Zagadnienia
1. Wstęp - Co to jest ekonometria?
Podstawowe metody i cele. Przykłady modeli ekonometrycznych. Ogólna klasyfikacja modeli ekonometrycznych. (1 wykład)
1.1. Informacje wstępne
W skrócie można powiedzieć, że ekonometria to zestawienie danych empirycznych z teoriami ekonomicznymi przy zastosowaniu statystyki matematycznej.
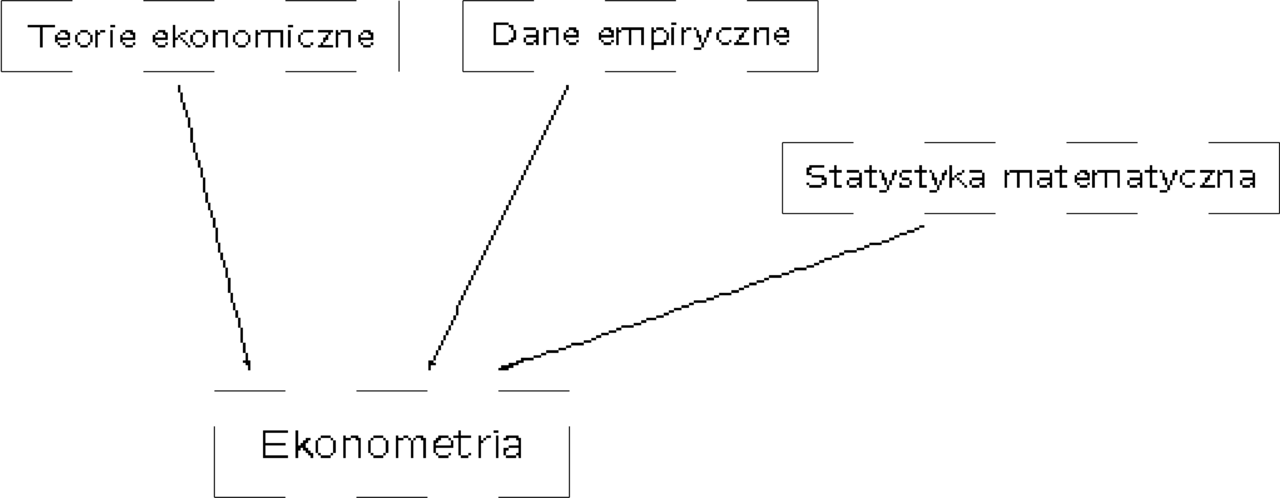
Podstawowe cele ekonometrii to:
1. Analiza danych empirycznych i prognozowanie na ich podstawie;
2. Weryfikacja i kalibrowanie teorii ekonomicznych.
Kluczowym obiektem w ekonometrii jest tzw. model ekonometryczny. Zapisujemy go w postaci
gdzie
a
1.2. Etapy modelowania
Przedstawimy teraz uproszczony schemat konstrukcji modelu ekonometrycznego.
Możemy wyróżnić trzy operacje:
Zbieramy dane historyczne (empiryczne)
Konstruujemy model
Konstruujemy model stochastyczny
Zakładamy, że w przyszłości
Proszę zwrócić uwagę, że dwie pierwsze operacje aproksymację i estymację możemy wykonać dowolnie dokładnie. Natomiast o ekstrapolacji zawsze ”matematyk teoretyk” będzie mógł powiedzieć, że to ”wróżenie z fusów”.
1.3. Przykłady
1. Model konsumpcji
Przez
gdzie
Zauważmy, że składnik losowy ”zawiera w sobie” wszystkie czynniki nie uwzględnione w sposób jawny w modelu.
Uwagi:
W modelu zakładamy, że
2. Model oszczędności
Przez
gdzie
Uwagi:
Zauważmy, że w powyższym modelu opóźniona zmienna objaśniana jest zmienną objaśniająca.
Model 1 i 2 można połączyć i otrzymać model dwurównaniowy.
3. Model konsumpcji z uwzględnieniem oszczędności
Przez
gdzie
Uwagi:
Na powyższym przykładzie widzimy, jak z prostszych modeli można konstruować bardziej skomplikowane.
Pytanie: Czy w ten sposób uzyskujemy lepszy opis badanego zjawiska?
Okazuje się, że nie zawsze. Wyznaczanie wartości parametrów dla bardziej złożonego modelu, jest zwykle bardziej skomplikowane i mniej dokładne. W efekcie złożony model, który jest teoretycznie lepszy, w praktyce już takim być nie musi.
4. Model popytu dla dóbr konsumpcyjnych
Przez
Uwagi:
Jest to przykład modelu nieliniowego, który można zlinearyzować za pomocą logarytmowania.
5. Model stochastyczny kursu walutowego
Niech
Po zlogarytmowaniu otrzymujemy model błądzenia przypadkowego
6. Model wydajności pracy
Niech
Po zlogarytmowaniu otrzymujemy
Uwagi:
Współczynnik
1.4. Klasyfikacja modeli ekonometrycznych
1. Klasyfikacja ze względu na dynamikę:
a. Modele statyczne (jednokresowe) charakteryzujące się brakiem zależności od czasu, tzn.
b. Modele dynamiczne – zależne od czasu lub od opóźnionych zmiennych objaśnianych. Przykłady 2, 3, 5 i 6.
W klasie modeli dynamicznych wyróżniamy modele autoregresyjne w których zależność od czasu wiąże się tylko z występowaniem zmiennych opóźnionych. Przykłady 2, 3 i 5.
2. Klasyfikacja ze względu na postać analityczną modelu:
a. Modele liniowe, postać analityczna jest zadana przez funkcję liniową. Przykłady 1, 2 i 3.
b. Modele nieliniowe, postać analityczna nie jest zadana przez funkcję liniową.
W klasie modeli nieliniowych wyróżniamy modele multiplikatywne, które można zlinearyzować poprzez zlogarytmowanie.
Przykłady 4, 5 i 6.
2. Klasyfikacja ze względu na wymiar zmiennej objaśnianej:
a. Modele jednorównaniowe. Przykłady 1, 2, 4, 5 i 6.
b. Modele wielorównaniowe. Przykład 3.
Klasyfikacja ze względu na dynamikę wiąże się z planowanym wykorzystaniem modelu.
Do prognozowania potrzebne są modele dynamiczne. Natomiast do badania wpływu zmian konkretnych czynników wystarczy model statyczny.
Klasyfikacja ze względu na postać analityczną modelu i wymiar określa złożoność kalibracji modelu. Jeśli model jest liniowy i jednorównaniowy to istnieją ogólne, w miarę proste, algorytmy (które omówimy na dalszych wykładach) pozwalające sprawnie wyestymować parametry modelu. W przeciwnym wypadku algorytm zależy od konkretnego przypadku i zwykle jest dużo bardziej skomplikowany.


