13. Gry iterowane
13.1. Motywacje
Używa się też nazwy gry powtarzane (repeated games, infinitely repeated games, iterated games).
W świecie realnym podmioty interakcji, gracze często wchodzą w interakcje z tymi samymi przeciwnikami, partnerami. Perspektywa przyszłych interakcji z tym samym graczem może istotnie wpływać na wybór strategii graczy.
Gry powtarzane opisują np. sytuacje wielokrotnych interakcji społecznych, altruizmu, kary etc. Gracz musi uwzględnić wpływ granej akcji na przyszłe akcje przeciwników. Pojedyńcza interakcja jest opisywana pewną grą strategiczną (stage game, one–shot game). Gracze wielokrotnie powtarzają tę grę, podejmując za każdym razem decyzję o wyborze akcji jednocześnie (ogólniej–nie znając decyzji pozostałych graczy), natomiast znając poprzednie akcje pozostałych graczy.
Jest wiele przykładów powtarzalnych interakcji z których każda jest np. opisywana tą samą jednokrotną grą strategiczną i które nie mają określonego terminu zakończenia, horyzontu czasowego. Z drugiej strony w wielu przypadkach termin zakończenia takich interakcji nie odgrywa istotnej roli w planowaniu strategii graczy. W takich przypadkach model z nieskończona liczbą interakcji może być lepszy do opisu strategii graczy.
Gry iterowane dzielimy na skończone i nieskończone. Gra skończona to ciąg skończenie ![]() razy powtarzanej
gry jednokrotnej, przy czym
razy powtarzanej
gry jednokrotnej, przy czym ![]() jest znaną liczbą.
jest znaną liczbą.
Przykład 13.1
n-krotny Dylemat Więźnia.
Metoda indukcji wstecznej zastosowana do równoważnej EGwII pokazuje że racjonalny gracz gra defekcję w każdej grze pojedynczej.
Gra nieskończona (będziemy uzywać skrótu GN lub GI: Gra Iterowana) to nieskończony ciag takich gier. Będziemy zajmowali się powtarzanymi grami nieskończonymi. Motywacją do ich wprowadzenia jest np. fakt że w wielu sytuacjach nie znamy liczby przyszłych interakcji.
Ponieważ nie można zastosować metody indukcji wstecznej, więc w nieskończonym Dylemacie Więźnia nie jest oczywiste jakie akcje powinien podejmować racjonalny gracz–świadomość kary w przyszłych grach za defekcję w pewnej chwili (czyli obniżenia wypłaty) może spowodować wybór kooperacji.
Wypłaty będziemy opisywać jako sumę wypłat z gier pojedynczych. Aby uniknąć wypłat nieskończonych wprowadzimy
czynnik dyskontujący wypłaty. Formalnie będzie to odpowiadało sytuacji gdy po każdej grze
pojedynczej jest niezerowe prawdopodobieństwo ![]() że bedzie grana nastepna gra pojedyncza. Wartość oczekiwana liczby takich gier jest wtedy równa
że bedzie grana nastepna gra pojedyncza. Wartość oczekiwana liczby takich gier jest wtedy równa ![]() .
.
Przykład 13.2
Iterowany Dylemat Więźnia (IDW) (Iterated Prisoner's Dilemma, IPD)
Jest to najbardziej–ze względu na zastosowania–popularny przykład gry nieskończenie powtarzanej. Gdy nie jest
explicite
powiedziane inaczej, wyjściową grą pojedyńczą jest dwuosobowy Dylemat Więźnia ![]() . Aby utrzymywanie
kooperacji było bardziej opłacalne niż naprzemienne zdradzanie i kooperowanie, zakłada się dodatkowo że
. Aby utrzymywanie
kooperacji było bardziej opłacalne niż naprzemienne zdradzanie i kooperowanie, zakłada się dodatkowo że ![]() .
.
13.2. Definicje
Niech GS=![]() będzie grą strategiczną, rozgrywaną w dyskretnych chwilach
czasu
będzie grą strategiczną, rozgrywaną w dyskretnych chwilach
czasu ![]() (stage game).
Zakładamy że w chwili
(stage game).
Zakładamy że w chwili ![]() gracze znają akcje przeciwników podejmowane w
gracze znają akcje przeciwników podejmowane w ![]() . Założenie to będzie w szczególności
potrzebne do zdefiniowania strategii graczy. Oznaczmy
. Założenie to będzie w szczególności
potrzebne do zdefiniowania strategii graczy. Oznaczmy
–profil akcji granych w chwili ![]() .
.
Definicja 13.1
Historia do (chwili) ![]() (in time t) jest to ciąg profili akcji
(in time t) jest to ciąg profili akcji
gdzie ![]() oznacza profil pusty, formalnie potrzebny do określenia akcji granej początku gry.
oznacza profil pusty, formalnie potrzebny do określenia akcji granej początku gry.
