Zagadnienia
14. Markowowskie Monte Carlo V. Elementarna teoria łańcuchów Markowa
14.1. Podstawowe określenia i oznaczenia
W tym rozdziale rozważamy jednorodny łańcuch Markowa ![]() na skończonej przestrzeni stanów
na skończonej przestrzeni stanów ![]() .
Będziemy posługiwać się wygodną i zwięzłą notacją wektorowo-macierzową.
Macierz przejścia o wymiarach
.
Będziemy posługiwać się wygodną i zwięzłą notacją wektorowo-macierzową.
Macierz przejścia o wymiarach ![]() oznaczamy
oznaczamy ![]() . Rozkład początkowy utożsamiamy z wektorem wierszowym
. Rozkład początkowy utożsamiamy z wektorem wierszowym ![]() .
W dalszym ciągu, mówiąc o łańcuchu Markowa,
będziemy mieli na myśli ustaloną macierz przejścia
.
W dalszym ciągu, mówiąc o łańcuchu Markowa,
będziemy mieli na myśli ustaloną macierz przejścia ![]() i dowolnie wybrany
rozkład początkowy
i dowolnie wybrany
rozkład początkowy ![]() . Przyjmujemy oznaczenie
. Przyjmujemy oznaczenie ![]() . W szczególności,
. W szczególności,
![]() , dla
, dla ![]() . Analogicznie będziemy
oznaczali wartość oczekiwaną:
. Analogicznie będziemy
oznaczali wartość oczekiwaną: ![]() lub
lub ![]() . Zauważmy, że
. Zauważmy, że
![]() . Ogólniej, macierz
przejścia w
. Ogólniej, macierz
przejścia w ![]() krokach jest
krokach jest ![]() -tą potęgą macierzy
-tą potęgą macierzy ![]() :
:
Rozkład brzegowy zmiennej losowej ![]() jest wektorem
jest wektorem ![]() :
:
Z macierzą stochastyczną ![]() związany jest graf skierowany opisujący
możliwe przejścia łańcucha. Jest to graf
związany jest graf skierowany opisujący
możliwe przejścia łańcucha. Jest to graf ![]() , gdzie zbiorem
wierzchołków jest przestrzeń stanów, zaś
, gdzie zbiorem
wierzchołków jest przestrzeń stanów, zaś ![]() jest
zbiorem takich par
jest
zbiorem takich par ![]() , że
, że ![]() .
Pojęcia, o których teraz będziemy mówić, są związane tylko ze
strukturą grafu, czyli z położeniem niezerowych elementów macierzy
przejścia.
.
Pojęcia, o których teraz będziemy mówić, są związane tylko ze
strukturą grafu, czyli z położeniem niezerowych elementów macierzy
przejścia.
Mówimy, że stan ![]() jest osiągalny ze stanu
jest osiągalny ze stanu ![]() , jeśli
, jeśli ![]() lub
istnieje liczba naturalna
lub
istnieje liczba naturalna ![]() i ciąg stanów
i ciąg stanów
![]() taki, że
taki, że ![]() dla
dla
![]() . Równoważnie,
. Równoważnie, ![]() dla pewnego
dla pewnego ![]() .
Będziemy stosowali oznaczenie ,,
.
Będziemy stosowali oznaczenie ,,![]() ”.
”.
Stany ![]() i
i ![]() komunikują się, co zapiszemy ,,
komunikują się, co zapiszemy ,,![]() ”,
jeśli
”,
jeśli ![]() i
i ![]() .
.
Stan ![]() jest istotny, jeśli dla każdego
jest istotny, jeśli dla każdego ![]() takiego, że
takiego, że ![]() mamy
mamy
![]() . W przeciwnym razie stan
. W przeciwnym razie stan ![]() nazywamy nieistotnym. Stan
nazywamy nieistotnym. Stan ![]() jest więc
nieistotny, jeśli istnieje stan
jest więc
nieistotny, jeśli istnieje stan ![]() do którego można przejść z
do którego można przejść z ![]() , ale
nie można wrócić do
, ale
nie można wrócić do ![]() . Zbiór stanów istotnych oznaczymy przez
. Zbiór stanów istotnych oznaczymy przez ![]() , zaś
zbiór stanów nieistotnych przez
, zaś
zbiór stanów nieistotnych przez ![]() . Zbiór
. Zbiór ![]() jest (dla łańcucha
o skończonej przestrzeni stanów) zawsze niepusty. Zbiór
jest (dla łańcucha
o skończonej przestrzeni stanów) zawsze niepusty. Zbiór ![]() może być
pusty.
może być
pusty.
Jeśli ![]() dla dowolnych
dla dowolnych ![]() , czyli wszystkie stany komunikują się, to łańcuch nazywamy nieprzywiedlnym. Oczywiście, wszystkie stany łańcucha nieprzywiedlnego są istotne,
, czyli wszystkie stany komunikują się, to łańcuch nazywamy nieprzywiedlnym. Oczywiście, wszystkie stany łańcucha nieprzywiedlnego są istotne, ![]() . Łańcuch nieprzywiedlny nazywamy
nieokresowym, jeśli dla dowolnych
. Łańcuch nieprzywiedlny nazywamy
nieokresowym, jeśli dla dowolnych ![]() istnieje
istnieje ![]() takie, że dla każdego
takie, że dla każdego
![]() mamy
mamy ![]() . Wspomnijmy, że przyjęta przez nas definicja nieokresowości bywa formułowana w nieco inny, ale równoważny sposób. Dla naszych potrzeb wystarczy następujące proste spostrzeżenie: jeśli łańcuch jest nieprzywiedlny i
. Wspomnijmy, że przyjęta przez nas definicja nieokresowości bywa formułowana w nieco inny, ale równoważny sposób. Dla naszych potrzeb wystarczy następujące proste spostrzeżenie: jeśli łańcuch jest nieprzywiedlny i ![]() dla przynajmniej jednego stanu
dla przynajmniej jednego stanu ![]() , to łańcuch jest nieokresowy.
