Zagadnienia
6. Klasteryzacja
Klasteryzacja jest, podobnie jak analiza składowych głównych, metodą redukcji wymiaru danych. W tym przypadku jednak redukcja będzie się odbywać w pionie a zamiast odcinania części danych, będziemy je grupować. Nowym wymiarem danych będzie liczba grup. Dla macierzy
parami rozłącznych o licznościach odpowiednio
6.1. Klasteryzacja K
Klasteryzacji
Macierz wariancji całkowitej:
nie zależy od podziału
Zmienność całkowita to ślad macierzy T:
Macierz wariancji wewnątrzgrupowej:
zależy od podziału
Zmienność wewnątrzgrupowa to ślad macierzy
Macierz wariancji międzygrupowej:
zależy od podziału
Zmienność międzygrupowa to ślad macierzy
Stwierdzenie 6.1
Wniosek 6.1
Czyli
Ideą klasteryzacji
Idea zachłannego algorytmu
Algorytm K
| Wielokrotnie powtarzamy przy różnym podziale startowym |
| repeat |
| for ( |
| |
| for ( |
| |
| until warunek stopu |
Przykładowy wynik algorytmu klasteryzacji
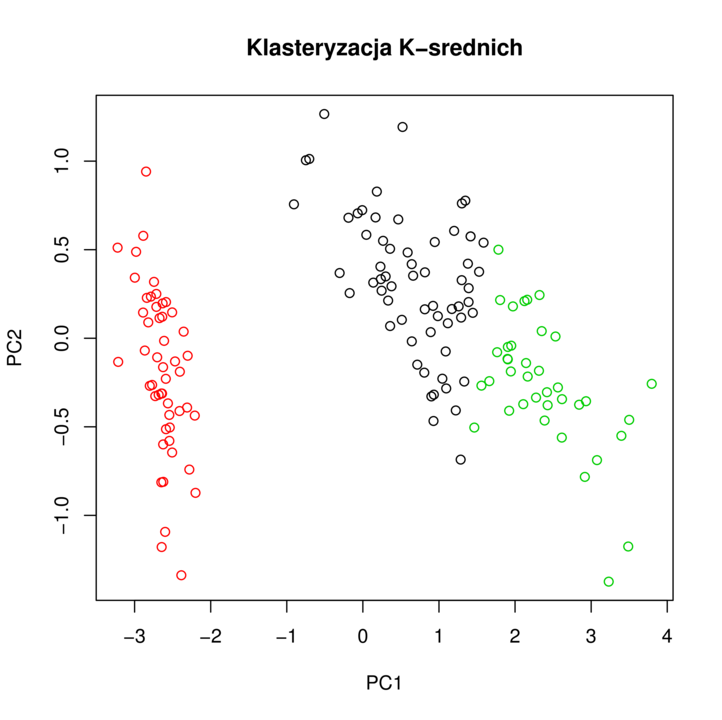
6.2. Klasteryzacja K
Klasteryzacja
Algorytm K
| Wielokrotnie powtarzamy przy różnym podziale startowym |
| repeat |
| for ( |
| |
| for ( |
| |
| until warunek stopu |
6.3. Klasteryzacja hierarchiczna
Używając klasteryzacji hierarchicznej nie zakładamy z góry ilości klastrów, na jakie chcemy podzielić dane. Wychodzimy od sytuacji, gdy mamy
W klasteryzacji hierarchicznej możemy używać różnych metod aglomeracji danych.
Dla macierzy odległości
możemy zdefiniować jako:
-
Single linkage
-
Average linkage
gdzie
-
Complete linkage
Ideę algorytmu klasteryzacji hierarchicznej możemy zapisać jako:
Algorytm klasteryzacji hierarchicznej
| |
| for (l in 1:(n-1)) |
| połącz najbliższe dwa klastry: |
| |
| klastry |
| odnów macierz odległości |
Definicja 6.1
Dendrogram jest metodą ilustracji wyników klasteryzacji hierarchicznej. Możemy obserwować od dołu dendrogramu (rysunek 6.2) jak kolejne klastry się łączą i dla jakiej wysokości (odległości klastrów) to zachodzi.
