Zagadnienia
9. Algorytmy widoczności
9.1. Rodzaje algorytmów widoczności
Dana jest scena trójwymiarowa, tj. pewien zbiór figur w przestrzeni, i położenie obserwatora. Zadanie polega na znalezieniu (i ewentualnym wykonaniu obrazu) fragmentów figur widocznych dla obserwatora. Algorytmów rozwiązujących to zadanie jest dużo i warto je poklasyfikować, dzięki czemu łatwiej będzie wybrać algorytm odpowiedni do potrzeb.
Z problemem rozstrzygania widoczności wiąże się zadanie wyznaczenia cieni dla punktowych źródeł światła. Części figur sceny niewidoczne z punktu położenia źródła światła leżą w cieniu. Dlatego wyznaczanie cieni jest rozstrzyganiem widoczności. Nie wszystkie algorytmy rozstrzygania widoczności są jednak odpowiednie do wyznaczania cieni.
Podstawowy podział algorytmów widoczności wyróżnia
-
Algorytmy przestrzeni danych, które wyznaczają reprezentację obszaru widocznego, na podstawie której moża wykonać wiele obrazów, o dowolnej rozdzielczości (w tym obrazy otrzymane po zmianie rzutni, przy ustalonym położeniu obserwatora),
-
Algorytmy przestrzeni obrazu — wynikiem takiego algorytmu jest obraz, czyli tablica odpowiednio pokolorowanych pikseli. Mogą też być dodatkowe informacje związane z każdym pikselem, ale zmiana rozdzielczości obrazu wymaga ponownego wykonania algorytmu widoczności.
Inne cechy dowolnego algorytmu widoczności to
-
Klasa danych, dla których algorytm może działać. Algorytm może dopuszczać
-
tylko powierzchnie płaskie (np. wielokąty), albo także powierzchnie zakrzywione,
-
zbiory powierzchni, które mogą się przecinać, albo nie,
-
obiekty z otwartą objętością (powierzchnie dwustronne), albo tylko z zamkniętą objętością,
-
bryły o jawnej reprzentacji, albo drzewa CSG, a także obiekty zdeformowane reprezentowane za pomocą niezdeformowanego prymitywu i odpowiedniego przekształcenia,
-
tylko powierzchnie, albo również dane objętościowe (reprezentujące np. chmurę, w której są widoczne zanurzone obiekty).
-
-
Rodzaj obrazu; tu można wyróżnić
-
algorytmy powierzchni zasłoniętej i
-
algorytmy linii zasłoniętej.
-
-
Stopień skomplikowania algorytmu i jego struktur danych, możliwość zrównoleglenia obliczeń, a także możliwość użycia sprzętu (procesora w karcie graficznej) do wykonania wszystkich lub niektórych kroków algorytmu.
-
Inne szczegóły, np. obecność preprocesingu, w wyniku którego rozstrzyganie widoczności dla wielu kolejno otrzymywanych obrazów, np. podczas ruchu obserwatora względem sceny, jest tańsze.
Można zaobserwować ogólną zasadę, że im mniej informacji ma dostarczyć algorytm (tj. im mniej dokładna reprezentacja obszaru widocznego jest potrzebna — np. tylko pokolorowane piksele) tym ogólniejsze dane można dopuścić. Daje to przewagę w zastosowaniach algorytmom przestrzeni obrazu. Ważna jest też możliwość implementacji tych algorytmów w sprzęcie. Co prawda, wtedy nie zawsze jest zrealizowana możliwość przetwarzania najbardziej skomplikowanych danych, jakie dla danego algorytmu są teoretycznie dopuszczalne. Na przykład algorytm z buforem głębokości teoretycznie dopuszcza bardzo wiele różnych rodzajów danych (np. gładkie powierzchnie zakrzywione), ale jego implementacja sprzętowa, która jest jednym z najważniejszych elementów OpenGL-a, umożliwia rozstrzyganie widoczności tylko płaskich wielokątów i odcinków. Można napisać własną implementację, programową, ale z wyjątkiem bardzo specjalnych sytuacji nie ma to sensu. Ze względu na szybkość działania i dodatkowe możliwości OpenGL-a (np. oświetlenie, teksturowanie) lepiej jest przybliżać powierzchnie za pomocą odpowiedniej liczby płaskich trójkątów.