Na przykład dla dwóch graczy historia do ![]() jest to ciąg
jest to ciąg ![]() par akcji.
par akcji.
Używając nomenklatury z teorii GE mówimy że historia jest zakończona wtedy i tylko wtedy gdy jest nieskończona.
Formalnie historia zakończona to nieskończony ciag profili ![]() .
.
W celu zdefiniowania strategii w GN oznaczmy:
![]() –zbiór wszystkich historii do
–zbiór wszystkich historii do ![]() . Możemy napisać
. Możemy napisać
Definicja (ważna) 13.3
Strategia (czysta) gracza ![]() jest to nieskończony ciąg funkcji
jest to nieskończony ciąg funkcji
gdzie ![]() –funkcja zwracająca akcję gracza
–funkcja zwracająca akcję gracza ![]() po historii do
po historii do ![]() ;
; ![]() jest to akcja gracza
jest to akcja gracza ![]() po historii
po historii ![]() (czyli w chwili
(czyli w chwili ![]() ) gdy stosuje strategię
) gdy stosuje strategię ![]() .
.
Przykład 13.4
Strategia grim–trigger (strategia cynglowa) w Iterowanym DW (IDW):
![]() ,
,
| (13.1) |
Gracz stosujący tę strategię zaczyna akcją C i gra C do chwili gdy przeciwnik zagra D, i od tego momentu gra D niezależnie od akcji przeciwnika.
Przykłady innych strategii w IDW.
-
All C–zawsze kooperuj.
-
All D–zawsze zdradzaj.
-
TFT–Wet Za Wet (Tit For Tat): w pierwszej rundzie koperuj, następnie powtarzaj ostatni ruch przeciwnika.
-
TFT2–Wet Za 2 Wety (Tit For 2 Tats): zdradzaj gdy przeciwnik zdradził w 2 poprzednich rundach, wpp. kooperuj.
-
BRUTAL: w pierwszym ruchu kooperuj. Następnie: jeżeli przeciwnik kooperuje, zdradzaj co drugą rundę, jeśli w pewnej rundzie zdradzi, graj cały czas D.
-
WIN–STAY, LOSE–SHIFT (PAVLOV): Graj C w pierwszej rundzie, po (C,C) i po (D,D) wpp. graj D.
-
STAND1: w pierwszym ruchu zdradź. Jeżeli przeciwnik też zdradził, to zdradzaj we wszystkich kolejnych rundach, jeśli kooperował to kooperuj we wszystkich kolejnych rundach, w obu przypadkach niezależnie od akcji przeciwnika.
-
STAND2: w pierwszych 2 ruchach zdradź. Jeżeli w nich przeciwnik chociaż raz zdradził, to zdradzaj we wszystkich kolejnych rundach, jeśli nie, to kooperuj we wszystkich kolejnych rundach, w obu przypadkach niezależnie od akcji przeciwnika.
Uwaga 13.1
Analogicznie jak dla GE, profil strategii wszystkich graczy ![]() wyznacza historię zakończoną.
Na przykład dla
wyznacza historię zakończoną.
Na przykład dla ![]() jeżeli obaj gracze grają grim-trigger, historią zakończoną będzie nieskończony ciąg par (C,C)
(poprzedzony
jeżeli obaj gracze grają grim-trigger, historią zakończoną będzie nieskończony ciąg par (C,C)
(poprzedzony ![]() ).
).
Definicja 13.4
Wypłata gracza ![]() z nieskończonego ciągu profili akcji
z nieskończonego ciągu profili akcji ![]() jest dana wzorem
jest dana wzorem
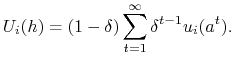 |
Normalizacja ![]() pozwala obliczać wypłaty gry pojedynczej i powtarzalnej w tych samych jednostkach.
Na przykład jeżeli wypłaty mają postać
pozwala obliczać wypłaty gry pojedynczej i powtarzalnej w tych samych jednostkach.
Na przykład jeżeli wypłaty mają postać ![]() , to
, to ![]() .
.
13.3. Równowaga Nasha
Zdefiniujemy równowagę Nasha.
Ponieważ profil strategii ![]() generuje nieskończony ciąg akcji
generuje nieskończony ciąg akcji ![]() , więc użyjemy symbolu
, więc użyjemy symbolu
![]() na oznaczenie wypłaty gracza
na oznaczenie wypłaty gracza ![]() z profilu strategii
z profilu strategii ![]() . Formalnie:
. Formalnie:
gdzie ![]() jest zakończoną historią generowaną przez profil strategii
jest zakończoną historią generowaną przez profil strategii ![]() .
Na przykład dla dwoch graczy stosujących strategię grimm–trigger w DW [2,0,3,1],
.
