Zagadnienia
5. Modelowanie danych
,,All models are wrong, but some are useful.” George Box
Jak najlepiej budować aplikacje?
-
Dobrze działający system to taki system, którego istnienie jest niezauważalne dla posługujacych się nim (przynajmniej dopóki się nie popsuje).
-
Przykłady łatwo wskazać:
-
umywalka
-
winda
-
Przebieg projektu
-
Uzgodnić z użytkownikami kształt przyszłego systemu.
-
Opisać w postaci specyfikacji uzgodnione wymagania.
-
Zaprojektować sposób realizacji systemu.
-
Zrealizować system i wdrożyć go.
5.1. Diagramy związków/encji (ERD)
-
Diagramy związków-encji, spopularyzowane przez Bachmana i Chena.
-
Powinny zawierać związki pomiędzy danymi pamiętanymi, tzn. takimi, które nie mogą być wyprowadzone z innych danych.
-
Obecnie coraz częściej używane tylko do modelowania baz danych podczas projektowania fizycznego.
-
Dwa podstawowe składniki:
-
encje
-
związki
-
-
Encje opisują (w uproszczony sposób) obiekty, wchodzące w zakres naszego zainteresowania.
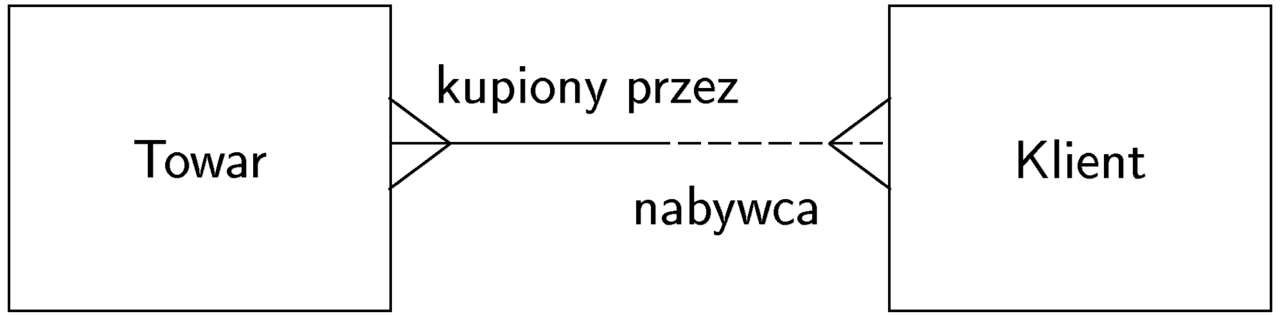
Konstrukcje obiektowe na ERD
-
Niektóre encje mogą odpowiadać podklasom, np. towary sprzedawane przez pewną firmę (modelowane encją Towar) mogą dzielić się na sprzęt, oprogramowanie i materiały pomocnicze.
-
Niektóre relacyjne bazy danych (np. PostgreSQL) pozwalają reprezentować takie hierarchie tabel, jednak podklasy powinny być rozłączne.

5.2. Projektowanie bazy danych
Kolejne kroki
-
Atrybuty i zależności, grupowanie
-
Odwzorowanie encji/obiektów i związków w relacje/tabele
-
Normalizacja i denormalizacja.
-
Strojenie bazy, definiowanie ścieżek dostępu.
Elementy projektowania
-
Projektowanie obejmuje projekt logiczny bazy danych i projekt implementacji fizycznej.
-
Projektowanie logiczne bazy danych polega na zdefiniowaniu tabel, określeniu ścieżek dostępu (access paths) dla tabel (np. indeksów) oraz dostosowaniu indeksów do potrzeb aplikacji.
-
Warto korzystać z perspektyw — upraszcza to zwłaszcza projektowanie formularzy i raportów w wielu narzędziach.
-
-
Projektowanie implementacji fizycznej dotyczy rozmieszczenia plików bazy danych na dyskach, planów archiwowania i odtwarzania oraz integracji z narzędziami systemu operacyjnego.
5.3. Obiektowe podejście do modelowania
UML: obiektowy język modelowania
-
UML (Unified Modeling Language) został zaprojektowany przez Boocha, Jacobsena i Rumbaugh.
-
W 1997 roku Object Management Group przyjęła UML 1.1 jako swój standard przemysłowy.
Diagramy klas
-
Służą do modelowania struktury systemu.
-
Używane w
-
modelowaniu dziedziny systemu (modelowanie biznesowe)
-
projektowaniu (w tym bazy danych), pojawiają się wtedy klasy ,,techniczne”
-
inżynierii odwrotnej (reverse engineering)
-
Klasy
-
Podstawowym składnikiem diagramu klas są nazwane klasy.
-
Najprostsza reprezentacja klasy nie zawiera nic więcej.
