że ![]() dla wszystkich
dla wszystkich ![]() .
.
(iii) Dla dowolnej nieujemnej funkcji ![]() mamy
mamy ![]() .
.
Wówczas istnieje dokładnie jedna miara skończona ![]() na
na ![]() taka, że
taka, że ![]() dla dowolnej funkcji
dla dowolnej funkcji ![]() .
.
Stwierdzenie 1.5 (Regularność)
Załóżmy, że ![]() jest miarą skończoną na
jest miarą skończoną na ![]() . Wówczas dla każdego
. Wówczas dla każdego ![]() istnieje ciąg
istnieje ciąg ![]() zbiorów domkniętych zawartych w
zbiorów domkniętych zawartych w ![]() oraz ciąg
oraz ciąg ![]() zbiorów otwartych zawierających
zbiorów otwartych zawierających ![]() , takie, że
, takie, że ![]() oraz
oraz ![]() .
.
Dowód twierdzenia odwrotnego
Załóżmy, że ![]() jest ciasny. Wobec tego, dla każdego
jest ciasny. Wobec tego, dla każdego ![]() istnieje zwarty podzbiór
istnieje zwarty podzbiór ![]() przestrzeni
przestrzeni ![]() taki, że
taki, że ![]() dla wszystkich
dla wszystkich ![]() . Bez straty ogólności możemy założyć, że ciąg
. Bez straty ogólności możemy założyć, że ciąg ![]() jest wstępujący (zastępując ten ciąg, w razie potrzeby, przez ciąg
jest wstępujący (zastępując ten ciąg, w razie potrzeby, przez ciąg ![]() ).
).
Niech ![]() będzie ciągiem miar z
będzie ciągiem miar z ![]() . Dla większej przejrzystości dowodu, podzielimy go na kilka części.
. Dla większej przejrzystości dowodu, podzielimy go na kilka części.
1. Na mocy Stwierdzenia 1.4, dla każdego ![]() ,
, ![]() jest przestrzenią ośrodkową. Niech
jest przestrzenią ośrodkową. Niech ![]() będzie jej przeliczalnym gęstym podzbiorem. Dla każdego
będzie jej przeliczalnym gęstym podzbiorem. Dla każdego ![]() , ciąg
, ciąg ![]() jest ograniczonym ciągiem liczbowym; można z niego wybrać podciąg zbieżny. Stosując metodę przekątniową widzimy, iż istnieje podciąg
jest ograniczonym ciągiem liczbowym; można z niego wybrać podciąg zbieżny. Stosując metodę przekątniową widzimy, iż istnieje podciąg ![]() taki, że dla wszystkich
taki, że dla wszystkich ![]() , ciąg
, ciąg ![]() jest zbieżny.
jest zbieżny.
2. Pokażemy, że dla każdego ![]() i każdej funkcji
i każdej funkcji ![]() , ciąg
, ciąg ![]() jest zbieżny. Ustalmy
jest zbieżny. Ustalmy ![]() oraz
oraz ![]() takie, że
takie, że ![]() . Mamy
. Mamy
Dwa skrajne składniki po prawej stronie szacują się przez ![]() ; na przykład, mamy
; na przykład, mamy
środkowy składnik nie przekracza ![]() o ile
o ile ![]() ,
, ![]() są dostatecznie duże; wynika to z definicji podciągu
są dostatecznie duże; wynika to z definicji podciągu ![]() .
.
3. Oznaczmy ![]() , dla
, dla ![]() . Jest oczywiste, że
. Jest oczywiste, że ![]() spełnia założenia Twierdzenia Riesza. Zatem istnieje miara
spełnia założenia Twierdzenia Riesza. Zatem istnieje miara ![]() na
na ![]() taka, że
taka, że ![]() dla wszystkich
dla wszystkich ![]() ,
, ![]() . Rozszerzmy tę miarę na
. Rozszerzmy tę miarę na ![]() , kładąc
, kładąc ![]() .
.
