3.1. Przykłady
Moje wykłady ograniczają się do zagadnień leżących w kompetencji rachunku
prawdopodobieństwa i statystyki. U podstaw symulacji stochastycznych leży
generowanie ,,liczb pseudo-losowych”, naśladujących zachowanie zmiennych
losowych o rozkładzie jednostajnym. Jak to się robi, co to jest
,,pseudo-losowość”, czym się różni od ,,prawdziwej losowości”? To
są fascynujące pytania, którymi zajmuje się: teoria liczb, teoria
(chaotycznych) układów dynamicznych oraz filozofia.
Dyskusja na ten temat przekracza ramy tych wykładów.
Z punktu widzenia użytkownika, ,,liczby losowe”
są bardzo łatwo dostępne, bo ich generatory są wbudowane w systemy
komputerowe. Przyjmę pragmatyczny
punkt widzenia i zacznę od następującego założenia.
Założenie 3.1
Mamy do dyspozycji potencjalnie nieskończony ciąg
niezależnych zmiennych losowych U1,…Un…
o jednakowym rozkładzie U0,1.
W języku algorytmicznym: przyjmujemy, że każdorazowe wykonanie
instrukcji zapisanej w pseudokodzie
wygeneruje kolejną (nową) zmienną Un. Innymi słowy, zostanie wykonane nowe, niezależne
doświadczenie polegające na wylosowaniu przypadkowo wybranej liczby z przedziału
]0,1[.
Przykład 3.1
Wykonanie pseudokodu
| for i=1 to 10 |
| begin |
| Gen U∼U0,1 |
| write U |
| end |
da, powiedzmy, taki efekt:
0.32240106 0.38971803 0.35222521 0.22550039 0.04162166
0.13976025 0.16943910 0.69482111 0.28812341 0.58138865
Nawiasem mówiąc, rzeczywisty kod w R, który wyprodukował nasze 10
liczb losowych był taki:
U <- runif(10);U
Język R jest zwięzły i piękny, ale nasz pseudokod ma pewne walory dydaktyczne.
Zajmiemy się teraz pytaniem, jak ,,wyprodukować” zmienne losowe o różnych rozkładach, wykorzystując zmienne U1,U2,….
W tym podrozdziale pokażę kilka przykładów, a w następnym przedstawię rzecz nieco bardziej systematycznie.
Przykład 3.2 (Rozkład Wykładniczy)
To jest wyjątkowo łatwy do generowania rozkład – wystarczy taki algorytm:
Na wyjściu, X∼Exλ. Żeby się o tym przekonać, wystarczy obliczyć dystrybuantę tej
zmiennej losowej:
PX≤x=P-1λlogU≤x=PU≥e-λx=1-e-λx.
Jest to najprostszy przykład ogólnej metody ,,odwracania dystrybuanty”, której poświęcę następny
podrozdział.
Przykład 3.3 (Generacja rozkładu normalnego)
Zmienna losowa
ma w przybliżeniu standardowy rozkład normalny N0,1. Wynika to
z Centralnego Twiedzenia Granicznego (jeśli uznamy, że liczba 12 jest
dostatecznie bliska ∞; zauważmy, że EX=0 i VarX=1). Oczywiście, w czasach szybkich komputerów
ta przybliżona metoda zdecydowanie nie jest polecana. Jest natomiast pouczające zbadać (symulacyjnie!) jak dobre jest przybliżenie. Faktycznie
bardzo trudno odróżnić próbkę X1,…,Xn wyprodukowaną przez powyższy algorytm od próbki pochodzącej dokładnie z rozkłdu
N0,1 (chyba, że n jest ogromne).
Przykład 3.4 (Algorytm Boxa-Müllera)
Oto, dla porównania, bardziej współczesna – i całkiem dokładna metoda generowania zmiennych
o rozkładzie normalnym.
| Gen U1;Θ:=2πU1, |
| Gen U2;R:=-2lnU2, |
| Gen X:=RcosΘ; Y:=RsinΘ |
Na wyjściu obie zmienne X i Y mają rozkład N0,1 i w dodatku są niezależne.