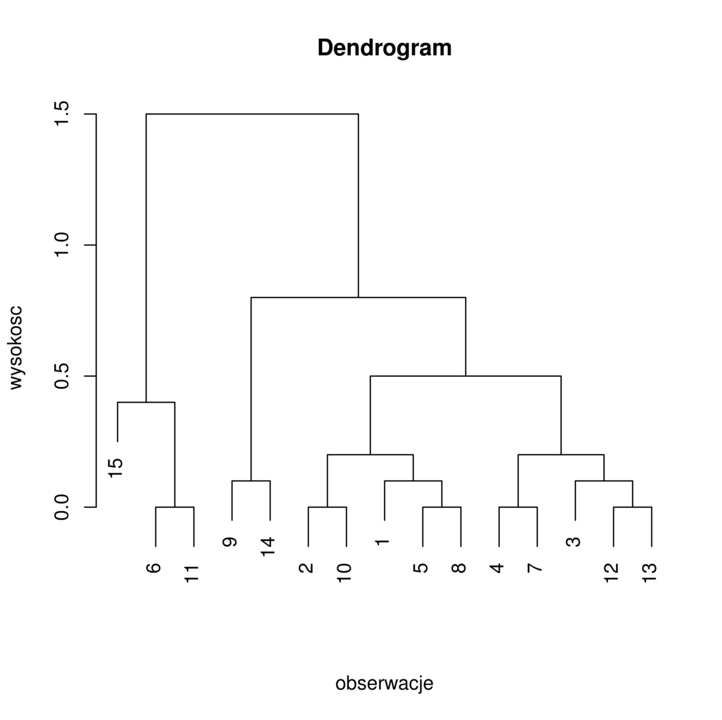
Definicja 6.2
Oznaczmy
Separowalność dla klasteryzacji hierarchicznej definiujemy jako:
Z definicji separowalności możemy wywnioskować następujące własności:
-
separowalność przyjmuje wartości z przedziału
-
jest niemalejącą funkcją liczby klastrów.
Przykładowy wykres separowalności znajduje się na rysunku 6.3. Na podstawie tego wykresu podejmuje się decyzję dotyczącą optymalnej ilości klastrów. Szukamy takiego
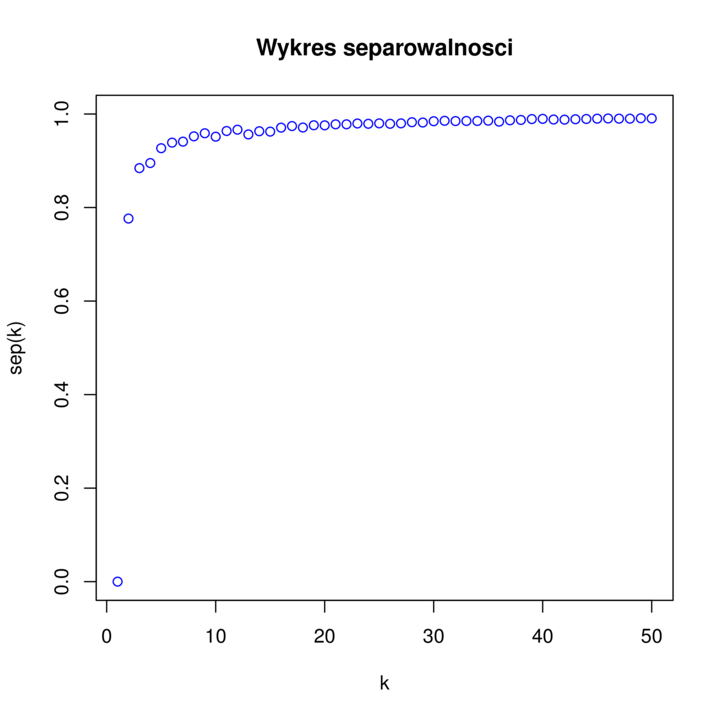
Definicja 6.3
Można zdefiniować także separowalność dla klasteryzacji
Ponieważ wiemy, że:
możemy zdefiniować separowalność jako:
Stwierdzenie 6.2
Separowalność dla klasteryzacji
Jako praca domowa.
∎6.4. Przykłady w programie R
Klasteryzacja:
-
k-średnich i hierarchiczna na danych Kraby, kobiety Pima i Irysy: http://www.mimuw.edu.pl/~pokar/StatystykaII/EKSPLORACJA/ileKlastrow.R
-
wybór liczby klastrów na podstawie wykresu separowalności i sylwetki dla algorytmów k-średnich i k-medoidów: http://www.mimuw.edu.pl/~pokar/StatystykaII/EKSPLORACJA/sep_syl.r
-
k-średnich i hierarchiczna zobrazowane przy pomocy analizy składowych głównych: http://www.mimuw.edu.pl/~pokar/StatystykaII/EKSPLORACJA/pca.R
-
k-średnich i hierarchiczna oraz PCA i skalowanie wielowymiarowe dla danych Iris i Kraby: http://www.mimuw.edu.pl/~pokar/StatystykaII/EKSPLORACJA/rzutDanych.R