4. Udowodnimy, że dla każdego ![]() ciąg
ciąg ![]() spełnia warunek Cauchy'ego. ściślej, wykażemy, że
spełnia warunek Cauchy'ego. ściślej, wykażemy, że
| (1.3) |
Najpierw załóżmy, że ![]() jest zbiorem domkniętym i niech
jest zbiorem domkniętym i niech ![]() . Niech
. Niech ![]() będzie nieujemną funkcją jednostajnie ciągłą pochodzącą z Lematu 1.1. Mamy
będzie nieujemną funkcją jednostajnie ciągłą pochodzącą z Lematu 1.1. Mamy
Zbiegając teraz z ![]() do nieskończoności dostajemy
do nieskończoności dostajemy
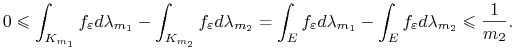 |
Weźmy teraz ![]() ; ponieważ
; ponieważ ![]() , otrzymujemy (1.3) dla zbiorów domkniętych, na mocy twierdzenia Lebesgue'a. Aby otrzymać tę nierówność w przypadku ogólnym, posłużymy się regularnością. Dla dowolnego
, otrzymujemy (1.3) dla zbiorów domkniętych, na mocy twierdzenia Lebesgue'a. Aby otrzymać tę nierówność w przypadku ogólnym, posłużymy się regularnością. Dla dowolnego ![]() istnieją ciągi
istnieją ciągi ![]() oraz
oraz ![]() zbiorów
domkniętych zawartych w
zbiorów
domkniętych zawartych w ![]() , takie, że
, takie, że ![]() oraz
oraz ![]() . Korzystając z (1.3) dla zbioru domkniętego
. Korzystając z (1.3) dla zbioru domkniętego ![]() i zbiegając z
i zbiegając z ![]() otrzymujemy żądaną nierówność.
otrzymujemy żądaną nierówność.
5. Wiemy, na mocy poprzedniej części, że ciąg ![]() jest zbieżny dla każdego
jest zbieżny dla każdego ![]() . Oznaczmy jego granicę przez
. Oznaczmy jego granicę przez ![]() . Wykażemy, że
. Wykażemy, że ![]() jest miarą probabilistyczną oraz
jest miarą probabilistyczną oraz ![]() . Pierwsza własność wyniknie z następujących trzech faktów.
. Pierwsza własność wyniknie z następujących trzech faktów.
a) ![]() .
.
b) ![]() dla
dla ![]() takich, że
takich, że ![]()
c) Jeśli ![]() oraz
oraz ![]() , to
, to ![]() .
.
Dowód a) Mamy ![]() . Zbiegając z
. Zbiegając z ![]() do nieskończoności dostajemy
do nieskończoności dostajemy ![]() , i teraz dążąc z
, i teraz dążąc z ![]() do nieskończoności otrzymujemy
do nieskończoności otrzymujemy ![]() .
.
Dowód b) Jasne na mocy definicji ![]() i tego, że
i tego, że ![]() jest miarą dla każdego
jest miarą dla każdego ![]() .
.
Dowód c) Na mocy (1.3), mamy ![]() dla wszystkich
dla wszystkich ![]() oraz
oraz ![]() . Zatem, dla dowolnego
. Zatem, dla dowolnego ![]() ,
,
Zbiegając z ![]() widzimy, że
widzimy, że
![]() , co na mocy dowolności
, co na mocy dowolności ![]() daje
daje ![]() , czyli
, czyli ![]() .
.
Pozostało już tylko sprawdzić, że ![]() . Dla usalonej
. Dla usalonej ![]() , mamy
, mamy
Na mocy ciasności, ![]() . Ponadto, z definicji
. Ponadto, z definicji ![]() ,
, ![]() gdy
gdy ![]() . Wreszcie,
. Wreszcie,
Zatem ![]() gdy
gdy ![]() . Dowód jest zakończony.
. Dowód jest zakończony.
Dowód prostego twierdzenia Prochorowa jest znacznie łatwiejszy i pozostawiamy go jako ćwiczenie (patrz zadanie 13).
Na zakończenie, zaprezentujemy następujące dwa fakty (bez dowodu).
Twierdzenie 1.4 (Skorochod)
Załóżmy, że ![]() jest przestrzenią ośrodkową oraz
jest przestrzenią ośrodkową oraz ![]() ,
, ![]() (
(![]() ) są miarami probabilistycznymi na
) są miarami probabilistycznymi na ![]() . Jeśli
. Jeśli ![]() , to istnieją zmienne losowe
, to istnieją zmienne losowe ![]() ,
, ![]() (
(![]() ), określone na tej samej przestrzeni probabilistycznej
), określone na tej samej przestrzeni probabilistycznej ![]() takie, że
takie, że ![]() ,
, ![]() (
(![]() ) oraz
) oraz ![]() prawie na pewno.
prawie na pewno.