Uzasadnienie poprawności algorytmu Boxa-Müllera opiera się na dwu faktach: zmienna R2=X2+Y2 ma rozkład
χ22=Ex1/2, zaś kąt Θ między osią i promieniem wodzącym punktu X,Y ma
rozkład U0,2π.
Ciekawe, że łatwiej jest generować zmienne losowe normalne ,,parami”.
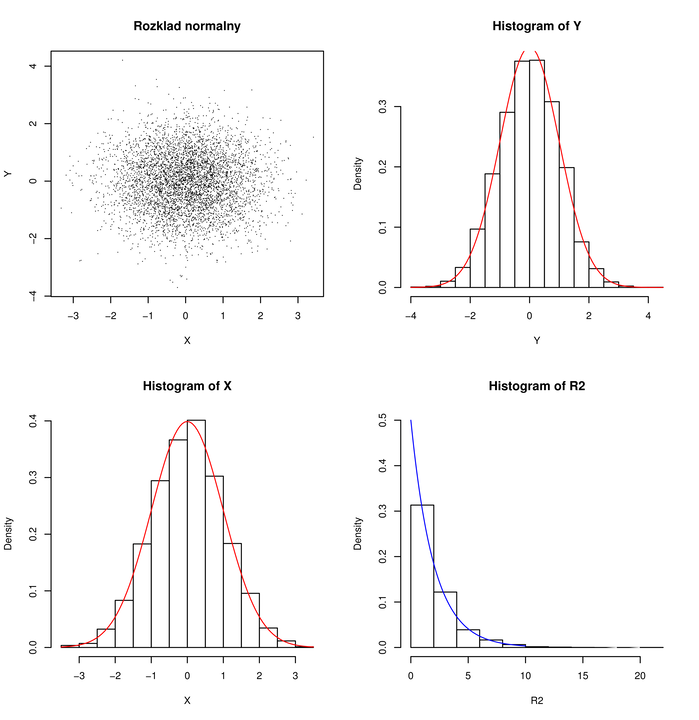
Doświadczenie, polegające na wygenerowaniu zmiennych losowych X i Y powtórzyłem
10000 razy. Na Rysunku 3.1 widać 10000 wylosowanych w ten sam sposób i niezależnie
punktów X,Y, histogramy i gęstości brzegowe X i Y
(każda ze współrzędnych ma rozkłd N0,1) oraz histogram i gęstość R2=X2+Y2 (
rozkład wykładniczy Ex1/2).
Histogram jest ,,empirycznym” (może w obecnym kontekście należałoby powiedzieć
,,symulacyjnym”) odpowiednikiem gęstości: spośród wylosowanych wyników zliczane są punkty
należące do poszczególnych przedziałów.
Przykład 3.5 (Rozkład Poissona)
Algorytm przedstawiony niżej nie jest efektywny, ale jest prosty do zrozumienia.
| c:=e-λ |
| Gen U; P:=U; N:=0 |
| while P≥c do |
| begin Gen U; P:=PU; N:=N+1 end |
Na wyjściu N∼Poissλ.
Istotnie, niech E1,…,En,… będą i.i.d. ∼Ex1 i
Sn=E1+⋯+En. Wykorzystamy znany fakt, że N=maxn:Sn≤λ ma rozkład
Poissλ.
Zmienne o rozkładzie wykładniczym przedstawiamy jako Ei=-lnUi – patrz Przykład
3.2.
Zamiast dodawać zmienne Ei możemy mnożyć zmienne Ui. Mamy
N=maxn:Pn≥e-λ, gdzie Pn=U1⋯Un.
3.2. Metoda przekształceń
Zmienna losowa Y, która ma postać
Y=hX, a więc jest pewną funkcją zmiennej X, w naturalny sposób ,,dziedziczy” rozkład prawdopodobieństwa
zgodnie z ogólnym schematem P(Y∈⋅)=P(h(X)∈⋅)=P(X∈h-1(⋅)) (,,wykropkowany” argument jest zbiorem).
Przy tym zmienne X i Y nie muszą być jednowymiarowe. Jeśli obie zmienne mają ten sam wymiar i
przekształcenie h jest dyfeomorfizmem, to dobrze znany wzór wyraża gęstość rozkładu Y
przez gęstość X (Twierdzenie 5.1).