9.2. Algorytmy przestrzeni danych
Skupimy się na algorytmach rozstrzygania widoczości w scenach złożonych z płaskich wielokątów. Widoczna część każdego z nich też jest płaskim wielokątem.
9.2.1. Odrzucanie ścian ,,tylnych”
Jeśli wielokąty są ścianami brył (obiektów z zamkniętą
objętością), to korzystając z umowy, że wektor normalny płaszczyzny
każdej ściany jest zorientowany ,,na zewnątrz bryły”, można
odrzucić (uznać za niewidoczne w całości) ściany ,,odwrócone
tyłem” do obserwatora. Ten wstępny test widoczności sprowadza się do
zbadania znaku iloczynu skalarnego: jeśli punkt

Jeśli scena składa się z jednego wielościanu wypukłego, to wszystkie pozostałe ściany są w całości widoczne. Opisany test jest często stosowany jako wstępny etap innych algorytmów widoczności, zarówno działających w przestrzeni danych, jaki i obrazu. Przed zastosowaniem tego algorytmu trzeba się upewnić, że rysujemy bryły i położenie obserwatora nie jest wewnątrz jednej z nich.
W OpenGL-u można uaktywnić taki test, wywołując przed wyświetlaniem sceny procedury
glEnable ( GL_CULL_FACE ); glCullFace ( GL_BACK );
Wyświetlane wielokąty muszą być wypukłe, a ich brzegi odpowienio
zorientowane; jeśli
9.2.2. Obliczanie punktów przecięcia odcinków w przestrzeni
Przypuśćmy, że mamy dane dwa odcinki w przestrzeni trójwymiarowej
i punkt

Aby rozwiązać zadanie, przedstawimy poszukiwane punkty w taki sposób:
Warunkiem współliniowości punktów
Po przekształceniu otrzymujemy układ równań liniowych
z niewiadomym wektorem
-
Jeśli macierz układu ma rząd
-
Rząd
-
Jeśli macierz ma rząd
-
Macierz rzędu
9.2.3. Algorytm Ricciego
Algorytm Ricciego jest algorytmem linii zasłoniętej dla sceny złożonej z wielokątów (np. ścian wielościanów), które nie przenikają się. Dane składają się ze zbioru ścian (ewentualnie tylko ,,odwróconych przodem” do obserwatora), zbioru ich krawędzi i położenia obserwatora. Przyjęte jest też założenie upraszczające — wszystkie ściany są wielokątami wypukłymi (w tym celu można je podzielić na wielokąty wypukłe, krawędzie wprowadzone podczas tego dzielenia nie są dołączane do zbioru krawędzi, których fragmenty mogą być widoczne).

Wykonując algorytm, kolejno dla każdej krawędzi
-
Tworzymy reprezentację widocznych części krawędzi, w postaci listy par liczb. Liczby te są wartościami parametru, które odpowiadają punktom końcowym niezasłoniętym częściom krawędzi. Na początku każda taka lista zawiera tylko jedną parę liczb,
-
Kolejno dla każdej ściany
-
wyznaczamy liczby
-
Jeśli ściana
Proces kończymy po przetworzeniu ostatniej ściany, albo po otrzymaniu pustej listy przedziałów (która oznacza, że krawędź
-
-
Kolejno dla każdego elementu listy obliczamy punkty na krawędzi

Koszt tego algorytmu jest proporcjonalny do kwadratu liczby krawędzi, czyli jest dość wysoki. Wśród algorytmów przestrzeni danych może to jednak być algorytm optymalny, ponieważ wynik (liczba widocznych fragmentów krawędzi albo ścian) może mieć wielkość tego rzędu. Przykład jest na rysunku 9.4.
