8.1. Losowanie istotne
Zadziwiająco skutecznym sposobem na oba przedstawione wyżej kłopoty
jest losowanie istotne (Importance Sampling, w skrócie IS).
Przypuśćmy, że umiemy losować z rozkładu o gęstości q. Zauważmy, że
|
θ=∫Xpxqxfxqxdx=EqpXqXfX=EqwXfX, |
|
gdzie wx=px/qx. Piszemy tu wzory dla całek ale oczywiście dla sum jest tak samo.
Niech X1,…,Xn będą niezależnymi zmiennymi losowymi o jednakowym rozkładzie g,
|
θ⌃n=θ⌃nIS1=∑i=1nWifXi, |
| (8.1) |
gdzie
traktujemy jako wagi wylosowanych punktów Xi.
Z tego co wyżej powiedzieliśmy wynika, że Eqθ⌃n=θ oraz
θ⌃n→θ prawie na pewno, gdy n→∞. Mamy więc estymator nieobciążony
i zgodny. Milcząco założyliśmy, że qXi>0 w każdym wylosowanym punkcie, czyli, że
x:px>0⊆x:qx>0. Z tym zwykle nie ma wielkiego kłopotu.
Ponadto musimy założyć, że umiemy obliczać funkcję w w każdym wylosowanym punkcie.
Jeśli znamy tylko p′x=Zpx a nie znamy stałej Z to jest kłopot. Możemy tylko obliczyć Wi′=p′Xi/qXi=ZWi. Używamy zatem nieco innej postaci estymatora
IS, mianowicie
|
θ⌃n=θ⌃nIS2=∑i=1nWifXi∑i=1nWi. |
| (8.2) |
Ten estymator wygląda dziwnie, bo w mianowniku występuje estymator jedynki
ale chodzi o to, że we wzorze (8.2) w przeciwieństwie do (8.1)
możemy zastąpić Wi przez Wi′, bo nieznany czynnik Z skraca się.
Możemy jeszcze zapisać nasz estymator w zgrabnej formie
gdzie W~i=Wi/∑jWj są unormowanymi wagami. Trzeba jednak
pamiętać, że to ,,unormowanie” polega na podzieleniu wag przez zmienną losową. W rezultacie
estymator IS2 jest obciążony. Jest jednak mocno zgodny, bo licznik
we wzorze (8.2) po podzieleniu przez n zmierza do θ a mianownik do 1,
prawie na pewno.
Estymator IS2 jest znacznie częściej używany niż IS1. Oprócz uniezależnienia się od stałej normującej, jest jeszcze inny powód. Okazuje się, że (pomimo obciążenia)
estymator IS2 może być bardziej efektywny. Sens tego pojęcia wyjaśnimy w
następnym podrozdziale. Zarówno dobór przykładów jak i ogólny tok rozważań jest zapożyczony z monografii Liu [15].
8.2. Efektywność estymatorów MC
Naturalne jest żądanie, aby estymator był mocno zgodny, θ⌃n→θ prawie na pewno przy
n→∞. Znaczy to, że zbliżymy się dowolnie blisko aproksymowanej wielkości, gdy tylko dostatecznie długo przedłużamy symulacje. Chcielibyśmy jednak wiedzieć coś konkretniejszego,
oszacować jak szybko błąd aproksymacji θ⌃n-θ maleje do zera i jakie n wystarczy
do osiągnięcia wystarczającej dokładności. Przedstawimy teraz
najprostsze i najczęściej stosowane w praktyce podejście, oparte na tzw. asymptotycznej
wariancji i konstrukcji asymptotycznych przedziałów ufności.
W typowej sytuacji estymator θ⌃n ma następującą własność, nazywaną
asymptotyczną normalnością:
w sensie zbieżności według rozkładu. W konsekwencji, dla ustalonej liczby a>0,
|
Pθ⌃n-θ⩽zσn→Φz-Φ-z=2Φz-1,n→∞, |
|
gdzie Φ jest dystrybuantą rozkładu N0,1. Często nie znamy asymptotycznej
wariancji σ2 ale umiemy skonstruować jej zgodny estymator σ⌃n2.