Odpowiednio dobierając funkcję h możemy ,,przetwarzać” jedne rozkłady prawdopodobieństwa na inne, nowe.
Prawie wszystkie algorytmy generowania zmiennych losowych
zawierają przekształcenia zmiennych losowych jako część składową.
W niemal ,,czystej” postaci metoda przekształceń pojawiła się w algorytmie Boxa-Müllera,
Przykładzie 3.4. Najważniejszym być może szczególnym przypadkiem metody przekształceń
jest odwracanie dystrybuanty.
3.2.1. Odwrócenie dystrybuanty
Faktycznie, ta metoda została już wykorzystana w Przykładzie 3.2.
Opiera się ona na prostym fakcie. Jeżeli F jest ciągłą i ściśle rosnącą dystrybuantą,
U∼U0,1 i X=F-1U, to X=F-1U∼F.
Następująca definicja funkcji ,,pseudo-odwrotnej” pozwala
pozbyć się kłopotliwych założeń.
Definicja 3.1
Jeżeli F:R→0,1 jest dowolną dystrybuantą, to funkcję F-:]0,1[→R określamy
wzorem:
Stwierdzenie 3.1
Nierówność F-u≤x jest równoważna u≤Fx, dla dowolnych u∈]0,1[ i x∈R.
Dowód
Z prawostronnej ciągłości dystrybuanty F wynika, że kres dolny w Definicji
3.1 jest osiągany, czyli
Z drugiej strony,
|
F-(F(x))=min{y:F(y≥F(x)}≤x, |
|
po prostu dlatego, że x∈{y:F(y≥F(x)}. Teza stwierdzenia natychmiast wynika z dwóch
nierówności powyżej.
∎
Wniosek 3.1 (Ogólna metoda odwrócenia dystrybuanty)
Jeżeli U∼U0,1 i X=F-U, to PX≤x=Fx. W skrócie, X∼F.
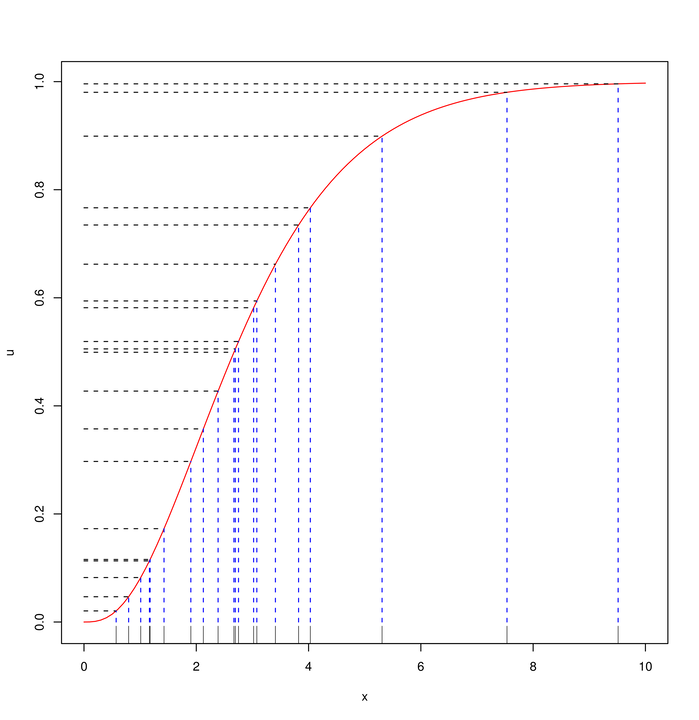
Na Rysunku 3.2 widać 20 punktów U1,…,U20, które wylosowałem z rozkładu U0,1
(na osi pionowej) i odpowiadające im punkty Xi=F-1Ui (na osi poziomej). W tym przypadku,
F jest dystrybuantą rozkładu Gamma3,1 (linia krzywa). Najważniejszy fragment kodu w R jest taki:
curve(pgamma(x,shape=3,rate=1), from=0,to=10) # rysowanie F
U <- runif(20);X <- qgamma(U,shape=3,rate=1)
Zauważmy, że ta metoda działa również dla rozkładów dyskretnych i sprowadza się wtedy do
metody ,,oczywistej”.