Łatwo zauważyć, że dla łańcucha nieprzywiedlnego
i nieokresowego, dla dostatecznie dużych
, to łańcuch jest nieokresowy.
Łatwo zauważyć, że dla łańcucha nieprzywiedlnego
i nieokresowego, dla dostatecznie dużych ![]() macierz
macierz ![]() ma wszystkie elementy
niezerowe. Wynika to z faktu, że rozważamy łańcuchy ze skończoną przestrzenią stanów.
ma wszystkie elementy
niezerowe. Wynika to z faktu, że rozważamy łańcuchy ze skończoną przestrzenią stanów.
Jeśli ![]() dla dowolnych
dla dowolnych ![]() , czyli wszystkie stany istotne komunikują się, to łańcuch nazywamy jednoklasowym. Łańcuch jednoklasowy
może mieć niepusty zbiór stanów nieistotnych
, czyli wszystkie stany istotne komunikują się, to łańcuch nazywamy jednoklasowym. Łańcuch jednoklasowy
może mieć niepusty zbiór stanów nieistotnych ![]() . Łańcuch jednoklasowy możemy
,,przerobić” na nieprzywiedlny jeśli ograniczymy przestrzeń do stanów istotnych. Macierz
. Łańcuch jednoklasowy możemy
,,przerobić” na nieprzywiedlny jeśli ograniczymy przestrzeń do stanów istotnych. Macierz ![]() jest, jak łatwo widzieć, stochastyczna.
jest, jak łatwo widzieć, stochastyczna.
Interesują nas głównie łańcuchy, które ,,zmierzają w kierunku
położenia równowagi”. Aby uściślić co to znaczy ,,równowaga”, przypomnijmy pojęcie
stacjonarności. Rozkład ![]() jest stacjonarny jeśli dla każdego stanu
jest stacjonarny jeśli dla każdego stanu ![]() ,
,
W notacji macierzowej: ![]() . Stąd oczywiście wynika, że
. Stąd oczywiście wynika, że ![]() .
.
Poniższy prosty fakt można uzasadnić na wiele sposobów. W następnym podrozdziale przytoczymy, wraz z dowodem, piękne twierdzenie Kaca (Twierdzenie 14.2), które implikuje Twierdzenie 14.1.
Twierdzenie 14.1
Jeśli łańcuch Markowa jest nieprzywiedlny, to istnieje dokładnie jeden rozkład stacjonarny ![]() , przy tym
, przy tym ![]() dla każdego
dla każdego ![]() .
.
Z Twierdzenia 14.1 łatwo wynika następujący wniosek.
Wniosek 14.1
Jeśli łańcuch Markowa jest jednoklasowy, to istnieje dokładnie jeden rozkład stacjonarny ![]() , przy tym
, przy tym ![]() dla każdego
dla każdego ![]() , czyli dla wszystkich stanów istotnych oraz
, czyli dla wszystkich stanów istotnych oraz ![]() dla każdego
dla każdego ![]() ,
czyli dla stanów nieistotnych.
,
czyli dla stanów nieistotnych.
Uwaga 14.1
Podkreślmy stale obowiązujące w tym rozdziale założenie,
że przestrzeń stanów jest skończona. To założenie
jest istotne w Twierdzeniu 14.1 i to samo dotyczy dalszych
rozważań. Istnieją co prawda odpowiedniki sformułowanych tu twierdzeń dla przypadku ogólnej przestrzeni stanów (nieskończonej, a nawet ,,ciągłej” takiej jak ![]() ) ale
wymagają one dodatkowych, niełatwych do sprawdzenia założeń. Przystępny i bardzo elegancki wykład teorii łańcuchów Markowa na ogólnej przestrzeni stanów można
znaleźć w pracy Nummelina [17]. Przeglądowy artykuł Robertsa i Rosenthala [20] zawiera dużo dodatkowych informacji na ten temat.
Obie cytowane prace koncentrują się na tych własnościach łańcuchów, które są istotne z punktu widzenia algorytmów Monte Carlo. Z kolei piękna książka Brémaud
[4] ogranicza się do przestrzeni dyskretnych (skończonych lub przeliczalnych).
) ale
wymagają one dodatkowych, niełatwych do sprawdzenia założeń. Przystępny i bardzo elegancki wykład teorii łańcuchów Markowa na ogólnej przestrzeni stanów można
znaleźć w pracy Nummelina [17]. Przeglądowy artykuł Robertsa i Rosenthala [20] zawiera dużo dodatkowych informacji na ten temat.
Obie cytowane prace koncentrują się na tych własnościach łańcuchów, które są istotne z punktu widzenia algorytmów Monte Carlo. Z kolei piękna książka Brémaud
[4] ogranicza się do przestrzeni dyskretnych (skończonych lub przeliczalnych).
14.2. Regeneracja
Przedstawimy w tym podrozdziale konstrukcję, która prowadzi do łatwch i eleganckich dowodów twierdzeń granicznych. Podstawowa idea jest następująca. Wyróżnia się jeden ustalony stan, powiedzmy ![]() . W każdym momencie wpadnięcia w
. W każdym momencie wpadnięcia w ![]() , następuje ,,odnowienie” i dalsza ewolucja łańcucha jest niezależna od przeszłości.