Takie dane jak na rysunku zdarzają się jednak rzadko, w związku z czym implementując algorytm warto sięgnąć po techniki przyspieszające (obniżające średnią złożoność obliczeniową algorytmu). Najprostszy taki sposób polega na
-
zrzutowaniu wierzchołków na płaszczyznę obrazu,
-
posortowaniu krawędzi i ścian w kolejności rosnących najmniejszych współrzędnych
-
utworzeniu (początkowo pustej) listy ścian aktywnych,
-
następnie, kolejno dla każdej krawędzi
-
wyrzucamy z listy ścian wszystkie ściany, których największa współrzędna
-
wstawiamy do listy wszystkie ściany, których najmniejsza współrzędna
-
rozstrzygamy widoczność krawędzi
-
Na skuteczność tego sposobu ma wpływ scena oraz sposób jej zrzutowania. Metoda działa tym lepiej, im krótsze w stosunku do wielkości sceny są krawędzie i im mniejsze są ściany.
Jeszcze jedna uwaga: dla każdej krawędzi trzeba znać ściany, które do niej przylegają. Testując widoczność pomijamy je, bo żadna ściana płaska nie zasłania swoich krawędzi, a błędy zaokrągleń mogłyby doprowadzić do innego wyniku.
9.2.4. Algorytm Weilera-Athertona
Algorytm Weilera-Athertona powierzchni zasłoniętej może być użyty do znalezienia fragmentów ścian widocznych z danego punktu, który może być położeniem obserwatora lub źródła światła; jest to więc także algorytm wyznaczania cieni. Dane dla tego algorytmu reprezentują scenę złożoną z płaskich wielokątnych ścian, które mogą mieć otwory, być niespójne itd. Załóżmy, że nie ma ,,zapętlenia” relacji zasłaniania ścian, tj. nie występuje para ścian, z których każda zasłania część drugiej (w przeciwnym razie należy podzielić jedną ze ścian wzdłuż prostej wspólnej płaszczyzn ścian).
W algorytmie tym sprawdza się widoczność kolejno dla wszystkich par ścian w scenie. Jedną ze ścian testowanej pary rzutuje się na płaszczyznę drugiej ściany, a następnie wykonuje się algorytm Weilera-Athertona w celu wyznaczenia różnicy tych wielokątów. Argument odejmowany odpowiada ścianie leżącej bliżej obserwatora (test widoczności można przeprowadzić dla jednej, dowolnej pary punktów, z których jeden zasłania drugi).
Znaleziony wielokąt odpowiada widocznej części ściany. Od wielokąta tego odejmuje się rzuty wszystkich innych ścian, które ścianę daną zasłaniają. Przetwarzanie ściany kończymy po wyczerpaniu ścian, które mogą ją zasłaniać, albo po otrzymaniu zbioru pustego.
Opisany algorytm jest dość kosztowny (ponieważ wykonuje obliczenia dla każdej pary ścian), ale często można obniżyć jego koszt za pomocą podobnej metody, jak dla algorytmu Ricciego.
9.2.5. Algorytm Appela
Przypuśćmy, że ściany nie przenikają się. Wtedy dowolna krawędź, która nie jest widoczna w całości, ma punkty zmiany widoczności; punkty te są zasłaniane przez punkty leżące na krawędziach konturowych, tj. takich krawędziach, do których przylegają ściany, z których jedna jest ,,obrócona przodem” do obserwatora, a druga jest ,,obrócona tyłem”.
Krawędzi konturowych jest często znacznie mniej niż wszystkich krawędzi w scenie, co pozwala otrzymać algorytm linii zasłoniętej o mniejszej złożoności obliczeniowej niż ma algorytm Ricciego.
W tym celu określamy graf krawędziowy, czyli graf skierowany, którego wierzchołkami są wierzchołki ścian, a krawędziami są krawędzie tych ścian. Orientacja krawędzi jest obojętna, ale musi być określona. Po utworzeniu tego grafu będziemy wprowadzać dodatkowe wierzchołki, dokonując podziału krawędzi w punktach wyznaczonych za pomocą algorytmu opisanego w p. 9.2.2.
Dodatkowo określimy stopień zasłonięcia, który jest funkcją
w przestrzeni. Wartość tej funkcji w dowolnym punkcie
Kolejne kroki algorytmu są następujące:
-
Wyznaczamy graf krawędziowy (na ogół jest on częścią reprezentacji sceny).