Przykład 3.6 (Rozkłady dyskretne)
Załóżmy, że PX=i=pi dla i=1,2,… i ∑pi=1.
Niech s0=0, sk=∑i=1kpi. Jeżeli F jest dystrybuantą zmiennej
losowej X, to
|
F-u=iwtedy i tylko wtedy gdysi-1<u≤si. |
|
Odwracanie dystrybuanty ma ogromne znaczenie teoretyczne, bo jest całkowicie ogólną
metodą generowania dowolnych zmiennych losowych jednowymiarowych. Może się to wydać dziwne,
ale w praktyce ta metoda jest używana stosunkowo rzadko, z dwóch wzgłędów:
-
Obliczanie F- j bywa trudne i nieefektywne.
-
Stosowalność metody ogranicza się do zmiennych losowych jednowymiarowych.
Podam dwa przykłady, w których zastosowanie metody odwracanie dystrybuanty jest rozsądne
Przykład 3.7 (Rozkład Weibulla)
Z definicji, X∼Weibullβ, jeśli
dla x≥0. Odwrócenie dystrybuanty i generacja X są łatwe:
Przykład 3.8 (Rozkład Cauchy'ego)
Gęstość i dystrybuanta zmiennej X∼Cauchy0,1 są następujące:
|
fx=1π11+x2,Fx=12+1πarctanx. |
|
Można tę zmienną generować korzystająć z wzoru:
3.3. Metoda eliminacji
To jest najważniejsza, najczęściej stosowana i najbardziej uniwersalna metoda.
Zacznę od raczej oczywistego faktu, który jest w istocie probabilistycznym sformułowaniem
definicji prawdopodobieństwa warunkowego.
Stwierdzenie 3.2
Przypuśćmy, że Z=Z1,…,Zn,… jest ciągiem niezależnych zmiennych losowych o
jednakowym rozkładzie, o wartościach w przestrzeni Z. Niech C⊆Z będzie
takim zbiorem, że PZ∈A>0. Niech
Zmienne losowe N i ZN są niezależne, przy tym
|
P(ZN∈B)=P(Z∈B|Z∈C)dla dowolnegoB⊆Z, |
|
zaś
|
PN=n=pqn-1,n=1,2,…,gdziep=PZ∈C. |
|
Dowód
Wystarczy zauważyć, że
|
P(XN∈B,N=n)=P(Z1∉C,…,Zn-1∉C,Zn∈C∩B)=P(Z1∉C)⋯P(Zn-1∉C)P(Zn∈C∩B)=qn-1P(Z∈C∩B)=qn-1P(Z∈B|Z∈C)p. |
|
∎
W tym Stwierdzeniu Z może być dowolną przestrzenią mierzalną, zaś C i B – dowolnymi
zbiorami mierzalnymi. Stwierdzenie mówi po prostu, że prawdopodobieństwo warunkowe odpowiada
doświadczeniu losowemu powtarzanemu aż do momentu spełnienia warunku, przy
czym rezultaty poprzednich doświadczeń się ignoruje (stąd nazwa: eliminacja).
3.3.1. Ogólny algorytm
Zakładamy, że umiemy generować zmienne losowe o gęstości g, a chcielibyśmy
otrzymać zmienną o gęstości proporcjonalnej do funkcji f. Zakładamy, że 0≤f≤g.
| repeat |
| Gen Y∼g; |
| Gen U∼U0,1 |
| until U≤fYgY; |
| X:=Y |
Dowód poprawności algorytmu
Na mocy Stwierdzenia 3.2, zastosowanego do zmiennych losowych
Z=Y,U wystarczy pokazać, że
|
P(Y∈B|U≤f(Y)/g(Y))=∫Bfydy∫Xfydy, |
| (3.1) |
gdzie X jest przestrzenią wartości zmiennej losowej Y (i docelowej zmiennej losowej X).