, następuje ,,odnowienie” i dalsza ewolucja łańcucha jest niezależna od przeszłości.
Niech, dla ![]() ,
,
| (14.1) |
Przyjmujemy przy tym naturalną konwencję: ![]() , jeśli
, jeśli ![]() dla każdego
dla każdego ![]() . Zmienna losowa
. Zmienna losowa ![]() jest więc czasem pierwszego dojścia do stanu
jest więc czasem pierwszego dojścia do stanu ![]() . Jeśli założymy, że łańcuch startuje z punktu
. Jeśli założymy, że łańcuch startuje z punktu ![]() , to
, to ![]() jest czasem pierwszego powrotu.
jest czasem pierwszego powrotu.
Lemat 14.1
Jeżeli łańcuch jest nieprzywiedlny, to istnieją stałe
![]() i
i ![]() takie, że dla dowolnego rozkładu początkowego
takie, że dla dowolnego rozkładu początkowego ![]() ,
,
Dowód
Dla uproszczenia przyjmijmy dodatkowe założenie, że łańcuch jest nieokresowy. Wtedy dla dostatecznie dużych ![]() wszystkie elementy macierzy
wszystkie elementy macierzy ![]() są niezerowe. Ustalmy
są niezerowe. Ustalmy ![]() i znajdźmy liczbę
i znajdźmy liczbę ![]() taką, że
taką, że ![]() dla wszystkich
dla wszystkich ![]() (jest to możliwe, bo łańcuch ma skończoną liczbę stanów). Dla dowolnego
(jest to możliwe, bo łańcuch ma skończoną liczbę stanów). Dla dowolnego ![]() , dobierzmy takie
, dobierzmy takie ![]() , że
, że ![]() . Mamy wówczas
. Mamy wówczas
dla ![]() i
i ![]() .
.
W przypadku łańcucha okresowego dowód nieco się komplikuje i, choć nie jest trudny, zostanie pominięty.
∎Wniosek 14.2
Dla łańcucha nieprzywiedlnego mamy ![]() , co więcej
, co więcej
![]() , co więcej
, co więcej ![]() dla dowolnego
dla dowolnego ![]() , a nawet
, a nawet
![]() przynajmniej dla pewnych dostatecznie małych
wartości
przynajmniej dla pewnych dostatecznie małych
wartości ![]() (w istocie dla
(w istocie dla ![]() ).
).
Podamy teraz bardzo ciekawą interpretację rozkładu stacjonarnego,
wykazując przy okazji jego istnienie (Twierdzenie 14.1). Ustalmy dowolnie wybrany stan ![]() .
Udowodnimy, że średni czas, spędzony przez łańcuch w stanie
.
Udowodnimy, że średni czas, spędzony przez łańcuch w stanie ![]() pomiędzy wyjściem z
pomiędzy wyjściem z ![]() i pierwszym powrotem do
i pierwszym powrotem do ![]() jest proporcjonalny do
jest proporcjonalny do ![]() , prawdopodobieństwa stacjonarnego.
, prawdopodobieństwa stacjonarnego.
Twierdzenie 14.2 (Kaca)
Załóżmy, że łańcuch jest nieprzywiedlny.
Ustalmy ![]() i zdefiniujmy miarę
i zdefiniujmy miarę ![]() wzorem
wzorem
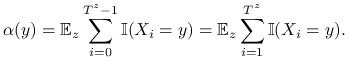 |
Wtedy:
(i) Miara ![]() jest stacjonarna, czyli
jest stacjonarna, czyli ![]() .
.
(ii) Miara ![]() jest skończona,
jest skończona, ![]() .
.
(iii) Unormowana miara ![]() jest jedynym rozkładem stacjonarnym.
jest jedynym rozkładem stacjonarnym.
Dowód
Dla uproszczenia będziemy pisali ![]() ,
, ![]() i
i ![]() . Zauważmy, że
. Zauważmy, że
Udowodnimy teraz (i). Jeśli ![]() , to
, to
ponieważ ![]() , bo
, bo ![]() . Dla
. Dla ![]() mamy z kolei
mamy z kolei
co kończy dowód (i).
Część (ii) jest łatwa. Równość
wynika wprost z definicji miary ![]() . Fakt, że
. Fakt, że ![]() jest wnioskiem z Lematu 14.1.
jest wnioskiem z Lematu 14.1.
Punkt (iii): istnienie rozkładu stacjonarnego
jest natychmiastowym wnioskiem z (i) i (ii). Jednoznaczność rozkładu stacjonarnego dla jest nietrudna do bezpośredniego udowodnienia. Pozostawiamy to jako ćwiczenie. W najbardziej interesującym nas przypadku łańcucha nieokresowego, jednoznaczność wyniknie też ze Słabego Twierdzenia Ergodycznego, które udowodnimy w następnym podrozdziale.
∎Odnotujmy ważny wniosek wynikający z powyższego twierdzenia:
Zjawisko odnowienia, czyli regeneracji pozwala sprowadzić badanie łańcuchów Markowa do rozpatrywania niezależnych zmiennych losowych, a więc do bardzo prostej i dobrze znanej sytuacji. Aby wyjaśnić to bliżej, zauważmy następującą oczywistą równość. Na mocy własności Markowa i jednorodności,
Zatem warunkowo, dla ![]() , łańcuch ,,regeneruje się w momencie
, łańcuch ,,regeneruje się w momencie ![]() ” i zaczyna się
zachowywać dokładnie tak, jak łańcuch który wystartował z punktu
” i zaczyna się
zachowywać dokładnie tak, jak łańcuch który wystartował z punktu ![]() w chwili
w chwili ![]() .
