5.1. Test χ2 Pearsona
Dana jest zmienna losowa jakościowa o rozkładzie wielomianowym o wartościach 1,…,k oraz prawdopodobieństwach p1,…,pk. Podczas doświadczenia obserwujemy liczności, jakie przyjmowała zmienna w n niezależnych próbach: n=n^1+n^2+…+n^k. Teoretyczne liczności będą wartościami oczekiwanymi dla rozkładu wielomianowego: n1=np1,…,nk=npk. Satystyka wyraża się wzorem:
|
Q=∑i=1kn^i-ni2nid→χ2k-1; |
|
przy spełnionej hipotezie zerowej H0: zmienna losowa pochodzi z rozkładu wielomianowego o parametrach p1,…pk, zbiega ona według rozkładu do rozkładu χ2 o k-1 stopniach swobody.
Omawianą statystykę można zapisać także jako:
|
Q=n∑i=1kp^i-pi2pi=n∑i=1kp^i-pipi2pi, |
|
gdzie p^i=n^in to zaobserwowane prawdopodobieństwa (będące stymatorami największej wiarygodności parametrów pi dla rozkładu wielomianowego).
5.2. Test niezależności
Będziemy rozpatrywać dwie zmienne losowe o rozkładzie dyskretnym:
których rozkład łączny jest rozkładem wielomianowym o nieznanych parametrach pij, i=1,…,k, j=1,…,l. Znane są jedynie zaobserwowane liczności dla każdej pary i,j w postaci macierzy kontyngencji.
Definicja 5.1
Macierz kontyngencji to macierz N o wymiarach k×l zawierająca zaobserwowane liczności nij, ∑i=1k∑j=1lnij=n, dla każdej z par wartości zmiennych losowych X,Y:
|
X∖Y1…l1n11…n1l…………knk1…nkl |
|
Hipotezę, którą będziemy testować to:
|
H0: zmienne losowe X i Y są niezależne. |
|
W tym celu policzymy odległość rozkładu zaobserwowanego od teoretycznego rozumianego jako iloczyn rozkładów brzegowych. Macierz zaobserwowanych prawdopodobieństw możemy zapisać jako:
gdzie N to macierz kontyngencji, a n to suma wszystkich elementów tej macierzy.
Statystyka testowa wyraża się wzorem:
|
n∑i=1k∑j=1lp^ij-p^i.p^.j2p^i.p^.jd→χ2k-1l-1, |
|
gdzie p^i.=∑j=1lp^ij i p^.j=∑i=1kp^ij to zaobserwowane rozkłady brzegowe dla X i Y.
5.3. Analiza odpowedniości (correspondence analysis)
Tak jak w poprzednim podrozdziale, dane mamy dwie zmienne losowe X i Y o rozkładzie dyskretnym. Analiza odpowiedniości to metoda prezentacji danych w przestrzeni o niewielkim wymiarze (zwykle równym 2, wtedy prezentację można przedstawić na płaszczyźnie), ilustrująca zależności pomiędzy danymi cechami X i Y.
Przykład 5.1
Rozpatrzmy następujący przykład: dla każdej osoby obserwujemy kolor oczu i włosów. Zmienna losowa X będzie oznaczać jeden z czterech kolorów oczu: brown, blue, hazel, green. Zmienna losowa Y będzie oznaczać jeden z czterech kolorów włosów: black, brown, red, blond. Tablica kontyngencji dla tego przykładu:
|
eyes∖hairblackbrownredblondbrown68119267blue20841794hazel15541410green5291416 |
|
Analiza odpowiedniości pozwoli nam na przedstawienie graficzne zależności pomiędzy kolorami włosów i oczu. Na przykład, będziemy mogli zobaczyć, czy osoby o niebieskim kolorze oczu mają najczęsciej włosy koloru blond.
Do analizy korespondencji potrzebna nam będzie macierz rezyduów Pearsona, której konstrukcję omówimy przy pomocy komend programu R:
N=table(cbind(X,Y)) # macierz kontyngencji, gdzie X i Y to faktory
P=N/sum(N) # macierz zaobserwowanych prawdopodobieństw
Pi=apply(P,1,sum) # rozkład brzegowy dla X
Pj=apply(P,2,sum) # rozkład brzegowy dla Y
PP=Pi%*%t(Pj)
RP=sqrt(sum(N))*(P-PP)/sqrt(PP) # macierz rezyduów Pearsona
Uwaga 5.1
Zauważmy, że sum(RP^2) to statystyka testowa dla testu niezależności.