-
Oprócz nazwy klasa może zawierać
-
atrybuty
-
metody.
-
Powiązania
Rodzaje powiązań:
-
Asocjacja
-
Agregacja i kompozycja
-
Dziedziczenie
-
Zależność
-
refinement — realizacja lub uszczegółowienie
Klasa może być w relacji agregacji z wieloma klasami nadrzędnymi, natomiast w relacji kompozycji tylko z jedną nadrzędną.

Zależności
Zależność między klasami oznacza, że klasy nie mają powiązania, natomiast klasa zależna otrzymuje obiekt tej drugiej klasy np. jako parametr jednej ze swoich metod.
Dziedziczenie
Przykład błędnego dziedziczenia:

Refinement
-
Wiąże ze sobą dwa opisy tej samej rzeczy na różnych poziomach abstrakcji.
-
W przypadku gdy wiąże typ z klasą realizującą go zwane jest realizacją.
-
Może być użyte do modelowania różnych implementacji tej samej rzeczy.
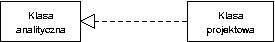
Kiedy używać agregacji?
-
Czy są jakieś operacje na całości, które są automatycznie stosowane do składowych?
Kiedy wybierać agregację, a kiedy dziedziczenie?
-
Jeśli rodzaj obiektu (np. Student) może ulec zmianie (np. z dziennego na zaocznego) bez zmiany reszty atrybutów, to przy dziedziczeniu będzie to wymagało zmiany klasy obiektu!
Atrybuty i asocjacje
Czasem mamy wątpliwości, czy w danej sytuacji użyć atrybutu czy asocjacji. Ogólna zasada jest następująca:
-
Atrybuty służą do łączenia obiektów z wartościami. Wartość to element nie posiadający identity, np. liczba 1.
-
Asocjacje łączą obiekty z obiektami.
Wartości zawsze mogą być zapisane bezpośrednio i odtworzone. Z obiektami jest trudniej, bo należy uwzględnić wszystkie związki.
5.4. Przypadki użycia
Model przypadków użycia
-
Modelu tego używa się przede wszystkim do opracowania specyfikacji wymagań.
-
Dwa podstawowe składniki: aktorzy i przypadki użycia.
-
Model przypadków użycia wyznacza granice systemu.
-
Najczęściej są to granice budowanego systemu (aplikacji), jednak przypadki użycia służą także do modelowania przedsiębiorstwa (tzw. przypadki biznesowe).
-
Nie należy jednak mieszać tych dwóch podejść w jednym modelu.
-
Przypadki użycia
-
Każdy przypadek to realizacja jakiejś rzeczywistej potrzeby użytkownika (aktora), nazwa przypadku powinna to uwzględniać, a nie opisywać czynności systemu. Wyświetlanie wyników klasówki to zła nazwa, lepszą będzie Przeglądanie wyników klasówki.
-
Przypadki użycia powinny odpowiadać kolejnym fragmentom podręcznika użytkownika. Jeśli używamy pakietów do grupowania dużej liczby przypadków użycia, to każdy pakiet odpowiada rozdziałowi podręcznika.
-
Scenariusze (opisy) przypadków użycia należy pisać z perspektywy użytkownika, a nie systemu.
-
Nie należy tworzyć przypadków użycia zgrupowanych wokół ,,obiektów”, np. Przetwarzanie informacji o studentach. Mają one zwykle za dużo aktorów i zbyt długie specyfikacje.
5.5. Diagram stanów
-
Do opisywania historii klas korzysta się z sieci przejść, zwanych też diagramami stanów. Są one uogólnionymi automatami skończonymi.
-
Sieć taka składa się z wierzchołków, reprezentujących stany klasy, oraz powiązań między nimi, odpowiadających przejściu z jednego stanu do drugiego.
-
Diagram stanów opisuje historię życia obiektu danej klasy.
-
Jeśli operacje na obiekcie danej klasy mogą być wykonywane w dowolnej kolejności, to diagram ten jest najprawdopodobniej zbędny.
-
Jeśli jednak klasa przedstawia (reifikuje) przypadek użycia, proces, zarządcę interfejsu itp., wtedy kolejnośc kroków staje się istotna. Trzeba więc określić mechanizm dostarczania i obsługi zdarzeń.
-
Stany i przejścia
-
Stan stanowi abstrakcję wartości zmiennych (parametrów itp.) obiektu taką, że ich wszystkie te kombinacje dają jednakową jakościowo odpowiedź na zdarzenia.
-
Przejścia etykietuje się warunkami, których spełnienie powoduje wskazaną zmianę stanu. Zamiast warunków można też stosować zdarzenia, powodujące wskazaną zmianę stanu.
-
Oprócz tego z poszczególnymi przejściami mogą być związane akcje sterujące, uaktywaniające odpowiednie procesy.