-
Kolejno dla każdej krawędzi wyznaczamy jej punkty przecięcia w rzucie z krawędziami konturowymi i badamy każdy taki punkt, czy jest on bliżej, czy dalej od obserwatora niż odpowiedni punkt krawędzi konturowej. Jeśli krawędź konturowa zasłania ten punkt, to dzielimy krawędź, na której on leży na fragmenty i wprowadzamy dodatkowy wierzchołek grafu krawędziowego (dzieląc odpowiednią jego krawędź). Każdemu takiemu wierzchołkowi przypisujemy liczbę
-
Wyznaczamy stopień zasłonięcia dowolnego wierzchołka grafu, a następnie, zaczynając od tego wierzchołka, przeszukujemy graf krawędziowy. W każdym wierzchołku, w którym widoczność zmienia się, dodajemy lub odejmujemy (to zależy od orientacji krawędzi i od kierunku ,,poruszania się” po niej) zmianę stopnia widoczności do lub od wartości stopnia widoczności fragmentu krawędzi przetwarzanego wcześniej. W ten sposób otrzymujemy stopień widoczności wszystkich krawędzi grafu (przeszukujemy w ten sposób wszystkie jego składowe spójne). Wyprowadzamy lub zaznaczamy jako widoczne krawędzie, których stopień zasłonięcia jest równy
Stosując ten algorytm, trzeba uważać, bo sceny złożone z wielokątnych ścian bywają dość skomplikowane i pełna implementacja algorytmu musi być w stanie radzić sobie z wszystkimi przypadkami szczególnymi.
Kłopoty zdarzają się we wspólnych wierzchołkach wielu krawędzi, które mają rożne stopnie zasłonięcia. Przeszukując graf, doszedłszy do takiego wierzchołka, najbezpieczniej (w sensie odporności na błędy) jest bezpośrednio obliczyć stopień zasłonięcia krawędzi wychodzących z takiego wierzchołka.
W algorytmie Appela jest możliwa pewna kontrola poprawności; dochodząc do dowolnego odwiedzonego wcześciej wierzchołka grafu możemy porównać jego stopień zasłonięcia obliczony wcześniej ze stopniem zasłonięcia obliczonym ,,po drodze” do tego wierzchołka. Muszą one być równe.
9.2.6. Algorytm Hornunga
W algorytmie Hornunga, którego dokładnie nie omówię z powodów, które
(mam nadzieję) staną się za chwilę jasne, testy widoczności są
ograniczone do par krawędzi konturowych. Jeśli liczba krawędzi
konturowych jest dużo mniejsza niż wszystkich, to złożoność tego
algorytmu jest jeszcze mniejsza niż złożoność algorytmu Appela.
Jest to jednak algorytm skomplikowany. Implementacja algorytmu
powierzchni zasłoniętej, opartego na tym algorytmie, miała ponad
9.3. Algorytmy przestrzeni obrazu
W odróżnieniu od algorytmów opisanych wcześniej, algorytmy przestrzeni obrazu dają w wyniku obraz rastrowy, na którym każdy piksel ma przypisany kolor punktu sceny widocznego w tym miejscu. Jeśli chcemy otrzymać obraz o innej rozdzielczości, albo ewentualnie zmienić kierunek, w którym patrzy obserwator, to musimy wykonać obliczenie jeszcze raz. Z drugiej strony, algorytmy przestrzeni obrazu mają tę przewagę nad algorytmami przestrzeni danych, że dla pewnych klas danych nie istnieje dokładna, obliczalna reprezentacja widocznej części sceny (jest tak dla większości powierzchni zakrzywionych).
9.3.1. Algorytm malarza
Zasada działania algorytmu malarza jest następująca:
-
Posortuj ściany w kolejności od najdalszej do najbliższej obserwatora,
-
Namaluj je w tej kolejności.
Prosta idea niech nie przesłania faktu, że mogą istnieć konflikty widoczności, w których ściana położona w zasadzie dalej zasłania część ściany bliższej obserwatora. Dlatego po posortowaniu (np. ze względu na odległość od obserwatora najbliższego punktu każdej ściany) konieczne jest sprawdzenie i ewentualna modyfikacja uporządkowania ścian.