Przykład 5.1
Sama postać macierzy RP może nam wiele powiedzieć o zależności poszczególnych cech. Macierz rezyduów Pearsona dla przykładu kolory oczu i włosów znajduje się w tabeli 5.1.
|
BLACK |
BROWN |
RED |
BLOND |
| Brown |
4.40 |
1.23 |
-0.07 |
-5.85 |
| Blue |
-3.07 |
-1.95 |
-1.73 |
7.05 |
| Hazel |
-0.48 |
1.35 |
0.85 |
-2.23 |
| Green |
-1.95 |
-0.35 |
2.28 |
0.61 |
Tabela 5.1.
Macierz rezyduów Pearsona dla przykładu kolory oczu i włosów.
Największe dodatnie wartości, a więc największą dodatnią zależność pomiędzy cechami mamy dla par (brown,black) i (blue,blond). Największą ujemne wartości, a więc największą ujemną zależność obserwujemy dla par (blue,black) i (brown,blond).
Celem analizy odpowiedniości jest przedstawienie cech X i Y na płaszczyźnie, żeby widoczne były zależności między nimi. W tym celu zmniejszymy wymiar RP do 2, używając do tego analizy składowych głównych. Wiemy, że takie przybliżenie jest najlepsze w sensie błędu średniokwadratowego i opisuje możliwie najwięcej zmienności danych.
|
RP=d1u1v1T+d2u2v2T+…+dlulvlT≈ |
|
|
≈d1u1d1v1T+d2u2d2v2T. |
|
Cechy X i Y przedstawiamy jako punkty:
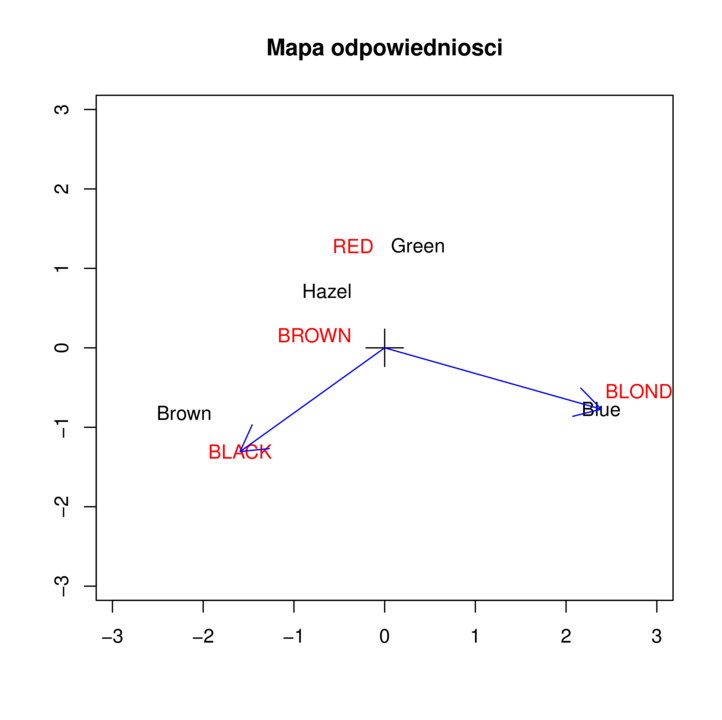
Pamiętamy z rozkładu SVD, że RPV=UD, UTRP=DVT , U rozpina przestrzeń kolumn macierzy RP, a V przestrzeń wierszy. Scentrowane punkty (od kolumn macierzy X~ i Y~ odejmujemy średnie w kolumnach tak żeby środek danych był w (0,0)) nanosimy na wykres (rysunek 5.1).
Przykład 5.1
Dla interpretacji mapy odpowiedniości, potraktujmy wiersze macierzy X~ oraz Y~ jako współrzędne wektorów, zaczepionych w punkcie (0,0). Wiersze macierzy X~ odpowiadają kolorom oczu, wiersze macierzy Y~ kolorom włosów. Na rysunku zaznaczone zostały dla przykładu wektory odpowiadające cechom blue oraz black. Zauważmy, że iloczyn skalarny dwóch wektorów, i-tego z macierzy X~ i j-tego z macierzy Y~ równy jest przybliżeniu macierzy rezyduów Pearsona. Oznaczmy:
|
a=X~[i,]=(d1u1[i],d2u2[i]); |
|
|
b=Y~[i,]=(d1v1[i],d2v2[i]); |
|
gdzie θ oznacza kąt pomiędzy wektorami. Interpretacja dla wektorów blue i black może być następująca: ponieważ długości obu wektorów są duże oraz cosϑ jest ujemne o wartości bezwzględnej w przybliżeniu 12, zależność pomiędzy cechami jest silnie ujemna. Na tej samej zasadzie możemy zaobserwować silną zależność pomiędzy włosami blond i oczami blue oraz włosami black i oczami brown.