Niezależnie od przeszłości! Ponieważ
.
Niezależnie od przeszłości! Ponieważ ![]() jest ustalone, będziemy odtąd pomijali
górny indeks przy
jest ustalone, będziemy odtąd pomijali
górny indeks przy ![]() . Zdefiniujmy kolejne momenty odnowienia, czyli czasy
odwiedzin stanu
. Zdefiniujmy kolejne momenty odnowienia, czyli czasy
odwiedzin stanu ![]() :
:
Momenty ![]() dzielą trajektorię łańcucha na następujące ,,losowe wycieczki”, czyli losowej długości ciągi zmiennych losowych:
dzielą trajektorię łańcucha na następujące ,,losowe wycieczki”, czyli losowej długości ciągi zmiennych losowych:
|
|
|
|
|
Wycieczka zaczyna się w punkcie ![]() i kończy tuż przed powrotem do
i kończy tuż przed powrotem do ![]() . Oznaczmy
. Oznaczmy ![]() -tą wycieczkę symbolem
-tą wycieczkę symbolem
![]() :
:
Z tego, co powiedzieliśmy wcześniej wynika, że wszystkie ,,wycieczki” są niezależne.
Co więcej wycieczki ![]() mają ten sam rozkład, z wyjątkiem być może początkowej, czyli
mają ten sam rozkład, z wyjątkiem być może początkowej, czyli ![]() .
Jeśli rozkład początkowy jest skupiony w punkcie
.
Jeśli rozkład początkowy jest skupiony w punkcie ![]() , to również wycieczka
, to również wycieczka ![]() ma ten
sam rozkład (0 jest wtedy momentem odnowienia).
ma ten
sam rozkład (0 jest wtedy momentem odnowienia).
Podejście regeneracyjne, czyli rozbicie łańcucha na niezależne wycieczki prowadzi do ładnych i łatwych dowodów
PWL i CTG dla łańcuchów Markowa.
Sformułujemy najpierw pewną wersję Mocnego Prawa Wielkich Liczb. Rozważmy funkcję ![]() o wartościach rzeczywistych, określoną na przestrzeni stanów. Przypomnijmy,
że
o wartościach rzeczywistych, określoną na przestrzeni stanów. Przypomnijmy,
że ![]() .
.
Twierdzenie 14.3 (Mocne Twierdzenie Ergodyczne)
Jeśli ![]() jest nieprzywiedlnym łańcuchem Markowa, to dla dowolnego
rozkładu początkowego
jest nieprzywiedlnym łańcuchem Markowa, to dla dowolnego
rozkładu początkowego ![]() i każdej funkcji
i każdej funkcji ![]() ,
,
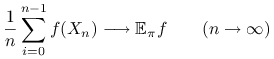 |
z prawdopodobieństwem 1.
Dowód
Zdefiniujmy sumy blokowe:
Niech ![]() , czyli
, czyli ![]() jest ostatnią regeneracją przed momentem
jest ostatnią regeneracją przed momentem ![]() :
:
|
|
|||
|
|
|||
|
|
Oczywiście,
| (14.2) |
Wiemy, że ![]() . Ponieważ
. Ponieważ ![]() jest sumą
jest sumą ![]() niezależnych zmiennych losowych (długości wycieczek) to wnioskujemy, ze
niezależnych zmiennych losowych (długości wycieczek) to wnioskujemy, ze ![]() z prawdopodobieństwem 1, na mocy zwykłego Prawa Wielkich Liczb.
Rzecz jasna, tak samo
z prawdopodobieństwem 1, na mocy zwykłego Prawa Wielkich Liczb.
Rzecz jasna, tak samo ![]() . Podzielmy nierówność (14.2) stronami przez
. Podzielmy nierówność (14.2) stronami przez ![]() i przejdźmy do granicy (korzystając z tego, że
i przejdźmy do granicy (korzystając z tego, że ![]() prawie na pewno). Twierdzenie o trzech ciągach pozwala wywnioskować, że
prawie na pewno). Twierdzenie o trzech ciągach pozwala wywnioskować, że
Załóżmy teraz, że ![]() i powtórzmy bardzo podobne rozumowanie dla sum
i powtórzmy bardzo podobne rozumowanie dla sum
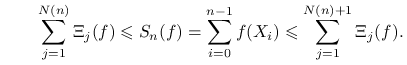 |
(14.3) |
Po lewej i po prawej stronie mamy sumy niezależnych składników ![]() . Korzystamy z PWL dla niezależnych zmiennych, dzielimy (14.3) stronami przez
. Korzystamy z PWL dla niezależnych zmiennych, dzielimy (14.3) stronami przez ![]() i przejchodzimy do granicy. Otrzymujemy
i przejchodzimy do granicy. Otrzymujemy
a więc
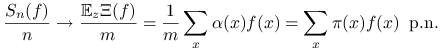 |
Ostatnia równość wynika z Twierdzenia Kaca. Przypomnijmy, że ![]() jest ,,średnim czasem spędzonym w
stanie
jest ,,średnim czasem spędzonym w
stanie ![]() ” podczas pojedynczej wycieczki.
” podczas pojedynczej wycieczki.
Jeśli funkcja ![]() nie jest nieujemna, to możemy zastosować
rozkład
nie jest nieujemna, to możemy zastosować
rozkład ![]() i wykorzystać już udowodniony wynik.
i wykorzystać już udowodniony wynik.