Na przykład dla dwoch graczy stosujących strategię grimm–trigger w DW [2,0,3,1], ![]()
Definicja (ważna) 13.5
Profil ![]() jest RN w GI jeżeli
jest RN w GI jeżeli
Przykład 13.5
W IDW profil w którym strategia każdego gracza to: graj D po każdej historii do ![]() jest RN.
jest RN.
Okazuje się że nie jest to jedyna RN w IDW.
Przykład 13.6
Profil ![]() (
(![]() =grim–trigger) jest RN.
=grim–trigger) jest RN.
Pokażemy to dla 2-osobowego IDW z macierzą wypłat gry pojedynczej ![]() . Wypłata np. 1-go gracza z
. Wypłata np. 1-go gracza z
![]() to
to ![]() .
.
Jeżeli pewna inna strategia ![]() gracza 1 ma dać wyższą wypłatę, gracz 1 musi zdradzić w pewnej rundzie T+1
po raz pierwszy. Gracz 2 gra strategię grimm–trigger, czyli nie zdradza do T+1, natomiast gra D poczynając od rundy
T+2. Najlepsza odpowiedź gracza 1 jest wtedy D we wszystkich kolejnych rundach. Generuje to nastepujący ciąg profili akcji:
gracza 1 ma dać wyższą wypłatę, gracz 1 musi zdradzić w pewnej rundzie T+1
po raz pierwszy. Gracz 2 gra strategię grimm–trigger, czyli nie zdradza do T+1, natomiast gra D poczynając od rundy
T+2. Najlepsza odpowiedź gracza 1 jest wtedy D we wszystkich kolejnych rundach. Generuje to nastepujący ciąg profili akcji:
gdzie ![]() jest grane w rundzie
jest grane w rundzie ![]() , oraz ciag wypłat
, oraz ciag wypłat
Znormalizowana wypłata:
Łatwo widać że dla ![]()
Tak więc, gdy czynnik dyskontowy jest conajmniej 0.5 to para strategii grim–trigger jest RN w
nieskończenie powtarzanym (iterowanym) Dylemacie Więźnia z macierzą wypłat ![]() .
.
Uwaga 13.2
Analogiczny rachunek dla ogólnego Dylematu Więźnia daje warunek ![]() na to by para strategii
na to by para strategii ![]() była RN.
była RN.
Przykład 13.7
Para strategii ![]() jest RN w nieskończenie powtarzanym Dylemacie Więźnia dla dostatecznie dużego czynnika
dyskontowego.
jest RN w nieskończenie powtarzanym Dylemacie Więźnia dla dostatecznie dużego czynnika
dyskontowego.
Obaj gracze stosując TFT grają w każdej rundzie C i mają w IDW znormalizowane wypłaty równe ![]() każdy.
Załóżmy że gracz 2 zmienia strategię. Aby dała ona wyższą wypłatę niż z pary TFT, w pewnej rundzie
każdy.
Załóżmy że gracz 2 zmienia strategię. Aby dała ona wyższą wypłatę niż z pary TFT, w pewnej rundzie ![]() gracz 2 musi
zagrać D, czyli w
gracz 2 musi
zagrać D, czyli w ![]() jest grany profil
jest grany profil ![]() . W rundzie
. W rundzie ![]() gracz 1 gra D i kontynuuje D do rundy w której
gracz 2 powraca do C (włącznie z tą rundą). Gracz 2 ma od
gracz 1 gra D i kontynuuje D do rundy w której
gracz 2 powraca do C (włącznie z tą rundą). Gracz 2 ma od ![]() dwie możliwości: powrót do C lub kontynuowanie D,
co daje dwie możliwe strategie:
dwie możliwości: powrót do C lub kontynuowanie D,
co daje dwie możliwe strategie: ![]() ,
, ![]() .
W pierwszym przypadku, czyli gdy w
.
W pierwszym przypadku, czyli gdy w ![]() grane jest
grane jest ![]() , gracz 1 w
, gracz 1 w ![]() gra C, czyli 2 ma taką sytuację jak
na początku gry. W drugim gracz 1 kontynuuje D.
gra C, czyli 2 ma taką sytuację jak
na początku gry. W drugim gracz 1 kontynuuje D.
W pierwszym przypadku historia ma postać
gdzie pierwsze ![]() jest grane w
jest grane w ![]() . Odpowiadający jej ciąg wypłat gracza 2 w grach pojedynczych to
. Odpowiadający jej ciąg wypłat gracza 2 w grach pojedynczych to
Ponieważ przez pierwsze ![]() rund wypłaty gracza 2 pokrywają się z jego wypłatami z pierwotnej strategii TFT, więc przy porównywaniu wypłat za rundę 1 przyjmiemy chwilę
rund wypłaty gracza 2 pokrywają się z jego wypłatami z pierwotnej strategii TFT, więc przy porównywaniu wypłat za rundę 1 przyjmiemy chwilę ![]() .
