Zagadnienia
3. Analiza Składowych Głównych
3.1. Analiza danych wielowymiarowych
Oznaczenia:
-
-
Przez
-
-
Oznaczeń
Stwierdzenie 3.1
Proste własności wprowadzonych pojęć:
-
-
.
-
Macierz kowariancji jest równa:
-
Macierz kowariancji ma następującą własność:
-
Ponadto, macierz
symetryczność wynika z symetryczności kowariancji dwóch zmiennych losowych;
nieujemna określoność wynika z nieujemności wariancji dla zmiennej losowej. Dla
-
Jeżeli
3.2. Redukcja Wymiaru danych
Wygodną postacią macierzy wariancji
Problem 3.1
Jak przekształcić wektor losowy
Twierdzenie 3.1
Rozkład spektralny macierzy symetrycznej
-
ortonormalna (czyli
-
diagonalna macierz
Ponieważ macierz kowariancji
Ponieważ macierz
3.2.1. Analiza składowych głównych – wersja populacyjna
Definicja 3.1
Mamy wektor losowy
Składowymi głównymi (principal components) nazywamy elementy wektora
Kierunkami głównymi (rotations) nazywamy kolumny macierzy
Stwierdzenie 3.2
Własności składowych głównych:
-
wsółrzędne wektora
-
wariancje poszczególnych
-
-
Stwierdzenie 3.3
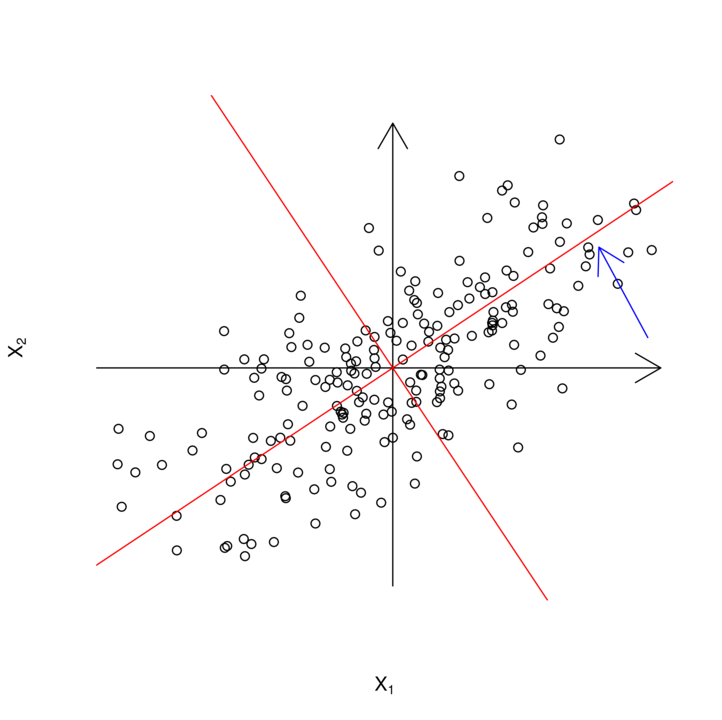
Kierunki główne to unormowane wektory, w kierunku których obserwujemy największą wariancję danych, będące wzajemnie do siebie prostopadłe:
-
jeżeli
-
jeżeli
-
Zapiszmy
Zauważmy, że:
z własności wektorów własnych macierzy,
Jeżeli przyjmiemy
-
Ponieważ
Analogicznie,
Stwierdzenie 3.4
Ponieważ
Definicja 3.2
Całkowity rozrzut danych dla wektora losowego
Uwaga 3.1
Ślady macierzy
.
Istotnym parametrem diagnostycznym przy rozważaniu analizy składowych głównych jest:
czyli część całkowitego rozrzutu danych wyjaśniona przez
3.2.2. Analiza składowych głównych – wersja próbkowa
Podejście próbkowe do analizy danych różni się od populacyjnego tym, że w podejściu populacyjnym do analizy brana jest zmienna losowa, a w podejściu próbkowym jej realizacje. Dlatego teraz zamiast wektora zmiennych losowych
Do analizy potrzebna będzie macierz kowariancji próbkowej. Zdefiniujmy scentrowaną macierz
gdzie
Zauważmy, że macierz kowariancji próbkowej możemy wyrazić za pomocą macierzy:
która jest nieobciążonym estymatorem macierzy kowariancji:
Macierz
Wniosek 3.1
Składowe główne dla problemu próbkowego równe są wektorom
3.2.3. Rozkład na wartości szczególne (Singular Value Decomposition)
Rozkład SVD posłuży nam do tańszej obliczeniowo konstrukcji składowych głównych w wersji próbkowej.
Twierdzenie 3.2
Rozkład na wartości szczególne
Dla dowolnej macierzy
gdzie
Zauważmy, że macierz
Zatem, korzystając z rozkładu spektralnego dla
| (3.1) |
gdzie założymy, że
Zauważmy, że
Zdefiniujmy
skąd otrzymujemy:
Uzupełniamy dowolnie
ponieważ ze wzoru (3.1) wynika, że
Z równości
Stwierdzenie 3.5
Wróćmy do analizy składowych głównych. Do scentrowanej macierzy danych
wtedy:
Wniosek 3.2
Zauważmy, że:
-
Składowe główne w wersji próbkowej przy użyciu rozkładu SVD:
Obliczanie składowych głównych z tego wzoru jest tańsze obliczeniowo.
-
Widać związek pomiędzy rozkładem SVD dla
-
Podobnie jest dla
3.2.4. Kolejna zaleta analizy składowych głównych
Wróćmy do analizy składowych głównych w wersji populacyjnej.
Stwierdzenie 3.6
Przy założeniu, że wektor losowy
| wśród wszystkich układów ortonormalnych |
|
Czyli w sensie minimalizacji błędu średniokwadratowego najlepszym
Czyli maksymalizujemy po
Przyjrzyjmy się współczynnikom przy
Czyli otrzymujemy:
Jeśli podstawimy
3.3. Przykłady w programie R
Analiza składowych głównych:
-
dla danych Pima: http://www.mimuw.edu.pl/~pokar/StatystykaII/EKSPLORACJA/pca.R
-
dla danych Iris i Kraby: http://www.mimuw.edu.pl/~pokar/StatystykaII/EKSPLORACJA/rzutDanych.R