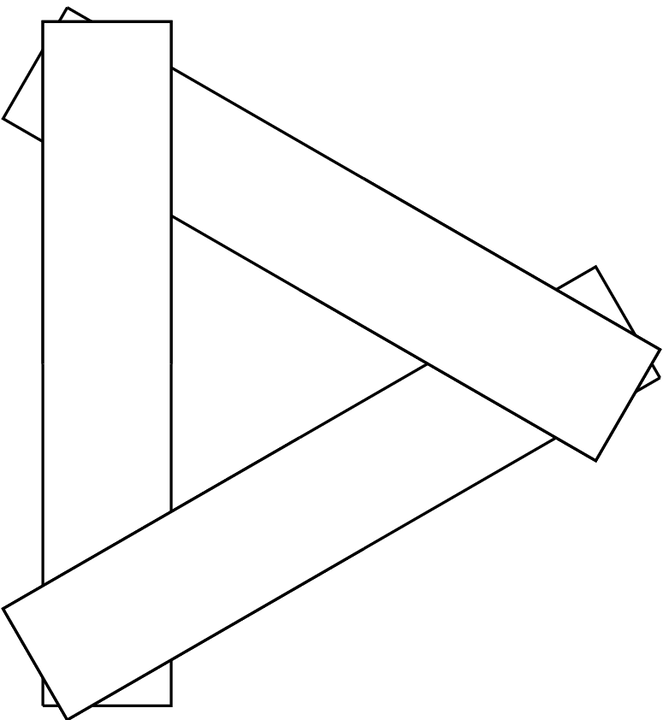
Ponadto mogą wystąpić konflikty nierozstrzygalne, tj. może nie istnieć uporządkowanie ścian gwarantujące otrzymanie poprawnego obrazu. Klasyczny przykład takiego konfliktu jest na rys. 9.5. Jedyne wyjście w tej sytuacji polega na podzieleniu co najmniej jednej ściany na kawałki i wyświetlenie tych kawałków we właściwej kolejności. Dodatkowa wada algorytmu malarza i jego wariantów (o których będzie mowa dalej) to wielokrotne przemalowywanie pikseli. Jeśli wyznaczenie koloru z uwzględnieniem oświetlenia i tekstury jest czasochłonne, a piksel ostatecznie otrzyma kolor innej ściany, to cała praca wykonana w celu obliczenia koloru piksela, który na ostatecznym obrazie będzie inny, pójdzie na marne.
9.3.2. Algorytm binarnego podziału przestrzeni
Algorytm widoczności z użyciem drzewa BSP jest dość trudny do jednoznacznego zaklasyfikowania; nie otrzymujemy w nim reprezentacji widocznych części ścian, a tylko obraz, utworzony podobnie jak w algorytmie malarza. Natomiast zasadniczy koszt obliczeń związanych z rozstrzyganiem zasłaniania wiąże się z budową drzewa, które nie zależy od rozdzielczości obrazu, ani nawet od położenia obserwatora i rzutni.
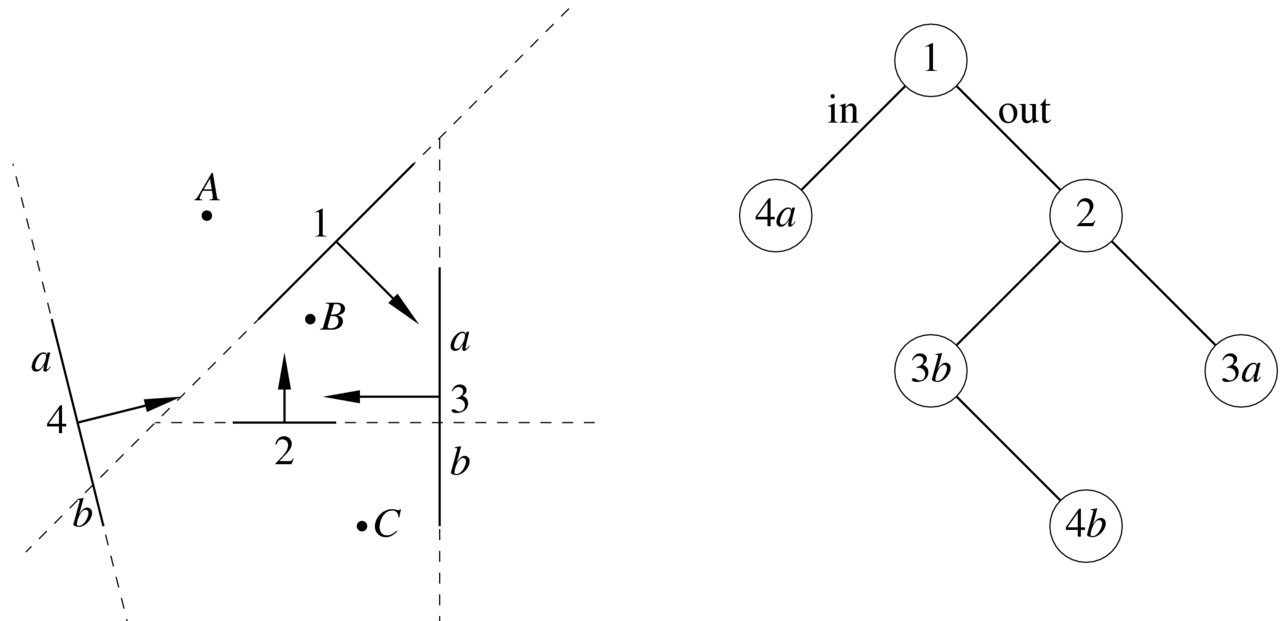
Zasadę działania algorytmu przedstawia płaski przypadek na rysunku 9.6, który pokazuje również drzewo BSP zbudowane dla danych czterech ścian. Spostrzeżenie, które leży u podstaw algorytmu jest następujące: jeśli obserwator znajduje się po pewnej stronie dowolnej płaskiej ściany, to ściana ta nie zasłania żadnych obiektów, które znajdują się po tej samej stronie. Zatem aby otrzymać obraz widocznych części ścian, obchodzimy drzewo algorytmem DFS. Dla każdego wierzchołka drzewa sprawdzamy, po której stronie jest obserwator. Jeśli jest on po stronie ,,in”, to rekurencyjnie wywołujemy procedurę obchodzenia poddrzewa ,,out”. Następnie rzutujemy i wyświetlamy (zamalowujemy odpowiednie piksele) ścianę w bieżącym wierzchołku i obchodzimy poddrzewo ,,in”. Jeśli obserwator znajduje się po stronie ,, out”, to poddrzewa danego wierzchołka przetwarzamy w odwrotnej kolejności. Jeśli położenie obserwatora zawiera się w płaszczyźnie ściany, to kolejność przeszukiwania poddrzew jest dowolna.