Na podobnej idei oparty jest ,,regeneracyjny” dowód Centralnego Twierdzenia Granicznego (istnieją też zupełnie inne dowody).
Twierdzenie 14.4 (Centralne Twierdzenie Graniczne)
Jeśli ![]() jest łańcuchem nieprzywiedlnym, to dla dowolnego rozkładu
początkowego
jest łańcuchem nieprzywiedlnym, to dla dowolnego rozkładu
początkowego ![]() i każdej funkcji
i każdej funkcji ![]() ,
,
![\frac{1}{\sqrt{n}}\left(\sum _{{i=0}}^{{n-1}}[f(X_{{i}})-\mathbb{E}_{\pi}f]\right)\longrightarrow _{d}{\rm N}\big(0,{\sigma _{{\rm as}}^{{2}}(f)}\big),\quad(n\to\infty).](wyklady/sst/mi/mi1541.png) |
Ponadto, dla dowolnego rozkładu początkowego ![]() zachodzi wzór (10.4), czyli
zachodzi wzór (10.4), czyli ![]()
![]() przy
przy ![]() .
.
Szkic dowodu
Trochę więcej jest tu technicznych zawiłości niż w dowodzie PWL, wobec tego zdecydowałem się pominąć szczegóły. W istocie, przedstawię tylko bardzo pobieżnie główną ideę. Bez straty ogólności załóżmy, że ![]() .
Tak jak w dowodzie PWL, sumę
.
Tak jak w dowodzie PWL, sumę ![]() przybliżamy sumą niezależnych składników, które
odpowiadają całkowitym wycieczkom:
przybliżamy sumą niezależnych składników, które
odpowiadają całkowitym wycieczkom: ![]() . Ze zwykłego CTG dla niezależnych zmiennych o jednakowym rozkładzie otrzymujemy
. Ze zwykłego CTG dla niezależnych zmiennych o jednakowym rozkładzie otrzymujemy
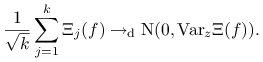 |
Jeśli ,,podstawimy” w miejsce ![]() zmienną losową
zmienną losową ![]() i wykorzystamy fakt, że
i wykorzystamy fakt, że ![]() (PWL
gwarantuje, że
(PWL
gwarantuje, że ![]() ), to nie powinien dziwić następujący wniosek:
), to nie powinien dziwić następujący wniosek:
W ten sposób ,,otrzymujemy” tezę.
∎Przytoczony powyżej rozumowanie daje ciekawe przedstawienie asymptotycznej wariancji:
| (14.4) |
Istnieje wiele wyrażeń na asymptotyczną wariancję, przy tym różne wzory wymagają
różnych założeń. Najbardziej znany jest wzór (10.5). Sformułujemy w jawny sposób
potrzebne założenia, i przepiszemy ten wzór w postaci macierzowej. Najpierw musimy wprowadzić jeszcze parę nowych oznaczeń. Wygodnie będzie utożsamić funkcję ![]() z wektorem kolumnowym
z wektorem kolumnowym
![f=\left(\begin{array}[]{c}f(1)\cr\vdots\cr f(d)\cr\end{array}\right).](wyklady/sst/mi/mi1572.png) |
Niech
gdzie ![]() oznacza, jak zwykle, rozkład stacjonarny. Możemy teraz napisać
oznacza, jak zwykle, rozkład stacjonarny. Możemy teraz napisać
oraz
Podobnie,
W powyższym wzorze, ![]() jest macierzą identycznościową,
jest macierzą identycznościową, ![]() oznacza kolumnę jedynek.
Łatwo sprawdzić, że
oznacza kolumnę jedynek.
Łatwo sprawdzić, że ![]() dla
dla ![]() (ale nie dla
(ale nie dla ![]() ).
Jeśli
).
Jeśli ![]() jest macierzą przejścia
nieprzywiedlnego i nieokresowego łańcucha Markowa, to
jest macierzą przejścia
nieprzywiedlnego i nieokresowego łańcucha Markowa, to ![]() przy
przy ![]() na mocy Słabego Twierdzenia Ergodycznego. Stąd wynika zbieżność następujących szeregów:
na mocy Słabego Twierdzenia Ergodycznego. Stąd wynika zbieżność następujących szeregów:
Macierz ![]() nazywamy macierzą fundamentalną.
Ponieważ
nazywamy macierzą fundamentalną.
Ponieważ ![]() zaś
zaś ![]() więc
więc ![]() .
.
Stwierdzenie 14.1 (Asymptotyczna wariancja)
Jeśli łańcuch jest nieprzywiedlny i nieokresowy, to zachodzi wzór (10.5), czyli
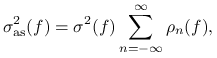 |
gdzie ![]() i
i ![]() ,
W postaci macierzowej asymptotyczna wariancja wyraża się następująco
,
W postaci macierzowej asymptotyczna wariancja wyraża się następująco
Szkic dowodu
Załóżmy, że rozkładem początkowym jest ![]() i skorzystamy ze stacjonarności łańcucha:
i skorzystamy ze stacjonarności łańcucha:
Poprawność przejścia do granicy w ostatniej linijce wynika z elementarnego faktu, że dla
dowolnego ciągu liczbowego ![]() mamy
mamy
![]() , o ile szereg
po prawej stronie równości jest zbieżny. To zaś, przy założeniu nieprzywiedlności
i nieokresowości, wynika ze STE (skorzystaliśmy już z tego faktu uzasadniając poprawność
definicji
, o ile szereg
po prawej stronie równości jest zbieżny. To zaś, przy założeniu nieprzywiedlności
i nieokresowości, wynika ze STE (skorzystaliśmy już z tego faktu uzasadniając poprawność
definicji ![]() i
i ![]() ).