Dla ustalonej ,,małej” dodatniej liczby α łatwo dobrać kwantyl rozkładu normalnego z=z1-α/2 tak, żeby 2Φz-1=1-α. Typowo
α=0.05 i z=z0.975=1.9600≈2. Otrzymujemy
|
Pθ⌃n-θ⩽z1-α/2σ⌃nn→1-α.n→∞. |
|
Ten wzór interpretuje się w praktyce tak: estymator θ⌃n ma błąd nie przekraczający
zσ⌃n/n z prawdopodobieństwem około 1-α. W żargonie statystycznym 1-α jest nazywane asymptotycznym poziomem ufności.
Chociaż opisame powyżej podejście ma swoje słabe strony, to prowadzi do prostego kryterium
porównywania estymatorów. Przypuśćmy, że mamy dwa estymatory θ⌃nI i θ⌃nII, oba asymptotycznie normalne, o asymptotycznej wariancji σI2 i σII6
odpowiednio. Przypuśćmy dalej, że dla obliczenia pierwszego z tych estymatorów generujemy
nI2 punktów, zaś dla drugiego nI2. Błędy obu estymatorów na tym mym poziomie istotności są ograniczone przez, odpowiednio, zσI/nI i
zσII/nII. Przyrównując te wyrażenia do siebie dochodzimy do wniosku, że oba estymatory osiągają podobną dokładność, jeśli
nI/nII=σII2/σI2. Liczbę
nazywamy względną efektywnością (asymptotyczną). Czasami dobrze jest wybrać
za ,,naturalny punkt odniesienia” estymator CMC i zdefiniować efektywność
estymatora θ⌃n o asymptotycznej wariancji σ2 jako
|
effθ⌃n=effθ⌃n,θ⌃nCMC=σCMC2σ2. |
|
Mówi się też, że jeśli wygenerujemy próbkę n punktów i obliczymy θ⌃n to ,,efektywna liczność próbki” (ESS, czyli effective sample size) jest n/effθ⌃n. Tyle
bowiem należałoby wygenerować punktów stosując CMC, żeby osiągnąć podobną dokładność.
Asymptotyczna normalność prostego estymatora CMC wynika wprost z Centralnego Twierdzenia Granicznego (CTG). Istotnie, jeśli generujemy niezależnie
X1,…,Xn o jednakowym rozkładzie π, to
|
nθ⌃nCMC-θ=1n∑i=1nfXi-θ→N0,σCMC2,n→∞, |
|
gdzie
|
σCMC2=VarpfX=∫fx-θ2pxdx. |
|
Zupełnie podobnie, dla losowania istotnego w formie (8.1) otrzymujemy
asymptotyczną normalność i przy tym
|
σIS12=VarqwXfX=EqfXpX-θqX2qX2=∫fxpx-θqx2qxdx. |
|
Z tego wzorku widać, że estymator może mieć wariancję zero jeśli
qx∝fxpx. Niestety, żeby obliczyć qx potrzebna jest znajomość
współczynnika proporcjonalności, który jest równy…θ. Nie wszystko jednak stracone.
Pozostaje ważna reguła heurystyczna:
Gęstość qx należy tak dobierać, aby jej ,,kształt” był zbliżony do funkcji
fxpx.
Dla drugiej wersji losowania istotnego, (8.2), asymptotyczna normalność wynika z
następujących rozważań:
|
nθ⌃nIS2-θ=1n∑i=1nWifXi-θWi1n∑i=1nWi→N0,σIS22,n→∞, |
|
gdzie
|
σIS22=VarqwXfX-θ=VarqwXfX-2θCovqwX,wXfX+θ2VarqwX=σIS12+θ-2CovqwX,wXfX+θVarqwX. |
|
Wyrażenie w kwadratowym nawiasie może być ujemne, jeśli jest duża dodatnia korelacja
zmiennych wX i wXfX. W tej sytuacji estymator IS2 jest lepszy od IS1. Okazuje się
więc rzecz na pozór paradoksalna: dzielenie przez estymator jedynki może poprawić estymator.
Poza tym oba estymatory IS1 i IS2 mogą mieć mniejszą (asymptotyczną) wariancję, niż CMC. Jeśli
efektywność jest większa niż 100%, to używa się czasem określenia ,,estymator superefektywny”.