Dla położeń
Budowa drzewa BSP przejmuje rolę sortowania, rozstrzygania konfliktów widoczności i dzielenia ścian z algorytmu malarza. Przyjemną cechą tego algorytmu jest fakt, że drzewo wystarczy zbudować tylko raz (chyba, że scena ulega zmianie) i można wykonać wiele obrazów sceny, widzianej z różnych punktów.
9.3.3. Algorytm BSP wyznaczania cieni
Odpowiedni podział przestrzeni, poprzez konstrukcję drzew BSP, może być użyty do wyznaczenia fragmentów ścian oświetlonych przez ustalone punktowe źródło światła. Drzewa BSP w tym algorytmie spełniają dwie różne funkcje:
-
Służą do rozstrzygania widoczności w scenie (w taki sposób jak w algorytmie opisanym wcześniej),
-
Służą do reprezentowania tzw. bryły cienia, która jest zbiorem punktów zasłoniętych przez co najmniej jedną ścianę. Bryłę tę reprezentuje się w pewnym uproszczeniu, które jest możliwe dzięki odpowiedniemu uporządkowaniu ścian.
Przyjmiemy założenie, że wszystkie ściany są wypukłe, co upraszcza implementację (w razie czego można np. dokonać triangulacji ścian). Pierwszy etap algorytmu, niezależny od punktów, w których znajduje się obserwator i źródła światła, polega na zbudowaniu zwykłego drzewa BSP.
Etap drugi polega na budowaniu reprezentacji bryły cienia, z jednoczesnym wyznaczaniem oświetlonych części ścian. W etapie tym przeszukujemy drzewo BSP sceny w kolejności odwrotnej niż podczas rysowania, przyjmując położenie obserwatora w punkcie położenia źródła światła. W ten sposób otrzymujemy najpierw ścianę lub fragment ściany, który jest cały oświetlony, a następnie ściany, które mogą być zasłonięte od światła tylko przez fragmenty wyprowadzone wcześniej. Każdy taki fragment ściany jest wielokątem wypukłym, bo jest on częścią wspólną wypukłej ściany i wypukłej komórki binarnego podziału przestrzeni.
