Zagadnienia
8. Przegląd innych metod rozwiązywania wielkich układów równań liniowych
Na szczęście, nie ma jednej najlepszej metody rozwiązywania wielkich układów równań liniowych; czyni to oczywiście życie znacznie ciekawszym. Doprowadziło to do skonstruowania dużej liczby konkurencyjnych metod: zarówno bezpośrednich, jak i iteracyjnych. Celem nieniejszego rozdziału jest pobieżne zaznajomienie Czytelnika z niewielką ich reprezentacją. Dobór tej właściwej dla konkretnego zadania nie musi być oczywisty! Szerszy przegląd takich metod znajdziemy m.in. w monografii [13], [].
8.1. Inne metody Kryłowa
Na początek, na podstawie [1] przedstawimy w pewien systematyczny sposób uogólnienie metody CG na szerszą klasę problemów. Następnie zrobimy krótki przegląd wybranych metod Kryłowa, nie opartych na zasadzie minimalizacji.
8.1.1. Uogólnienia metody CG
Wielką zaletą metody PCG jest to, że nie wymaga ona pamiętania całej bazy przestrzeni Kryłowa
Przyjmijmy więc, że
-
macierz
oraz są dane dwie dodatkowe macierze:
-
nieosobliwa macierz lewostronnie ściskająca
-
symetryczna, dodatnio określona macierz
Będziemy zakładali, że macierz ściśnięta
gdzie
W uogólnionej metodzie CG, którą będziemy oznaczali GCG(
| (8.1) |
Twierdzenie 8.1
Przy powyższych założeniach, metoda GCG(
Dowód
Kładąc
Twierdzenie 8.2
Przy powyższych założeniach, błąd na
Dowód
Na mocy wniosku 6.1,
Ponieważ dla dowolnego
| (8.2) |
to w konsekwencji
Stąd zaś wynika, że
Ćwiczenie 8.1
Udowodnij równość (8.2).
Można, postępując analogicznie jak w przypadku klasycznej metody CG wykazać, że GCG(
Stwierdzenie 8.1
W metodzie GCG(
Dowód
W oczywisty sposób
Ponieważ
co dowodzi drugiego punktu.
∎Metodę GCG(
Metoda Odir dla GCG, wersja bazowa
| while not stop begin |
| |
| |
| |
| |
| |
| |
| |
| end |
Algorytm ten jeszcze nie jest gotowy do użycia, albowiem wymaga obliczania
Wśród metod, które dają się skutecznie zaimplementować na podstawie algorytmu Odir(
| Metoda | Ograniczenia | ||
|---|---|---|---|
| CG | |||
| CR | |||
| PCG | |||
| PCR | |||
| CGNR | |||
| CGNE | |||
| D'yakonov |
Aby otrzymać dobrą implementację konkretnej metody opartej na algorytmie Odir, należy zawsze ją dopracować, wykorzystując zależności specyficzne dla konkretnej metody.
Warta uwagi jest metoda PCR, która działa w przypadku, gdy macierz
Uwaga 8.1
Czasami wymaganie, by można było wykonywać mnożenie przez
Ćwiczenie 8.2
Porównaj zbieżność metod: PCG i PCR w przypadku, gdy
W MATLABie dyponujesz gotową implementacją zarówno metody pcg, jak i pcr.
8.1.2. Metody nie oparte na minimalizacji
Zamiast określać kolejną iterację metody, jak dotychczas, przez pewien warunek minimalizacji, możemy inaczej położyć warunek na
(Zwróć uwagę na to, że residua mają być ortogonalne nie do
Tego typu warunek prowadzi m.in. do metody BiCG (ang. Bi-Conjugate Gradient) która wymaga mnożenia przez
W przeciwieństwie do metod minimalizacji, kolejna iteracja może nie być realizowalna mimo, że nie osiągnięto jeszcze rozwiązania — mówimy wtedy potocznie o załamaniu się metody (ang. breakdown).
W innej metodzie, QMR (ang. Quasi-Minimal Residual) — i jej wariancie bez mnożenia przez macierz transponowaną: TFQMR (ang. Transpose-Free QMR) — kolejną iterację wybiera się tak, by zminimalizować (stosunkowo łatwą do obliczenia) wielkość, która ma tylko trochę wspólnego z normą residuum.
Można pokazać [9], że metoda TFQMR dla macierzy
8.2. Metody strukturalne
W bardzo wielu przypadkach, w macierzach układów równań jakie przychodzi nam rozwiązywać w praktycznych zastosowaniach, nie tylko niewiadome są powiązane jedynie z nielicznymi innymi niewiadomymi (co właśnie prowadzi do rozrzedzenia macierzy) ale w dość naturalny sposób można wskazać grupy niewiadomych i równań, które między sobą nie mają żadnych powiązań.