Twierdzenie 1.5
Załóżmy, że ![]() jest przestrzenią ośrodkową i niech
jest przestrzenią ośrodkową i niech ![]() oznacza klasę wszystkich miar probabilistycznych na
oznacza klasę wszystkich miar probabilistycznych na ![]() . Dla
. Dla ![]() definiujemy
definiujemy
Wówczas ![]() jest metryką w
jest metryką w ![]() (jest to tzw. metryka Levy-Prochorowa) oraz zbieżność w sensie tej metryki pokrywa się ze zwykłą zbieżnością miar probabilistycznych.
(jest to tzw. metryka Levy-Prochorowa) oraz zbieżność w sensie tej metryki pokrywa się ze zwykłą zbieżnością miar probabilistycznych.
1.1. Zadania
1. Udowodnić, że ciąg ![]() jest zbieżny według rozkładu do Exp
jest zbieżny według rozkładu do Exp![]() .
.
2. Dany jest ciąg ![]() zmiennych losowych zbieżny według
rozkładu do zmiennej losowej
zmiennych losowych zbieżny według
rozkładu do zmiennej losowej ![]() . Udowodnić, że ciąg
. Udowodnić, że ciąg ![]() jest zbieżny według rozkładu do zmiennej
jest zbieżny według rozkładu do zmiennej ![]() .
.
3. Czy zmienne losowe posiadające gęstość mogą zbiegać
według rozkładu do zmiennej o rozkładzie dyskretnym? Czy zmienne
losowe o rozkładach dyskretnych mogą zbiegać do zmiennej o
rozkładzie ciągłym?
4. Niech ![]() będą zmiennymi losowymi, przy
czym dla
będą zmiennymi losowymi, przy
czym dla ![]() rozkład zmiennej
rozkład zmiennej ![]() określony jest
następująco:
określony jest
następująco:
Udowodnić, że ciąg ![]() jest zbieżny według rozkładu.
Wyznaczyć rozkład graniczny.
jest zbieżny według rozkładu.
Wyznaczyć rozkład graniczny.
5. Niech ![]() oznacza rozkład Bernoulliego o
oznacza rozkład Bernoulliego o ![]() próbach
z prawdopodobieństwem sukcesu
próbach
z prawdopodobieństwem sukcesu ![]() , a
, a ![]() - rozkład
Poissona z parametrem
- rozkład
Poissona z parametrem ![]() . Wykazać, że jeśli
. Wykazać, że jeśli ![]() , to
, to ![]() .
.
6. Zmienne losowe ![]() zbiegają według
rozkładu do zmiennej
zbiegają według
rozkładu do zmiennej ![]() stałej p.n. Wykazać, że ciąg
stałej p.n. Wykazać, że ciąg ![]() zbiega do
zbiega do ![]() według prawdopodobieństwa.
według prawdopodobieństwa.
7. Niech ![]() ,
, ![]() oznaczają odpowiednio gęstości
rozkładów prawdopodobieństwa
oznaczają odpowiednio gęstości
rozkładów prawdopodobieństwa ![]() ,
, ![]() na
na ![]() .
Udowodnić, że jeśli
.
Udowodnić, że jeśli ![]() p.w., to
p.w., to ![]() .
.
8. Niech ![]() będzie przeliczalnym podzbiorem
będzie przeliczalnym podzbiorem ![]() ,
zaś
,
zaś ![]() ,
, ![]() - miarami probabilistycznymi skupionymi na
- miarami probabilistycznymi skupionymi na ![]() .
Wykazać, że jeśli dla każdego
.
Wykazać, że jeśli dla każdego ![]() mamy
mamy ![]() , to
, to ![]() .
.
9. Ciąg dystrybuant ![]() zbiega punktowo do dystrybuanty
ciągłej
zbiega punktowo do dystrybuanty
ciągłej ![]() . Wykazać, że zbieżność jest jednostajna.
. Wykazać, że zbieżność jest jednostajna.