Znormalizowana wypłata 2 od rundy
.
Znormalizowana wypłata 2 od rundy ![]() ze strategii
ze strategii ![]() :
:
Łatwo widać że
W drugim przypadku historia ma postać
gdzie ![]() jest grane w
jest grane w ![]() . Odpowiadający mu ciąg wypłat gracza 2 w grach pojedynczych to
. Odpowiadający mu ciąg wypłat gracza 2 w grach pojedynczych to
Znormalizowana wypłata gracza 2 ze strategii ![]() od rundy
od rundy ![]() :
:
Widać że
Identyczne rozumowanie przeprowadzamy dla gracza ![]() . Tak więc, gdy czynnik dyskontowy jest dostatecznie duży,
para strategii TFT jest RN w nieskończenie powtarzanym Dylemacie Więźnia.
. Tak więc, gdy czynnik dyskontowy jest dostatecznie duży,
para strategii TFT jest RN w nieskończenie powtarzanym Dylemacie Więźnia.
13.4. Twierdzenia o istnieniu
Dla twierdzeń o istnieniu w grach iterowanych uzywa się też np. nazw: twierdzenia potoczne, ludowe, które biorą się stąd że były one znane od pewnego czasu, a nie są znani ich pierwsi autorzy.
Typowe twierdzenie potoczne mówi że w grze powtarzalnej prawie każdy wynik (ciąg wypłat graczy) może być zrealizowany w pewnej RN, o ile czynnik dyskontowy jest dostatecznie duży. Różne założenia dają różne postacie twierdzenia potocznego.
Definicja 13.7
Gwarantowana wypłata (reservation payoff) w 2-osobowej GN gracza ![]() jest to liczba
jest to liczba
Jest to wypłata jaką ![]() może sobie zagwarantować zakładając że przeciwnik będzie chciał by była ona jak najmniejsza. Na przykład dla IDW gracz AllD ma gwarantowaną wypłatę
może sobie zagwarantować zakładając że przeciwnik będzie chciał by była ona jak najmniejsza. Na przykład dla IDW gracz AllD ma gwarantowaną wypłatę ![]()
Definicja 13.8
Procentem (udziałem) kooperacji w zakończonej historii IDW jest to granica
gdzie ![]() jest liczbą gier pojedynczych do rundy
jest liczbą gier pojedynczych do rundy ![]() , w których była grana para akcji
, w których była grana para akcji ![]() .
.
Twierdzenie 13.2
Dla dowolnej liczby ![]() istnieje, dla dostatecznie dużego czynnika dyskontowego
istnieje, dla dostatecznie dużego czynnika dyskontowego ![]() RN w IDW
indukująca zakończoną historię
RN w IDW
indukująca zakończoną historię ![]() taką że
taką że ![]() jest procentem (udziałem) kooperacji w
jest procentem (udziałem) kooperacji w ![]() .
.
Ćwiczenie 13.1
IDW jako gra jednokrotna
Niech ![]() oznacza prawdopodobieństwo każdej następnej gry. Niech T oznacza wypłatę w grze jednokrotnej. Wtedy wypłatę ze strategii w której gracz otrzymuje w każdym kroku T definiujemy
oznacza prawdopodobieństwo każdej następnej gry. Niech T oznacza wypłatę w grze jednokrotnej. Wtedy wypłatę ze strategii w której gracz otrzymuje w każdym kroku T definiujemy
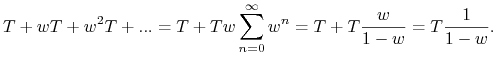 |
Rozważmy grę 2-osobowa w której każdy z graczy może grać jedną ze strategii: AllD, TFT, z wypłatami ![]() jednokrotnego Dylematu Więźnia. Macierz wypłat ma postać
jednokrotnego Dylematu Więźnia. Macierz wypłat ma postać
| TFT | AllD | |
|---|---|---|
| TFT | R/(1-w),R/(1-w) | S+Pw/(1-w),P/(1-w) |
| AllD | T+Pw/(1-w),S+Pw/(1-w) | P/(1-w),P/(1-w) |
lub, oznaczając x = w/(1-w):
| TFT | AllD | |
|---|---|---|
| TFT | R(1+x),R(1+x) | S+Px,T+Px |
| AllD | T+Px,S+Px | P(1+x),P(1+x) |
Oprócz ”nieefektywnej” równowagi Nasha ![]() istnieje dla
istnieje dla ![]() symetryczna RN:
symetryczna RN: ![]() . Zmienił się typ gry.
. Zmienił się typ gry.
W każdej z dwóch RN gracze grają te same akcje.