Jeśli interesuje nas obliczenie wartości oczekiwanej dla wielu różnych funkcji f, to
warto wprowadzić uniwersalny, niezależny of f wskaźnik efektywności. Niezłym takim wskaźnikiem jest VarqwX.
Istotnie, ,,odchylenie χ2” pomiędzy gęstością instrumentalną p i docelową p, jest określone poniższym wzorem:
|
χ2=χ2q,p=∫qx-px2qxdx=EqqX-pXqX2=Eq1-wX2=VarqwX. |
|
Niestety, to ,,odchylenie” nie jest odległością, bo nie spełnia warunku symetrii.
Niemniej widać, że małe wartości VarqwX świadczą o bliskości q i p.
Zauważmy, jeszcze, że VarqwX jest wariancją asymptotyczną estymatora
IS1 dla funkcji fx=1.
Zgodnym estymatorem wielkości χ2 jest
|
χ⌃2=1n-1∑i=1nW¯n-Wi2W¯2. |
|
Dzielenie przez n-1 (a nie n) wynika z tradycji. Dzielenie przez W¯2 powoduje, że
estymator nie wymaga znajomości czynnika normującego gęstość p.
Jest to w istocie estymator typu IS2. Estymator typu IS1 jest równy po prostu ∑1-Wi2/n, ale można go stosować tylko gdy znamy czynnik normujący.
Wprowadźmy teraz bardziej formalnie pojęcie ważonej próbki. Niech X,W będzie
parą zmiennych losowych o wartościach w X×[0,∞[. Jeśli rozkład brzegowy
X ma gęstość q zaś docelowa gęstość jest postaci px=p′x/Z to żądamy aby
dla prawie wszystkich x. Mówimy wtedy, że próbka jest dopasowana do rozkładu p. Idea jest taka jak w losowaniu istotnym IS2: dopasowanie gwarantuje, że dla każdej funkcji f mamy EqfXW=ZEpfX. Nie jest konieczne, aby W było deterministyczną funkcją X. Pozostawiamy sobie możliwość generowania wag losowo.
Stała normująca Z jest na ogół nieznana, a więc
waga W jest określona z dokładnością do proporcjonalności. W poprzednich
podrozdziałach dla podkreślenia opatrywaliśmy takie nieunormowane wagi znaczkiem ,,prim”
ale teraz to pomijamy.
Gdy generujemy ciąg ważonych zmiennych losowych Xi,Wi,…,Xn,Wn, to
oczywiście wymaga się aby E(Wi|Xi=x)=Zp(x)/q(x), gdzie
stała Z musi być jednakowa dla wszystkich i=1,…,n.
Jeśli założy się niezależność par Xi,Wi, to zgodność i asymptotyczną normalność estymatora θ⌃nIS2 danego równaniem (8.2) wykazuje się tak samo jak poprzednio. Asymptotyczna wariancja jest równa
Z-2VarqWfX-θ; czynnik Z-2 pojawia się dlatego, że operujemy nieunormowanymi wagami.
Jest jednak dużo ciekawych zastosowań, w których
punkty Xi są zależne. Wtedy nawet zgodność estymatora θ⌃nIS2 nie
jest automatyczna. Asymptotyczna normalność może zachodzić z graniczną
wariancją zupełnie inną niż w przypadku niezależnym lub nie zachodzić wcale.
8.3. Ważona eliminacja
Interesujące jest powiązanie idei eliminacji z ważeniem próbek. Czysta metoda eliminacji pracuje w sytuacji, gdy gęstość ,,instrumentalna” majoryzuje funkcję proporcjonalną do gęstości docelowej, czyli Zpx=p′x⩽qx. Jeśli ten warunek nie jest spełniony, to można
naprawić odpowiednio ważąc wylosowaną próbkę. Dokładniej, algorytm ważonej eliminacji
(Rejection Control, w skrócie RC) jest następujący.
| repeat |
| Gen Y∼q; |
| W:=p′Y/qY; |
| if W⩽1 then |
| begin |
| W:=1; |
| Gen U∼U0,1 |
| end; |
| until (W>1 or U<W) |
| X:=Y |
Dowód poprawności algorytmu
Zauważmy, że prawdopodobieństwo akceptacji Y w tym algorytmie jest równe aY, gdzie
|
ax=p′x∧qxqx=p′xqxjeśli p′x⩽qx;1jeśli p′x>qx. |
|
Rozkład X na wyjściu algorytmu ma zatem gęstość ∝p′x∧qx. Waga
W=wY jest więc ,,dopasowana” do rozkładu p w sensie zdefiniowanym w poprzednim podrozdziale, bo
|
wx=p′xp′x∧qx=1jeśli p′x⩽qx;p′xqxjeśli p′x>qx. |
|
∎
Zauważmy jeszcze, jak należy modyfikować wagi w RC, jeśli na wejściu mamy próbkę ważoną,
dopasowaną do p.
