Zagadnienia
2. Problem klasyfikacji i klasyfikatory
2.1. Problem klasyfikacji i klasyfikatory
2.1.1. Wprowadzenie
-
Założenie: Dany jest skończony zbiór obiektów
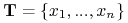 . Ten zbiór nazywamy zbiorem treningowym
. Ten zbiór nazywamy zbiorem treningowym-
Każdy obiekt (rekord) jest opisany wektorem informacyjnym, składającym się z wartości pochodzących z dziedziny pewnych atrybutów warunkowych.
-
Wyróżniony jest jeden atrybut, zwany też atrybutem decyzyjnym
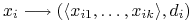
-
-
Cel: wyznaczyć klasę decyzyjną, do której należy nowy nieznany dotąd obiekt.
-
Jak? Znaleźć zależność (najlepiej funkcyjną) między atrybutem decyzyjnym a atrybutami warunkowymi.
-
Tworzenie modelu: opisywanie klas decyzyjnych
-
Klasa decyzyjna = zbiór obiektów mających taką samą wartość na atrybucie decyzyjnym
-
Klasyfikator: algorytm określenia klasy decyzyjnej obiektów za pomocą ich wartości na atrybutach warunkowych.
-
Klasyfikatory mogą być opisane za pomocą formuł logicznych, drzew decyzyjnych lub formuł matematycznych.
-
-
Korzystanie z modelu do przypisanie nowym nieznanym obiektom ich klasy decyzyjne.
Problem: Jak oceniać model?
-
Wiele problemów decyzyjnych można opisać jako problem klasyfikacji
-
DSS (Decision Support System) jest systemem komputerowym dostarczającym narzędzia do rozwiązywania problemów klasyfikacji.
- Wejście:
-
Zbiór treningowy
- Wyjście:
-
Klasyfikator(y)
-
Wymagania:
-
Szybkość podejmowania decyzji, skalowalność
-
Skuteczność
-
Racjonalność
-
Możliwość współpracy z ekspertem: doradztwo, adaptacja, negocjacja, adopcja wiedzy eksperskiej, …
-
2.1.2. Przegląd metod klasyfikacji
2.1.2.1. Metody oparte o przykłady
-
Są to metody leniwej klasyfikacji, które opóźniają proces przetwarzania danych aż do momentu kiedy pojawi się nowy obiekt do klasyfikowania
-
Typowe metody:
-
 k-nearest neighbor approach
k-nearest neighbor approach-
 Przykłady treningowe są przedstawione jako punkty w metrycznej przestrzeni.
Przykłady treningowe są przedstawione jako punkty w metrycznej przestrzeni.
-
-
Locally weighted regression
-
Konstruuje lokalne aproksymacje pojęć
-
-
Case-based reasoning
-
Korzysta z symbolicznych reprezentacji i metod wnioskowania w oparciu o bazę wiedzy
-
-
algorytm najbliższych sąsiadów
- Input:
-
Tablica decyzyjna
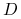 , nowy obiekt
, nowy obiekt 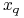
- Output:
-
Klasa decyzyjna, do której należy
(czyli 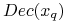 )
) - Krok 1:
-
Szukaj w zbiorze
, 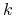 najbliżej położonych obiektów
najbliżej położonych obiektów 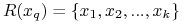
- Krok 2:
-
Wyznacz klasę dla
na podstawie 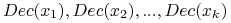
0.4
0.59
\column
-
Najczęściej wykorzystany dla danych z atrybutami numerycznymi
-
Wymagania:
-
Zbiór treningowy
-
Funkcja odległości między obiektami
-
Wartość parametru
, liczba rozpatrywanych sąsiadów
-
-
Podczas klasyfikacji:
-
Wyznaczanie k najbliższych sąsiadów
-
Wyznaczenie klasy decyzyjnej nowego obiektu na podstawie klas decyzyjnych najbliższych sąsiadów (np. przez głosowanie).