).
Pokazaliśmy w ten sposób, że ![]() zmierza do granicy, która jest
równa prawej stronie wzoru (10.5). Pominiemy uzasadnienie, że można zastąpić rozkład stacjonarny
zmierza do granicy, która jest
równa prawej stronie wzoru (10.5). Pominiemy uzasadnienie, że można zastąpić rozkład stacjonarny
![]() przez dowolny rozkład początkowy
przez dowolny rozkład początkowy ![]() oraz że wzór (10.5) definiuje tę samą wielkość co
(14.4).
oraz że wzór (10.5) definiuje tę samą wielkość co
(14.4).
Macierzowe wyrażenia ![]() wynikają ze wzorów na kowariancje oraz z określenia macierzy
wynikają ze wzorów na kowariancje oraz z określenia macierzy ![]() i
i ![]() .
.
Zauważmy, że ani CTG ani PWL nie wymagały założenia o nieokresowości ale w 14.1 to założenie jest potrzebne.
Jak widać, asymptotyczna wariancja wyraża się w postaci formy kwadratowej
![]() o współczynnikach
o współczynnikach
Okazuje się, że ,,asymptotyczne obiążenie” estymatora ![]() wartości oczekiwanej
wartości oczekiwanej ![]() można napisać w postaci formy dwuliniowej
można napisać w postaci formy dwuliniowej
![]() , gdzie
, gdzie ![]() jest rozkładem początkowym. Podsumowując,
jest rozkładem początkowym. Podsumowując,
Uzasadnienie drugiej części powyższego wzoru pozostawiam jako ćwiczenie. Stąd z łatwością otrzymujemy ważny wzór (10.6) z Rozdziału 10 (wyrażenie na błąd średniokwadratowy).
14.3. Łańcuchy sprzężone i zbieżność rozkładów
Dowód Słabego Twierdzenia Ergodycznego, który przedstawimy, opiera się na tak zwanym sprzęganiu (ang. coupling), czyli metodzie ,,dwóch cząstek”. Ta metoda, jak się okaże, nie tylko pozwala udowodnić zbieżność rozkładów prawdopodobieństwa, ale daje w wielu przypadkach bardzo dobre oszacowania szybkości zbieżności.
14.3.1. Odległość pełnego wahania
Najpierw zajmiemy się określeniem odległości między rozkładami.
Dla naszych celów najbardziej przydatna będzie następująca metryka.
Niech ![]() i
i ![]() będą dwoma rozkładami prawdopodobieństwa na skończonej przestrzeni
będą dwoma rozkładami prawdopodobieństwa na skończonej przestrzeni ![]() .
Odległość pełnego wahania pomiędzy
.
Odległość pełnego wahania pomiędzy ![]() i
i ![]() określamy wzorem
określamy wzorem
| (14.5) |
Jak zwykle, możemy utożsamić rozkład prawdopodobieństwa na ![]() z funkcją, przypisującą prawdopodobieństwa
pojedynczym punktom
z funkcją, przypisującą prawdopodobieństwa
pojedynczym punktom ![]() . Zauważmy, że
. Zauważmy, że
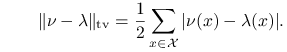 |
(14.6) |
Istotnie, ponieważ rozpatrujemy dwie miary probabilistyczne, dla których ![]() , więc
, więc
![]() dla
dla ![]() . Ale
. Ale
![]() .
.
Dla zmiennej losowej ![]() napis
napis ![]() będzie oznaczał fakt, że
będzie oznaczał fakt, że ![]() ma rozkład prawdopodobieństwa
ma rozkład prawdopodobieństwa ![]() , czyli
, czyli ![]() ,
,
Lemat 14.2
Jeżeli ![]() są dwiema zmiennymi losowymi określonymi na tej samej przestrzeni probabilistycznej i
są dwiema zmiennymi losowymi określonymi na tej samej przestrzeni probabilistycznej i ![]() i
i ![]() , to
, to
Dowód
Niech ![]() . Dla dowolnego
. Dla dowolnego ![]() mamy
mamy
Symetrycznie, ![]() . Zatem
. Zatem ![]() .
.
Interesujące jest, że Lemat 14.2 daje się, w pewnym sensie, odwrócić. Co prawda, to nie będzie potrzebne w dowodzie Słabego Twioerdzenia Ergodycznego, ale później okaże się bardzo pomocne.
Lemat 14.3
Jeżeli ![]() i
i ![]() są rozkładami prawdopodobieństwa na
są rozkładami prawdopodobieństwa na ![]() ,
to istnieją zmienne losowe
,
to istnieją zmienne losowe ![]() i
i ![]() określone na tej samej przestrzeni probabilistycznej, takie, że
określone na tej samej przestrzeni probabilistycznej, takie, że ![]() i
i ![]() i
i
Dowód
Niech ![]() . Bez straty ogólności możemy przyjąć, że
. Bez straty ogólności możemy przyjąć, że ![]() i
i ![]() są zmiennymi losowymi określonymi na przestrzeni probabilistycznej
są zmiennymi losowymi określonymi na przestrzeni probabilistycznej ![]() . Należy podać łączny rozkład zmiennych losowych
. Należy podać łączny rozkład zmiennych losowych
![]() i
i ![]() , czyli miarę probabilistyczną
, czyli miarę probabilistyczną ![]() na
na ![]() taką, że
taką, że
![]() ,
, ![]() i
i ![]() .
.