W najogólniejszym przypadku, mielibyśmy więc
| (8.3) |
gdzie
Przykład 8.1 (Strukturalizacja dyskretyzacji równania różniczkowego)
Rozważmy dyskretyzację równania różniczkowego
z jednorodnymi warunkami brzegowymi Dirichleta. Jeśli obszar
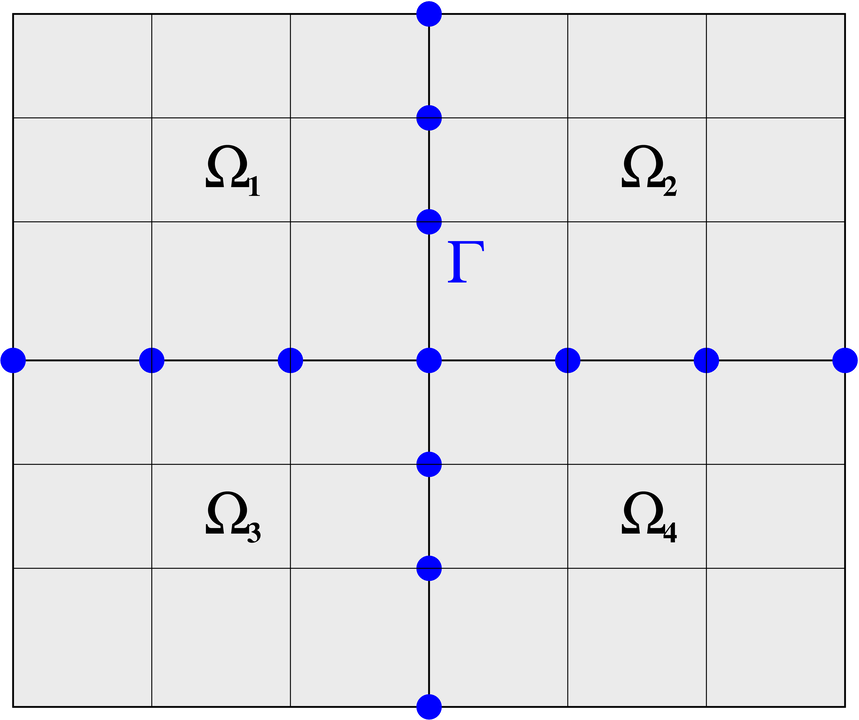
Numerując niewiadome tak, by
| (8.4) |
W pustych miejscach
Dzięki szczególnej postaci macierzy (8.3) możemy podać algorytm typu ,,dziel i rządź” rozwiązywania układu równań
Dokonując blokowej eliminacji Gaussa (najpierw na blokach
-
Oblicz
-
Wyznacz
gdzie
-
Wyznacz
Oczywiście, wszędzie tam, gdzie występują odwrotności macierzy, w praktyce będziemy rozwiązywali układy równań z tymi macierzami.
Zwróćmy uwagę na kilka charakterystycznych cech tego algorytmu:
-
Zarówno w kroku 1. jak i w kroku 3. algorytmu, oba układy możemy rozwiązywać niezależnie od siebie (co daje możliwość równoległej implementacji).
-
Macierze
Jeśli wymiar macierzy
(Nawiasy wskazują kolejność mnożenia.) Możemy więc wyznaczyć iloczyn
Ćwiczenie 8.3
Przedyskutuj, jak rozwiązywać układ równań postaci (8.4).
8.3. Metody wielosiatkowe
Macierze rozrzedzone, które otrzymuje się z dyskretyzacji równań różniczkowych cząstkowych metodą różnic skończonych lub elementu skończonego, mają wiele specjalnych cech, które pozwalają na konstrukcję optymalnych metod rozwiązywania takich zadań. Jedną z takich klas metod są metody wielosiatkowe (ang. multigrid).