Jeżeli punkt Y, pochodzący z rozkładu q, ma na wejściu wagę WY=p′Y/qY, to
na wyjściu zaakceptowany punkt X=Y ma rozkład ∝p′x∧qx i powinien mieć wagę WX=p′Y/p′Y∧qY. Widać stąd, że
gdzie a(⋅) jest napisanym wyżej prawdopodobieństwem akceptacji w RC.
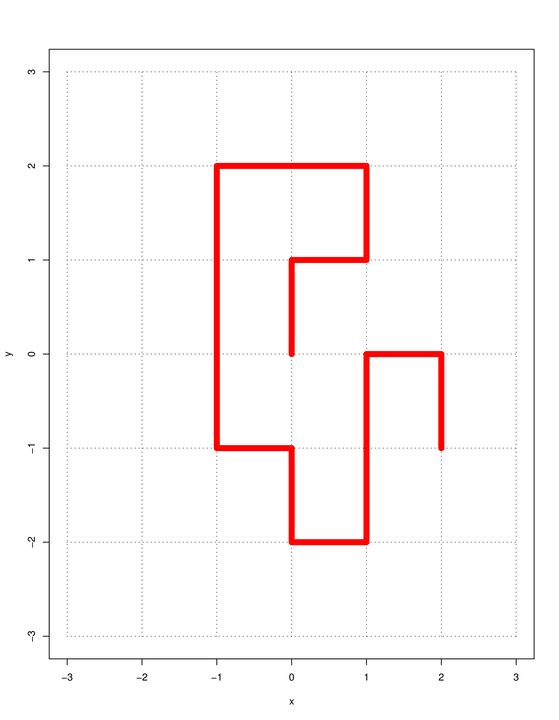
Przykład 8.1 (Nie-samo-przecinające się błądzenia)
Po angielsku nazywają się Self Avoiding Walks, w skrócie SAW. Niech Zd będzie d-wymiarową kratą całkowitoliczbową.
Mówimy, że ciąg s=(0=s0,s1,…,sk) punktów kraty jest SAW-em jeśli
-
każde dwa kolejne punkty si-1 i si sąsiadują ze sobą, czyli różnią się
o ±1 na dokładnie jednej współrzędnej,
-
żadne dwa punkty nie zajmują tego samego miejsca, czyli si≠sj dla i≠j.
Zbiór wszystkich SAW-ów o k ogniwach w Zd oznaczymy SAWkd, a
dla d i k ustalonych w skrócie SAW. Przykład s∈SAW152 widać na rysunku.
Natychmiast nasuwa się bardzo proste pytanie:
-
Jak policzyć SAW-y, czyli obliczyć L=Lk,d=SAWkd?
Zainteresujmy się teraz ,,losowo wybranym SAW-em”. Rozumiemy przez to zmienną losową S
o rozkładzie jednostajnym w zbiorze SAWkd, czyli taką, że PS=s=1/Lk,d dla każdego s∈SAWkd. W skrócie, S∼USAW.
Niech δsk oznacza odległość euklidesową końca SAW-a, czyli punktu sk, od początku, czyli punktu 0. Na przykład dla lańcuszka widocznego na rysunku mamy δs15=5.
Można zadać sobie pytanie, jaka jest średni kwadrat takiej odległości, czyli
-
Jak obliczyć δ2¯=δd,k2¯=EδSk2,
przy założeniu, że S∼USAW?