Drzewo BSP bryły cienia jest początkowo puste. Procedura, która je tworzy, przetwarza kolejne wypukłe wielokąty. Każdy taki wielokąt jest podstawą nieograniczonego ściętego ostrosłupa, o wierzchołku w punkcie położenia źródła światła. Płaszczyzny, w których leżą brzegi komórek podziału, są wyznaczone przez punkt położenia źródła światła i odcinki — krawędzie bieżącego fragmentu ściany (a więc jeśli jest on np. trójkątem, to wstawimy trzy ściany, po jednej dla każdego boku).
Przed rozbudowaniem drzewa BSP bryły cienia możemy podzielić bieżący fragment ściany na część oświetloną i zacienioną, w ten sposób, że dzielimy go płaszczyznami podziału odpowiednich komórek (tak, jakbyśmy wstawiali fragment do drzewa). Dla każdej komórki dysponujemy informacją, czy jej punkty są oświetlone, czy nie.
9.3.4. Algorytm z buforem głębokości
Algorytm z buforem głębokości (tzw.
Algorytm:
-
Przypisz wszystkim elementom
-
Kolejno dla każdej ściany, narysuj jej rzut (tj. dokonaj jego rasteryzacji za pomocą algorytmu przeglądania liniami poziomymi). Dla każdego piksela, który należy do rzutu ściany, należy przy tym obliczyć współrzędną
Zaletami algorytmu są prostota, w tym łatwość implementowania algorytmu w sprzęcie, i duża niezawodność (odporność na błędy np. zaokrągleń — skutki takich błędów to pojedyncze piksele o złym kolorze, podczas gdy w algorytmach wyrafinowanych taki błąd może spowodować całkowite załamanie obliczeń). Niezawodność tego algorytmu jest być może ważniejsza od szybkości jego działania, jeśli rozpatrujemy przyczyny szerokiego rozpowszechnienia sprzętowych implementacji tego algorytmu.
Do wad tego algorytmu należy zaliczyć duże zapotrzebowanie na pamięć
(np.
Algorytm widoczności dla powierzchni Béziera. Aby narysować obraz powierzchni Béziera można (podobnie jak inne powierzchnie zakrzywione) przybliżyć ją dostatecznie dużą liczbą trójkątów i wyświetlić je; metoda opisana niżej prowadzi do otrzymania obrazu, którego dokładność zależy tylko od jego rozdzielczości (a nie od parametrów takich jak liczba trójkątów).
Mając siatkę kontrolną płata Béziera
-
Dokonaj rzutowania punktów kontrolnych,
-
Jeśli największa odległość obrazów tych punktów jest nie większa niż średnica piksela, to oblicz dowolny punkt płata i wektor normalny w tym punkcie, a następnie zbadaj widoczność w
-
W przeciwnym razie podziel płat na mniejsze fragmenty (za pomocą algorytmu de Casteljau) i wywołaj procedurę rekurencyjnie.
Głębokość podziału płata w tym algorytmie adaptacyjnie dopasowuje się do rozdzielczości obrazu. Okazuje się, że podczas działania tego algorytmu łatwo może się zdarzyć, że w wyniku błędu zaokrągleń na obrazie pozostają dziurki (to jest spowodowane zaokrąglaniem współrzędnych obrazu punktu do całkowitych współrzędnych piksela). Ponadto zdarzają się błędy rozstrzygnięcia widoczności, spowodowane arbitralnym wyborem punktu płata, którego głębokość jest badana w teście widoczności. Uodpornienie algorytmu na takie błędy jest nietrywialne, ale możliwe.
9.3.5. Algorytm przeglądania liniami poziomymi
Główną motywacją tego algorytmu była chęć obniżenia kosztu pamięciowego algorytmu z buforem głębokości (ta motywacja ma już znaczenie tylko historyczne). Algorytm przeglądania liniami poziomymi ma wiele wariantów, które umożliwiają m.in. tworzenie obrazów cieni oraz obrazów brył CSG bez wyznaczania jawnej ich reprezentacji. Poniżej jest opisana wersja podstawowa. Jest w niej przyjęte założenie, że ściany są płaskie i nie przenikają się.