Niech
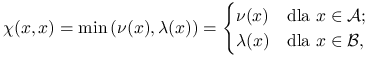 |
gdzie ![]() i
i ![]() .
.
Mamy oczywiście ![]() i jest jasne, że tabelka łącznego rozkładu
i jest jasne, że tabelka łącznego rozkładu ![]() musi być postaci macierzy blokowej
musi być postaci macierzy blokowej
![\qquad\begin{array}[]{r c c}\scriptstyle{x\in{\cal A}}\ \Big\{&D_{{\cal A}}&0\\
\scriptstyle{x\in{\cal B}}\ \Big\{&G&D_{{\cal B}}\\
&\underbrace{\phantom{--}}_{{y\in{\cal A}}}&\underbrace{\phantom{--}}_{{y\in{\cal B}}}\end{array},](wyklady/sst/mi/mi1634.png) |
gdzie ![]() i
i ![]() są macierzami diagonalnymi. Pozostaje tylko odpowiednio ,,rozmieścić pozostałą masę prawdopodobieństwa”
są macierzami diagonalnymi. Pozostaje tylko odpowiednio ,,rozmieścić pozostałą masę prawdopodobieństwa” ![]() w macierzy
w macierzy ![]() . Możemy na przykład przyjąć, dla
. Możemy na przykład przyjąć, dla ![]() i
i ![]() ,
,
Mamy wtedy ![]() , więc
, więc
![]() dla
dla
![]() i podobnie
i podobnie ![]() dla
dla
![]() . Określony przez nas rozkład łączny
. Określony przez nas rozkład łączny ![]() ma więc masę
ma więc masę
![]() na przekątnej i żądane rozkłady brzegowe.
na przekątnej i żądane rozkłady brzegowe.
14.3.2. Sprzęganie
Rozważmy ,,podwójny” łańcuch Markowa ![]() na przestrzeni
stanów
na przestrzeni
stanów ![]() . Przypuśćmy, że każda z dwóch ,,współrzędnych”,
oddzielnie rozpatrywana, jest łańcuchem o macierzy przejścia
. Przypuśćmy, że każda z dwóch ,,współrzędnych”,
oddzielnie rozpatrywana, jest łańcuchem o macierzy przejścia ![]() .
Mówiąc dokładniej, zakładamy, że
.
Mówiąc dokładniej, zakładamy, że
gdzie macierz przejścia ![]() podwójnego łańcucha spełnia
następujące warunki:
podwójnego łańcucha spełnia
następujące warunki:
| (14.7) |
Widać, że ![]() jest łańcuchem Markowa z
prawdopodobieństwami przejścia
jest łańcuchem Markowa z
prawdopodobieństwami przejścia ![]() i to samo można powiedzieć o
i to samo można powiedzieć o
![]() . Załóżmy ponadto, że od momentu, gdy
oba łańcuchy się spotkają, dalej ,,poruszają się” już razem.
Innymi słowy,
. Załóżmy ponadto, że od momentu, gdy
oba łańcuchy się spotkają, dalej ,,poruszają się” już razem.
Innymi słowy,
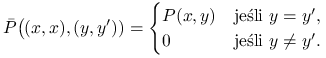 |
Nazwiemy konstrukcję takiej pary sprzęganiem łańcuchów (bardziej znany jest angielski termin coupling).
Oznaczmy przez ![]() moment spotkania się łańcuchów:
moment spotkania się łańcuchów:
| (14.8) |
Podstawową rolę odgrywa następujące spostrzeżenie:
| (14.9) |
Jeśli teraz łańcuch ![]() ,,wystartuje” z rozkładu stacjonarnego, czyli
,,wystartuje” z rozkładu stacjonarnego, czyli ![]() to
to
![]() dla każdego
dla każdego ![]() i otrzymujemy
i otrzymujemy
| (14.10) |
Aby udowodnić zbieżność ![]() wystarczy skonstruować
parę łańcuchów sprzężonych, które się spotkają z prawdopodobieństwem 1:
wystarczy skonstruować
parę łańcuchów sprzężonych, które się spotkają z prawdopodobieństwem 1: ![]() . Możemy teraz udowodnić
(10.1), przynajmniej dla łańcuchów na skończonej przestrzeni stanów.
. Możemy teraz udowodnić
(10.1), przynajmniej dla łańcuchów na skończonej przestrzeni stanów.
Twierdzenie 14.5 (Słabe Twierdzenie Ergodyczne)
Jeśli łańcuch Markowa na skończonej przestrzeni stanów jest nieprzywiedlny i nieokresowy, to
| (14.11) |
Dowód
Rozważmy parę łańcuchów sprzężonych, które poruszają się niezależnie aż do momentu spotkania.
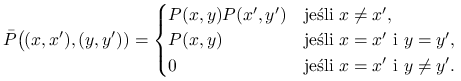 |
(14.12) |
Żeby pokazać, że ![]() wystarczy zauważyć, że do przed momentem spotkania,
łańcuch podwójny ewoluuje zgodnie z prawdopodobieństwami przejścia
wystarczy zauważyć, że do przed momentem spotkania,
łańcuch podwójny ewoluuje zgodnie z prawdopodobieństwami przejścia
| (14.13) |
Łańcuch odpowiadający ![]() jest nieprzywiedlny. Istotnie, możemy znaleźć takie
jest nieprzywiedlny. Istotnie, możemy znaleźć takie ![]() , że
dla
, że
dla ![]() wszystkie elementy macierzy
wszystkie elementy macierzy ![]() są niezerowe. Stąd
są niezerowe. Stąd
![]() dla dowolnych
dla dowolnych ![]() .