Uwagi o diagramach stanów
-
Przy bardziej złożonym zachowaniu stosuje się sieci zagnieżdżone, zwane też diagramami Harela. W sieciach takich każde przejście dotyczące stanu złożonego dotyczy wszystkich jego podstanów wewnętrznych.
-
Modelując zachowanie obiektów staramy się pokazać dwie rzeczy: zmiany stanu oraz interakcje z innymi obiektami.
-
Robiąc diagramy stanów dla klas trzeba pamiętać, że klasa musi mieć atrybuty lub związki, przez zmianę których realizuje zmianę stanu. Inaczej mówiąc, stany są reprezentowane pośrednio ich wartościami.
5.6. Narzędzia CASE
-
Pakiet CASE to środowisko do modelowania i tworzenia aplikacji.
-
Centralną częścią takiego pakietu jest wspólne repozytorium.
-
Dzięki temu możliwa jest równoczesna wspólna praca nad wieloma projektami, z dzieleniem wspólnych fragmentów między nimi.
-
Dotyczy to zarówno pojedynczych obiektów, jak i całych modeli.
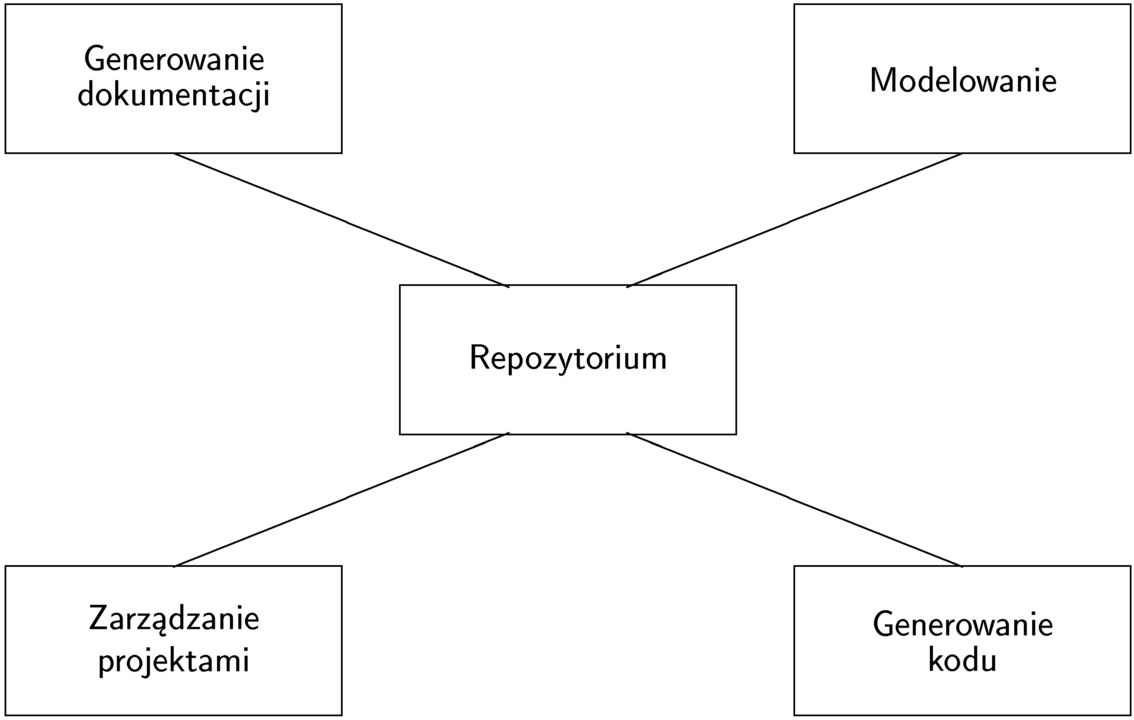
Funkcje typowego narzędzia CASE
-
rysowanie diagramów (obejmuje znajmość semantyki symboli i reguł poprawności)
-
repozytorium modeli i ich elementów (np. gdy zmienimy nazwę klasy, powinno to być widoczne na wszystkich diagramach)
-
wspieranie nawigacji po modelach
-
możliwość pracy kilku użytkowników
-
generowanie (szkieletu) kodu
-
inżynieria odwrotna (reverse engineering)
-
integracja z innymi narzędziami
-
obsługa poziomów abstrakcji modelu
-
wymiana modeli (eksport i import)
Realizacja narzędzi CASE
-
Do zarządzania repozytorium używane są zwykle systemy relacyjnych baz danych, np. SQL Anywhere (Sybase).
-
Możliwa jest często inżynieria odwrotna, tzn. wciąganie do modeli analitycznych i projektowych obiektów z już istniejących programów i baz danych.
5.7. Zadania
Ćwiczenie 5.1
Dane są dwie encje
-
1–1
-
1–n
-
m–n.
m–n, czyli wiele-do-wielu