-
Zrzutuj wierzchołki ścian na obraz; dla każdej krawędzi znajdź wierzchołek, którego obraz ma mniejszą współrzędną
-
Posortuj tablicę krawędzi w kolejności rosnących mniejszych współrzędnych
-
Utwórz początkowo pustą tablicę krawędzi aktywnych.
-
Dla kolejnych wartości
-
Wyrzuć z tablicy krawędzi aktywnych te, których rzut jest rozłączny z bieżącą poziomą linią rastra.
-
Dołącz do tablicy krawędzi aktywnych te, których obraz przecina się z bieżącą linią poziomą.
-
Oblicz współrzędną
-
Utwórz (początkowo pustą) listę aktywnych ścian; wstaw do niej ściany, których lewa krawędź ma najmniejszą współrzędną
-
Dla pierwszej w liście ściany wyznacz jej prawą krawędź aktywną i współrzędną
-
Narysuj poziomy odcinek w kolorze pierwszej w liście aktywnej ściany; w przypadku (a) usuń ścianę z listy.
-
Usuń z listy wszystkie ściany, których prawa krawędź ma współrzędną
-
Jeśli lista jest niepusta, to dołącz do listy ścian aktywnych ściany, których współrzędna
-
Uporządkuj listę i idź do kroku 4.5, chyba, że lista jest pusta.
-

Wariant algorytmu dla konstrukcyjnej geometrii brył korzysta z uproszczenia zadania przez obniżenie wymiaru; przecięcia płaszczyzny wyznaczonej przez położenie obserwatora i bieżąco przeglądaną linię rastra z wielościennymi prymitywami to wielokąty. Zamiast wykonywać działania CSG na wielościanach, można zatem wyznaczyć przecięcia, sumy, różnice lub dopełnienia wielokątów, a następnie poddać je regularyzacji. Jest to oczywiście zadanie prostsze (ale takie zadanie trzeba rozwiązać dla każdej poziomej linii rastra).
Podobne uproszczenie dotyczy wyznaczania cieni; po wyznaczeniu widocznych odcinków można znaleźć ich części oświetlone. Również to zadanie jest prostsze od wyznaczania oświetlonych części wielokątów, na których leżą te odcinki.
9.3.6. Algorytm cieni z buforem głębokości
Algorytm z buforem głębokości umożliwia narysowanie obrazu z cieniami. Jest to wprawdzie dość kłopotliwe, ale można to zrobić za pomocą sprzętu (np. działającego w standardzie OpenGL, konieczne są pewne rozszerzenia) i wtedy możliwa jest animacja w czasie rzeczywistym, tj. wyświetlanie kilkudziesięciu obrazów na sekundę, przedstawiających poruszające się obiekty. Są jednak pewne ograniczenia: źródło światła musi być reflektorem, emitującym wiązkę promieni świetlnych w pewnym stożku (nie może to być np. nieosłonięta świeca w pokoju), ponadto implementacja tego algorytmu może ,,zawłaszczyć” mechanizm teksturowania (ta trudność jest do ominięcia, jeśli istnieje możliwość bezpośredniego programowania karty graficznej np. w języku GLSL).
Algorytm działa tak: w pierwszym kroku rysujemy scenę, umieszczając obserwatora w punkcie położenia źródła światła; rzutnia jest prostopadłą do osi stożka światła. Po tym etapie nie jest potrzebny obraz, tylko zawartość buforu głębokości.
W etapie drugim zawartość buforu głębokości otrzymaną w pierwszym etapie
wykorzytujemy do określenia tekstury trójwymiarowej; dla dowolnego punktu
w przestrzeni możemy określić, czy jest on oświetlony, porównując jego
współrzędną
W implementacji konieczne jest przeciwdziałanie skutkom błędów zaokrągleń, które mogą spowodować zacienienie obiektu przez samego siebie. Dodatkową wadą jest ograniczona rozdzielczość obrazu wykonanego w pierwszym etapie. Brzeg cienia jest w efekcie ,,schodkowany” — na końcowym obrazie są widoczne piksele obrazu z położenia źródła światła. Przykłądowa implementacja jest w dodatku B.