Omówimy jej ideę na przykładzie macierzy
Gdyby przyjrzeć się metodzie Jacobiego dla
(w macierzy
Wyrażając błąd
i w konsekwencji,
Jasne jest więc, że najszybszej redukcji ulegną te składowe błędu, które odpowiadają najbliższym zera wartościom
w zależności od parametru relaksacyjnego
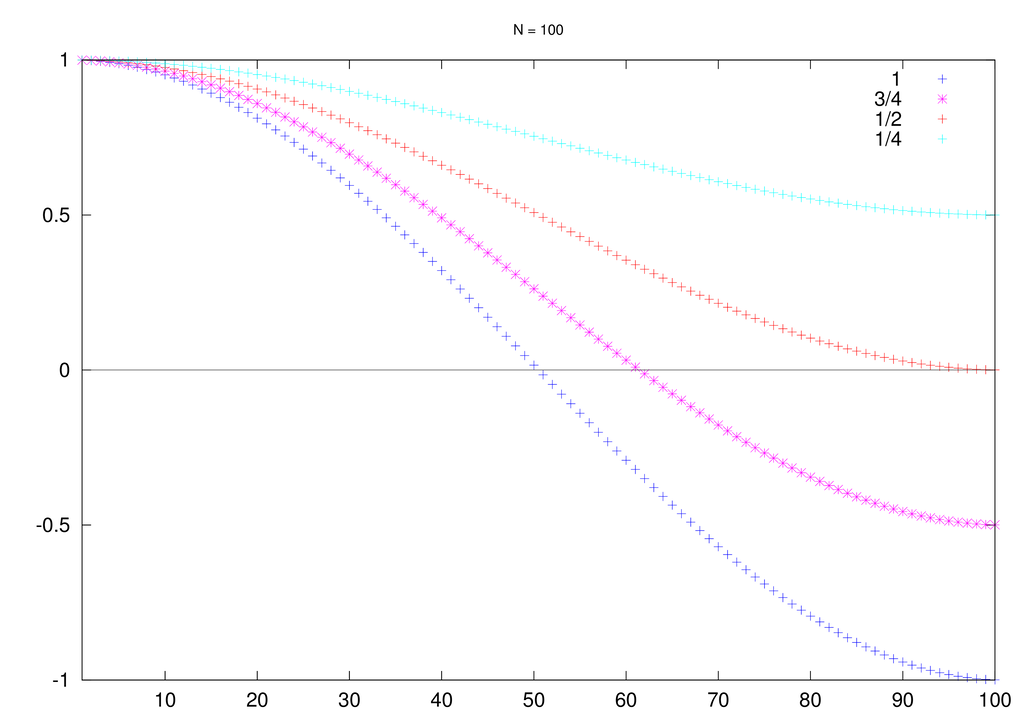
Jak możemy zauważyć, gdy
Ale już dla
W metodzie wielosiatkowej zadanie na rzadszej siatce (potrzebne do wyznaczenia poprawki na siatce najdrobniejszej) potraktujemy rekurencyjnie w ten sam sposób, otrzymując sekwencję zadań coraz mniejszego rozmiaru, którą w pewnym momencie oczywiście będziemy musieli przerwać i rozwiązać zadanie bardzo małego wyniaru metodą bezpośrednią.
Oto więc kolejne etapy jednej iteracji metody wielosiatkowej, wyznaczającej kolejne przybliżenie
-
Wygładzenie (ang. pre-smoothing) — zaczynając od
-
Restrykcja — sformułowanie na rzadszej siatce zadania na poprawkę
-
Gruba poprawka (ang. coarse grid correction) — wyznaczenie poprawki
-
Przedłużenie — wyrażenie poprawki obliczonej na rzadszej siatce w terminach wartości na gęstej siatki. Uwzględnienie poprawki i aktualizacja przybliżenia:
-
Dodatkowe wygładzenie (ang. post-smoothing) — ewentualnie. Znów kilka iteracji jak na pierwszym etapie, z przybliżeniem początkowym równym
Okazuje się, że w ten sposób uzyskujemy metodę, której szybkość zbieżności na modelowym zadaniu nie zależy od parametru dyskretyzacji
Pełna metoda wielosiatkowa
Idąc dalej tym tropem możemy zauważyć, że jako dobre przybliżenie początkowe dla (iteracyjnej) metody wielosiatkowej można byłoby wybrać przybliżone rozwiązanie na rzadszej siatce: wtedy jedynymi istotnymi składowymi błędu na gęstej siatce byłyby składowe szybkozmienne — a te wyeliminowalibyśmy w kilku iteracjach! Oczywiście, wymagane przybliżenie na rzadszej siatce uzyskalibyśmy w ten sam sposób z jeszcze rzadszej siatki; na siatce o największych oczkach moglibyśmy użyć jakiejś metody bezpośredniej.
Pamiętając, że rozwiązywane przez nas zagadnienie — układ równań liniowych — pochodzi z dyskretyzacji pewnego równania różniczkowego musimy zdać sobie sprawę z tego, że nie ma sensu rozwiązywać go z dokładnością większą niż dokładność aproksymacji samej dyskretyzacji! Dlatego iterację można przerwać po osiągnięciu z góry zadanego poziomu błędu aproksymacji rozwiązania zadania różniczkowego. Gdy będziemy startować z przybliżenia wyznaczonego metodą opisaną powyżej, okazuje się, że często wystarczy tylko niewielka, niezależna od
Taka metoda wyznaczania rozwiązania zadania powstałego po dyskretyzacji równania różniczkowego — którą tutaj tylko zasygnalizowaliśmy w uproszczeniu — nazywa się pełną metodą wielosiatkową (ang. full multigrid). Choć wciąż jest to metoda iteracyjna, ma ona cechy metody bezpośredniej. Okazuje się, że koszt wyznaczenia rozwiązania tą metodą jest rzędu