Można zastosować prostą metodę MC, czyli eliminację. Niech WALKkd oznacza zbiór
wszystkich ,,błądzeń”, czyli ciągów s=(0=s0,s1,…,sk) niekonieczne spełniających
warunek ,,si≠sj dla i≠j”. Oczywiście WALKkd=2dk
i metoda generowania ,,losowego błądzenia” (z rozkładu UWALK) jest bardzo prosta: kolejno losujemy pojedyncze kroki, wybierając zawsze jedną z 2d możliwości.
Żeby otrzymać ,,losowy SAW”, stosujemy eliminację. Ten sposób pozwala w zasadzie estymować
δ2¯ (przez uśrednianie długości zaakceptowanych błądzeń) oraz
SAW/WALK (przez zanotowanie frakcji akceptowanych błądzeń).
Niestety, metoda jest bardzo nieefektywna, bo dla dużych k prawdopodobieństwo akceptacji szybko zbliża sie do zera.
Metoda ,,wzrostu” zaproponowana przez Rosenbluthów polega na losowaniu kolejnych kroków błądzenia spośród ,,dopuszczalnych punktów”, to znaczy punktów wcześniej nie odwiedzonych.
W każdym kroku, z wyjątkiem pierwszego mamy co najwyżej 2d-1 możliwości. W błądzeniu
widocznym na rysunku kolejne kroki wybieraliśmy spośród:
|
4,3,3,3,2,3,2,2,3,2,3,3,2,1,3,2 |
|
możliwych. Nasz SAW został zatem wylosowany z prawdopodobieństwem
|
14⋅13⋅13⋅13⋅12⋅13⋅12⋅12⋅13⋅12⋅13⋅13⋅12⋅11⋅13⋅12 |
|
Powiedzmy ogólniej, że przy budowaniu SAW-a s=(0=s0,s1,…,sk) mamy kolejno
możliwości (nie jest przy tym wykluczone, że w pewnym kroku nie mamy żadnej możliwości, ni=0).
Używając terminologii i oznaczeń związanych z losowaniem istotnym powiemy, że
jest gęstością instrumentalną dla s∈SAW, gęstość docelowa jest stała, równa
ps=1/Z, zatem funkcja podziału jest po prostu liczbą SAW-ów: Z=SAW.
Wagi przypisujemy zgodnie ze wzorem ws=n1⋅n2⋯nk (jeśli wygenerowanie
SAW-a się nie udało, ni=0 dla pewnego i, to waga jest zero).
Niech teraz S1,…,Sn będą niezależnymi błądzeniami losowanymi
metodą Rosenbluthów. Zgodnie z ogólnymi zasadami losowania istotnego,
|
∑wSiδSi∑wSijest estymatorem δ2¯, |
|
|
∑wSijest estymatorem SAW. |
|
Należy przy tym uwzględniać w tych wzorach błądzenia o wadze zero, czyli ,,nieudane SAW-y”.
Przykład 8.2 (Prawdopodobieństwo ruiny i wykładnicza zamiana miary)
Rozpatrzymy najprostszy model procesu opisującego straty i przychody w ubezpieczeniowej ,,teorii ryzyka”. Niech Y1,Y2,… będą zmiennymi losowymi oznaczającymi straty netto
(straty - przychody) towarzystwa ubezpieczeniowego w kolejnych okresach czasu. Założymy
(co jest dużym uproszczeniem), że te zmienne są niezależne i mają jednakowy rozkład o gęstości
py. Tak zwana ,,nadwyżka ubezpieczyciela” na koniec n-go roku jest równa
gdzie u jest rezerwą początkową.
Interesuje nas prawdopodobieństwo zdarzenia, polegającego na tym, że
u-Sn<0 dla pewnego n. Mówimy wtedy (znowu w dużym uproszczeniu) o ,,ruinie ubezpieczyciela”. Wygodnie jest przyjąć następujące oznaczenia i konwencje.
Zmienna losowa
|
R=minn:Sn>u jeśli takie n istnieje;∞ jeśli Sn⩽u dla wszystkich n |
|
oznacza czas oczekiwania na ruinę, przy czym jeśli ruina nigdy nie nastąpi to ten czas uznajemy za nieskończony. Przy takiej umowie, prawdopodobieństwo ruiny możemy zapisać jako ψ=PpR<∞.
Wskaźnik p przy symbolu wartości oczekiwanej przypomina, że chodzi tu o ,,oryginalny” proces,
dla którego Yi∼p.