Warunkujemy teraz przez wartości zmiennej Y, otrzymując
|
P(Y∈B,U≤f(Y)/g(Y))∫BP(U≤f(Y)/g(Y)|Y=y)g(y)dy∫Bfygyg(y)dy=∫Bf(y)dy. |
|
Skorzystaliśmy z niezależności Y i U oraz ze wzoru na prawdopodobieństwo całkowite. Otrzymaliśmy
licznik we wzorze (3.1). Mianownik dostaniemy zastępując
B przez X.
∎
Uwaga 3.1
Ważną zaletą algorytmu jest to, że nie trzeba znać ,,stałej normującej” gęstości f/∫f, czyli
liczby ∫f.
Uwaga 3.2
W istocie X może być ogólną przestrzenią z miarą μ. Żeby poczuć się pewniej
założę, że X jest przestrzenią polską i miara μ jest σ-skończona.
Możemy rozważać
gęstości i całki względem miary μ – dowód poprawości algorytmu eliminacji
nie ulega zmianie. Nie widzę wielkiego sensu w przeładowaniu notacji,
można się umówić, że symbol ∫⋯dx jest skrótem ∫⋯μdx.
Dociekliwy Czytelnik powinien zastanowić się, w jakiej sytuacji potrafi uzasadnić wszystkie
przejścia w dowodzie, powołując się na odpowiednie własności prawdopodobieństwa warunkowego
(np. twierdzenie o prawdopodobieństwie całkowitym itp.).
W każdym razie, algorytm eliminacji działa poprawnie, gdy
-
X=Rd, gęstości są względem miary Lebesgue'a;
-
X dyskretna, gęstości są względem miary liczącej.
Uwaga 3.3
Efektywność algorytmu zależy od dobrania gęstości g tak, aby majoryzowała funkcję f ale nie
była dużo od niej większa.
Istotnie, liczba prób N do zaakceptowania X:=Y ma rozkład geometryczny z
prawdopodobieństwem sukcesu p=∫f/∫g, zgodnie ze Stwierdzeniem 3.2,
zatem EN=1/p. Iloraz p powinien być możliwie bliski jedynki, co jest możliwe jeśli
,,kształt funkcji g jest podobny do f.
Zwykle metoda eliminacji stosuje się w połączeniu z odpowiednio dobranymi przekształceniami.
Zilustrujmy to na poniższym przykładzie.
Przykład 3.9 (Rozkład Beta, algorytm Bermana)
Niech U i V będą niezależnymi zmiennymi losowymi o rozkładzie jednostajnym
U0,1. Pod warunkiem, że U1/α+V1/β zmienna losowa
U ma gęstość fUu proporcjonalną do funkcji
1-u1/αβ.
Zmienna losowa X=U1/α ma gęstość
fXx=fUxαdxα/dx∝1-xβxα.
Zatem X ma rozkład Betaα,β+1.
Algorytm jest więc następujący:
| repeat |
| Gen U,V |
| X:=U1/α; Y:=V1/β |
| until X+Y≤1; |
| return X |
Efektywność tego algorytmu jest tym większa, im mniejsze są parametry
α i β (frakcja zakceptowanych U jest wtedy duża).
Dla ilustracji rozpatrzmy dwa przypadki.
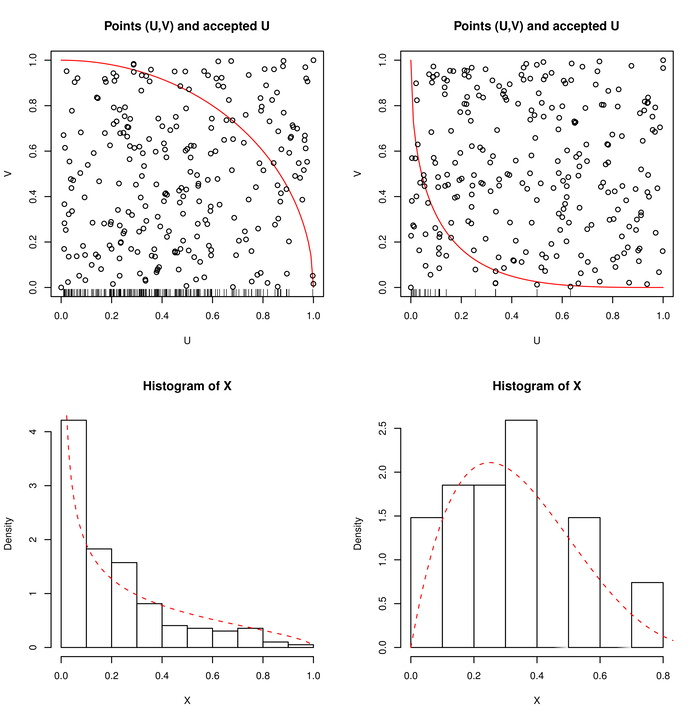
Na rysunku 3.3, po lewej stronie α=β=0.5. Spośród n=250 punktów zaakceptowano N=197.