10. Dane są ciągi ![]() ,
, ![]() zmiennych losowych, określonych na tej samej przestrzeni probabilistycznej, przy czym
zmiennych losowych, określonych na tej samej przestrzeni probabilistycznej, przy czym ![]() zbiega według rozkładu do
zbiega według rozkładu do ![]() , a
, a ![]() zbiega według rozkładu do zmiennej
zbiega według rozkładu do zmiennej ![]() stałej p.n.. Udowodnić, że
stałej p.n.. Udowodnić, że ![]() zbiega według rozkładu do
zbiega według rozkładu do ![]() . Czy teza pozostaje prawdziwa bez założenia o jednopunktowym rozkładzie
. Czy teza pozostaje prawdziwa bez założenia o jednopunktowym rozkładzie ![]() ?
?
11. Dany jest ciąg ![]() zmiennych losowych przyjmujących wartości w przedziale
zmiennych losowych przyjmujących wartości w przedziale ![]() . Udowodnić, że jeśli dla każdego
. Udowodnić, że jeśli dla każdego ![]() mamy
mamy ![]() , to
, to ![]() jest zbieżny według rozkładu.
jest zbieżny według rozkładu.
12. Załóżmy, że ![]() jest ciągiem niezależnych zmiennych losowych o rozkładzie Cauchy'ego z parametrem
jest ciągiem niezależnych zmiennych losowych o rozkładzie Cauchy'ego z parametrem ![]() , tzn. z gęstością
, tzn. z gęstością
Udowodnić, że ![]() , gdzie
, gdzie ![]() ma rozkład wykładniczy. Wyznaczyć parametr tego rozkładu.
ma rozkład wykładniczy. Wyznaczyć parametr tego rozkładu.
13. Załóżmy, że ![]() jest przestrzenią polską oraz
jest przestrzenią polską oraz ![]() jest rodziną miar probabilistycznych na
jest rodziną miar probabilistycznych na ![]() , taką, że z każdego ciągu jej elementów można wybrać podciąg zbieżny.
, taką, że z każdego ciągu jej elementów można wybrać podciąg zbieżny.
(i) Udowodnić, że
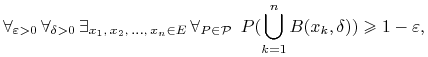 |
gdzie ![]() .
.
(ii) Wywnioskować z (i) proste twierdzenie Prochorowa (wskazówka: w przestrzeni metrycznej zupełnej zbiór domknięty i całkowicie ograniczony - tzn. dla każdego ![]() posiadający skończoną
posiadający skończoną ![]() -sieć - jest zwarty).
-sieć - jest zwarty).
14. Załóżmy, że ciąg ![]() zbiega według rozkładu do
zbiega według rozkładu do ![]() . Niech
. Niech ![]() będzie taką funkcją borelowską, że
będzie taką funkcją borelowską, że ![]() .
.
(i) Udowodnić, że ![]() .
.
(ii) Udowodnić, że jeśli ![]() jest dodatkowo ograniczona, to
jest dodatkowo ograniczona, to ![]() .
.
15. Załóżmy, że ciąg ![]() zbiega według rozkładu do
zbiega według rozkładu do ![]() . Udowodnić, że
. Udowodnić, że
(i) ![]() .
.
(ii) jeśli ![]() są dodatkowo jednostajnie całkowalne, to
są dodatkowo jednostajnie całkowalne, to ![]() .
.
(iii) jeśli ![]() ,
, ![]() ,
, ![]() ,
, ![]() są calkowalne, nieujemne i
są calkowalne, nieujemne i ![]() , to
, to ![]() są jednostajnie całkowalne.
są jednostajnie całkowalne.
16. Dane są dwa ciągi ![]() oraz
oraz ![]() zmiennych losowych, zbieżnych według rozkładu do
zmiennych losowych, zbieżnych według rozkładu do ![]() oraz
oraz ![]() , odpowiednio.
, odpowiednio.
(i) Czy ![]() zbiega według rozkładu do
zbiega według rozkładu do ![]() ?
?
(ii) Jaka jest odpowiedź w (i) jesli dodatkowo przy każdym ![]() zmienne
zmienne ![]() oraz
oraz ![]() są niezależne?
są niezależne?