Obliczenie ψ analitycznie jest możliwe tylko w bardzo specjalnych przykładach. Motody numeryczne istnieją, ale też nie są łatwe. Pokażemy sposób obliczania ψ metodą Monte Carlo, który stanowi jeden z najpiękniejszych, klasycznych, przykładów losowania istotnego.
Przyjmiemy bardzo rozsądne założenie, że EpYi<0. Funkcję tworzącą momenty, która odpowiada gęstości p określamy wzorem
|
Mpt=EpetYi=∫-∞∞etypydy. |
|
Założymy, że ta funkcja przyjmuje wartości skończone przynajmniej w pewnym otoczeniu zera
i istnieje takie r>0, że
Liczba r jest nazywana współczynnikiem dopasowania i odgrywa tu kluczową rolę.
Metoda wykładniczej zamiany miary jest specjalnym przypadkiem losowania istotnego.
Zeby określić instrumentalny rozkład prawdopodobieństwa, połóżmy
Z definicji współczynnika dopasowania wynika, że q jest gęstością prawdopodobieństwa, to znaczy
∫qydy=1.
Generuje się ciąg Y1,Y2,… jednakowo rozłożonych zmiennych losowych o gęstości q.
Dla utworzonego w ten sposób ,,instrumentalnego procesu” używać będziemy symboli Pq i
Eq. Zauważmy, że
|
EqYi=∫yqydy=∫yerypydy=ddr∫erypydy=Mp′r>0, |
|
ponieważ funkcja tworząca momenty Mp(⋅) jest wypukła, Mp′0<0
i Mp0=Mpr=1. Po zamianie miary, proces u-Sn na mocy Prawa Wielkich Liczb
zmierza prawie na pewno do minus nieskończoności, a zatem ruina następuje z prawdopodobieństwem jeden,
PqR<∞=1. Pokażemy, jak wyrazić prstwo ruiny dla oryginalnego procesu w
terminach procesu instrumentalnego. Niech
|
Rn=y1,…,yn:y1⩽u,…,y1+⋯+yn-1⩽u,y1+⋯+yn-1+yn>u, |
|
Innymi słowy, zdarzenie R=n zachodzi gdy Y1,…,Yn∈Rn.
Mamy zatem
|
Pp(R=n)=∫⋯∫Rnp(y1)⋯p(yn)dy1⋯dyn=∫⋯∫Rne-ry1q(y1)⋯e-rynq(yn)dy1⋯dyn=∫⋯∫Rne-ry1+⋯+ynq(y1)⋯q(yn)dy1⋯dyn=EqerSnI(R=n). |
|
Weźmy sumę powyższych równości dla n=1,2,… i skorzystajmy z faktu, że ∑n=1∞PqR=n=1. Dochodzimy do wzoru
|
PpR<∞=Eqexp-rSR=e-ruEqexp-rSR-u. |
| (8.3) |
Ten fakt jest podstawą algorytmu Monte Carlo:
| ψ⌃:=0; [ ψ⌃ będzie estymatorem prawdopodobieństwa ruiny ] |
|
| for m:=1 to k do |
| begin |
| n:=0; S:=0; |
| repeat |
| Gen Y∼q; S:=S+Y; |
| until S>u; |
| Z:=exp-rS-u; ψ⌃:=ψ⌃+Z |
| end |
| ψ⌃:=e-ruψ⌃/k |
Algorytm jest prosty i efektywny. Trochę to zadziwiające, że w celu obliczenia prawdopodobieństwa
ruiny generuje się proces dla którego ruina jest pewna. Po chwili zastanowienia można jednak zauważyć,
że wykładnicza zamiana miary realizuje podstawową ideę losowania istotnego: rozkład instrumentalny
,,naśladuje” proces docelowy ograniczony do zdarzenia R<∞.
Ciekawe, że wykładnicza zamiana miary nie tylko jest techniką Monte Carlo, ale jest też
techniką dowodzenia twierdzeń! Aby się o tym przekonać, zauważmy, że ,,po drodze”
udowodniliśmy nierówność ψ⩽e-ru (wynika to z podstawowego wzoru
(8.3) gdyż exp-rSR-u⩽1).
Jest to sławna nierówność Lundberga i wcale nie jest ona oczywista.