Wystarczy teraz powołać się na Wniosek 14.2: podwójny łańcuch z prawdopodobieństwem 1 prędzej czy później dojdzie do każdego punktu przestrzeni
.
Wystarczy teraz powołać się na Wniosek 14.2: podwójny łańcuch z prawdopodobieństwem 1 prędzej czy później dojdzie do każdego punktu przestrzeni ![]() , a zatem musi dojść do
,,przekątnej”
, a zatem musi dojść do
,,przekątnej” ![]() .
.
Uwaga 14.2
W dowodzie Twierdzenia 14.5 wykorzystaliśmy w istotny sposób nieokresowość
macierzy przejścia ![]() (dla pojedynczego łańcucha), choć to mogło nie być
wyraźnie widoczne. Jeśli
(dla pojedynczego łańcucha), choć to mogło nie być
wyraźnie widoczne. Jeśli ![]() jest nieprzywiedlna ale okresowa, wtedy
jest nieprzywiedlna ale okresowa, wtedy ![]() jest nieprzywiedlna. Na przykład, niech
jest nieprzywiedlna. Na przykład, niech ![]() i
i
Wtedy, oczywiście, ![]() bo
bo ![]() dla nieparzystych
dla nieparzystych ![]() zaś
zaś
![]() dla parzystych
dla parzystych ![]() .
.
Ten sam trywialny przykład pokazuje, że dla łańcuchów okresowych teza Słabego Twierdzenia Ergodycznego nie jest prawdziwa.
W istocie, przytoczony przez nas dowód Twierdzenia 14.5 daje nieco więcej, niż tylko zbieżność rozkładów. Z Wniosku 14.2 wynika, że
| (14.14) |
dla pewnych stałych ![]() i
i ![]() . Dla naszych celów takie ogólnikowe
stwierdzenie nie jest wystarczające. Skupimy się na przykładach łańcuchów używanych w algorytmach MCMC, dla których znajdziemy jawne oszacowania, z konkretnymi stałymi.
Zobaczymy, że użycie niezależnych kopii łańcucha w dowodzie Twierdzenia
14.5, wzór (14.12) jest konstrukcją dalece nieoptymalną. W wielu przykładach istnieją łańcuchy sprzężone znacznie szybciej ,,zmierzające do spotkania”.
. Dla naszych celów takie ogólnikowe
stwierdzenie nie jest wystarczające. Skupimy się na przykładach łańcuchów używanych w algorytmach MCMC, dla których znajdziemy jawne oszacowania, z konkretnymi stałymi.
Zobaczymy, że użycie niezależnych kopii łańcucha w dowodzie Twierdzenia
14.5, wzór (14.12) jest konstrukcją dalece nieoptymalną. W wielu przykładach istnieją łańcuchy sprzężone znacznie szybciej ,,zmierzające do spotkania”.
Przykład 14.1 (Błądzenie po kostce)
Niech ![]() i
i ![]() , czyli
, czyli ![]() dla każdego
dla każdego ![]() .
Rozważmy łańcuch Markowa
.
Rozważmy łańcuch Markowa ![]() , którego krok polega na wylosowaniu jednej, losowo wybranej współrzędnej z rozkładu
, którego krok polega na wylosowaniu jednej, losowo wybranej współrzędnej z rozkładu ![]() na zbiorze
na zbiorze ![]() i
pozostawieniu pozostałych współrzędnych bez zmian. Formalnie,
i
pozostawieniu pozostałych współrzędnych bez zmian. Formalnie,
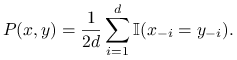 |
Jest to zatem ,,losowe błądzenie” wzdłuż krawędzi ![]() -wymiarowej kostki lub inaczej próbnik Gibbsa.
Rzecz jasna, dokładne genrowanie z rozkładu jednostajnego na kostce jest łatwe i nie ptrzebujemy do
tego łańcuchów Markowa, ale nie o to teraz chodzi. Chcemy zilustrować jak metoda sprzęgania pozwala oszacować szybkość zbieżności łańcucha na możliwie
prostym przykładzie. Skonstruujmy parę łańcuchów sprzężonych w taki sposób: wybieramy współrzędną
-wymiarowej kostki lub inaczej próbnik Gibbsa.
Rzecz jasna, dokładne genrowanie z rozkładu jednostajnego na kostce jest łatwe i nie ptrzebujemy do
tego łańcuchów Markowa, ale nie o to teraz chodzi. Chcemy zilustrować jak metoda sprzęgania pozwala oszacować szybkość zbieżności łańcucha na możliwie
prostym przykładzie. Skonstruujmy parę łańcuchów sprzężonych w taki sposób: wybieramy współrzędną ![]() oraz losujemy jej nową wartość z rozkładu
oraz losujemy jej nową wartość z rozkładu ![]() po
czym zmieniamy w ten sam sposób obie kopie. Formalnie,
po
czym zmieniamy w ten sam sposób obie kopie. Formalnie,
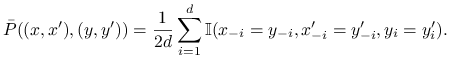 |
Jest jasne, że to jest poprawny coupling (sprzęganie), to znaczy spełnione są równania (14.12). Spotkanie obu kopii nastąpi najpóźniej w momencie gdy każda ze współrzędnych zostanie wybrana przynajmniej raz. Zatem
Nie trudno wyobrazić sobie, że dla niezależnego couplingu określonego wzorem (14.12), czasu oczekiwania na spotkanie obu kopii jest na ogół dużo, dużo dłuższy.