Przerywana krzywa jest wykresem gęstości rozkładu Beta0.5,1,5.
Po prawej stronie α=2, β=3. Spośród n=250 punktów zaakceptowano tylko
N=24. Tym razem wykres pokazuje gęstość rozkładu Beta2,4.
Zaakceptowane punkty U (o gęstości fU) są widoczne w postaci ,,kreseczek” na górnych rysunkach. Ciągłą linią jest narysowana
funkcja 1-u1/αβ∝fUu.
3.3.2. Eliminacja w R
Zasadniczy algorytm eliminacji opisany w Stwierdzeniu 3.2 i w Punkcie 3.3.1 polega na powtarzaniu generacji
tak długo, aż zostanie spełnione kryterium akceptacji. Liczba prób jest losowa, a rezultatem jest jedna zmienna losowa o zadanym rozkładzie.
Specyfika języka R narzuca inny sposób przeprowadzania eliminacji. Działamy na wektorach, a więc od razu produkujemy n niezależnych zmiennych
X1,…,Xn o rozkładzie g, następnie poddajemy je wszystkie procedurze eliminacji. Przez sito eliminacji, powiedzmy Ui<fXi/gXi,
przechodzi pewna część zmiennych. Otrzymujemy losową liczbę zmiennych o rozkładzie proporcjonalnym do f. Liczba zaakceptowanych zmiennych
ma oczywiście rozkład dwumianowy Binn,p z p=∫f/∫g. To nie jest zbyt eleganckie.
W sztuczny sposób można zmusić R do wyprodukowania zadanej, nielosowej liczby zaakceptowanych zmiennych,
ale jeśli nie ma specjalnej konieczności, lepiej tego nie robić (przymus rzadko prowadzi do pozytywnych rezultatów).
Dla przykładu, generowanie zmiennych X,Y o rozkładzie jesnostajnym na kole x2+y2≤1 może w praktyce wyglądać tak:
> n <- 1000
> X <- runif(n,min=-1,max=1) \# generowanie z rozkładu jednostajnego na [-1,1]
> Y <- runif(n,min=-1,max=1)
> Accept <- X^2+Y^2<1 \# wektor logiczny
> X <- X[Accept]
> Y <- Y[Accept]
Otrzymujemy pewną losową liczbę (około 785) punktów X,Y w kole jednostkowym.
3.4. Metoda kompozycji
Jest to niezwykle prosta technika generowania zmiennych losowych. Załóżmy, że docelowy rozkład jest
mieszanką prostszych rozkładów prawdopodobieństwa, czyli jego gęstość jest kombinacją wypukłą postaci
|
fx=∑i=1kpifix,pi≥0,∑i=1kpi=1. |
|
Jeśli umiemy losować z każdej gęstości fi to możemy uruchomić dwuetapowe losowanie:
| Gen I∼p(⋅); { to znaczy PI=i=pi } |
| Gen X∼fI; { jeśli i=i to uruchamiamy generator rozkładu fi } |
| return X |
Jasne, że na wyjściu mamy
X∼F. W istocie jest to szczególny przypadek metody rozkładów warunkowych,
którą omówię później, w Rozdziale
5.
Przykład 3.10 (Rozkład Laplace'a)
Rozkład Laplace'a (podwójny rozkład wykładniczy) ma gęstość
Można go ,,skomponować” z dwóch połówek rozkładu wykładniczego:
| Gen W∼Exλ; { generujemy z rozkładu wykładniczego } |
| Gen U∼U0,1; |
| if U<1/2 then X:=W else X:=-W { losowo zmieniamy znak } |
| return X |