-
-
Jest to przykład metody leniwej, gdyż
-
Nie buduje jawnego modelu wiedzy
-
Proces klasyfikacji może być czasochłonny
-
-
Jeśli k jest za mała, klasyfikator będzie wrażliwa na drobne szumy w danych
-
Jeśli k jest zbyt duża:
-
Wysoka złożoność obliczeniowa
-
Otoczenia mogą zawierać obiekty z innych klas
-
-
Algorytm k-NN dla ciągłej decyzji
-
Wystarczy obliczyć średnią z decyzji najbliższych sąsiadów
-
-
Problem skalowania atrybutów
-
Np. opis człowieka:
-
(Wzrost [m], Waga [kg], Klasa)
-
Wzrost odchyla się od 1.5 m do 1.85 m
-
Waga może mieć wartość od 45 kg do 120 kg
Odległość euklidesowa jest bardziej wrażliwa na różnicę wag niż różnicę wzrostu.
-
-
-
Przekleństwo wymiarów
-
Może produkować wyniki niezgodne z intuicją (np. klasyfikacji dokumentów)
-
Rozwiązanie: Normalizacja
-
-
Sąsiedzi ważeni względem odległośc
-
Wpływ sąsiada
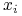 na obiekt testowy jest ważony przez
na obiekt testowy jest ważony przez 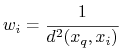
-
Bliżsi sąsiedzi mają większy wpływ
-
2.1.2.2. Wnioskowanie Bayesowskie
\columns\column0.6
-
Dany jest zbiór treningowy
, prawdopodobieństwo posteriori hipotezy 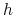 –
– 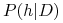 – można liczyć wzorem Bayesa.
– można liczyć wzorem Bayesa.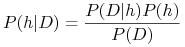
-
MAP (maximum posteriori) hypothesis
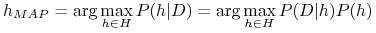
-
Trudności: ta metoda wymaga znajomości wielu rozkładów prawdopodobieństw
 wysoki koszt obliczeniowy
wysoki koszt obliczeniowy
0.39
-
Klasyfikacja obiektu opisanego przez
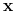
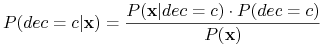
-
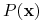 jest wspólna dla wszystkich hipotez;
jest wspólna dla wszystkich hipotez; -
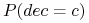 – częstość występowania klasy
– częstość występowania klasy 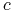 ;
; -
Znaleźć
tak, że 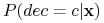 było maksymalne, czyli, aby
było maksymalne, czyli, aby 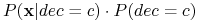 było maksymalne;
było maksymalne; -
Problem: obliczenie
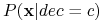 jest czasochłonne!
jest czasochłonne!
-
Naiwne założenie: atrybuty są warunkowo niezależne!
Wówczas
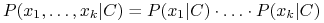
-
Czyli
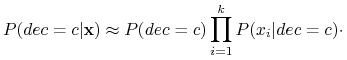
To założenie znacznie obniża złożoność obliczeniowy.
-
Nowy obiekt
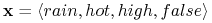
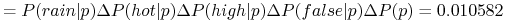
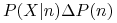
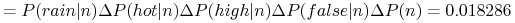
-
X jest klasyfikowany do klasy n (don’t play)
-
Założenie o niezależności:
-
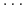 powoduje, że obliczenia staje się możliwe
powoduje, że obliczenia staje się możliwe
-
optymalny klasyfikator o ile ono jest prawdziwe
-
ale warunek bardzo rzadko spełniony w praktyce (atrybuty są często korelowane).
-
-
Próby pokonania te ograniczenia:
-
Sieci Bayesowskie, które łączą metody wnioskowania Bayesowskiego z zależnościami między atrybutami
-
Drzewa decyzyjne, które przeprowadzają dedukcyjne kroki na pojedyńczych atrybutach, począwszy od najważniejszego
-
-
Sieci Bayesowskie dopuszczają “warunkową niezależność” podzbiorów zmiennych.
-
Jest to graficzny model zależności przyczynowo-skutkowych
-
Naive Bayes jest szczególnym przypadkiem sieci Bayesowskiej (jakim?)
-
Problemy związane uczeniem sieci Bayesowskich:
-
Prypadek najłatwiejszy: zarówno struktura sieci, jak i wszystkie zmienne są znane.
-
Znana jest struktura, ale brakuje rozkładów zmiennych.
-
Nawet struktura sieci nie jest z góry zadana.
-
Ogólna formuła
![]()


