Zagadnienia
- Podstawowe zagadnienia
-
12.1 Raporty macierzowe
- Data Mart
- Narzędzia do zapytań i analiz
- Inne operacje
- Modele danych i operatory
- Wielowymiarowy model danych
- Wymiary
- Baza danych
- Operacje na danych
- Podejścia do budowy bazy OLAP
- Schemat gwiazdy
- Przykład schematu gwiazdy
- Atrybuty wymiarów i atrybuty zależne
- Przykład: atrybut zależny
- Techniki ROLAP
- Typowe zapytanie OLAP
- Przykład zapytania OLAP
- Przykład: SQL
- Perspektywy zmaterializowane
- Przykład: Perspektywa zmaterializowana
- Aspekty materializacji
- MOLAP i kostki danych
- Marginesy
- Przykład: marginesy
- Struktura kostki
- Rozwijanie (drill-down)
- Zwijanie (roll-up)
- Roll-Up i Drill-Down: przykłady
- Zmaterializowane perspektywy kostek danych
- Przykład
- Indeksy
- Użycie list odwróconych
- Użycie bitmap
12. Analityczne bazy danych (,,kostki danych”)
-
Inaczej On-Line Analytical Processing : OLAP
-
Rosnące znaczenie: 8 mld. dol. w 1998 roku.
-
Od komputerów biurkowych po olbrzymie konfiguracje:
-
Wiele modnych haseł, zaklęć
-
zwijanie i rozwijanie, drążenie, MOLAP, obracanie.
-
Podstawowe zagadnienia
-
Co to jest analityczna baza danych?
-
Modele i operacje
-
Implementacja analitycznej bazy danych
-
Kierunki rozwojowe
12.1. Raporty macierzowe
Pierwszym wsparciem dla analizy danych były raporty macierzowe. Zwykle były używane przez specjalistów od finansów lub zarządzania.
W systemie sprzedaży będzie na przykład potrzebny raport o klientach i ich wzorcach kupowania z podziałem na powiaty. Zamiast analizować wzorce dla każdego towaru, dzielimy towary na kategorie.
Raporty macierzowe przypominają arkusz kalkulacyjny. W kolumnach raportu będą wypisane u góry poszczególne kategorie towarów, w wierszach powiaty, a każda z komórek będzie pokazywać liczbę pozycji sprzedanych w tej kategorii.
Data Mart
-
Mała hurtownia
-
Obejmuje tylko część tematyki organizacji, np.
-
marketing: klienci, towary, sprzedaż
-
-
Model dostosowany do potrzeb działu.
-
Najczęściej informacja wstępnie zagregowana
-
Eliminacja zbędnych detali
-
Wybieramy pewien krytyczny poziom szczegółowości.
-
Narzędzia do zapytań i analiz
-
Budowanie zapytań
-
Generatory raportów
-
porównania: wzrost, spadek
-
trendy,
-
grafy
-
-
Arkusze kalkulacyjne
-
Interfejs WWW
-
Data Mining
Inne operacje
-
Funkcje po czasie
-
np. średnie po różnych okresach
-
-
Atrybuty obliczane
-
np. marża = sprzedaż * stopa
-
-
Zapytania tekstowe, np.
-
znajdź dokumenty zawierające słowa
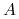 i
i 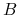
-
uporządkuj dokumenty według częstości występowania słów
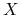 ,
,
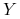 i
i 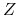
-
Modele danych i operatory
-
Modele danych
-
relacja
-
gwiazda i płatek śniegu
-
kostka: rozwinięcie idei arkusza kalkulacyjnego (tablice wielowymiarowe)
-
-
Operatory
-
slice & dice
-
roll-up, drill down
-
pivoting
-
inne
-
Wielowymiarowy model danych
-
Najczęściej używa się wielowymiarowych bazy danych z uwagi na analityczny model danych o postaci kostki wielowymiarowej obejmujący:
-
fakty zwane też miarami (measures), np. liczba sprzedanych samochodów;
-
wymiary (dimensions), np. miesiące, regiony sprzedaży.
-
Wymiary
-
Wymiary tworzą zazwyczaj hierarchie, np. dla czasu będzie to rok-kwartał-miesiąc-dzień.
-
Dzięki temu możliwa jest interakcyjna zmiana poziomu szczegółowości (ziarnistości) oglądanej informacji.
-
W bardziej złożonych przypadkach hierarchie mogą rozgałęziać się, np. podział na tygodnie jest niezgodny z podziałem na miesiące.
Baza danych
-
Źródłem danych jest najczęściej hurtownia danych (rzeczywista lub wirtualna).
-
Bezpośrednie trzymanie w bazie danych informacji o faktach dla wszystkich poziomów szczegółowości może być kosztowne
-
Tylko dla najczęściej używanych poziomów hierarchii.
-
Pozostałe są wyliczane na bieżąco w razie potrzeby.
-
-
Przy agregowaniu miar warto pamiętać o różnych regułach liczenia, np.
-
Wielkość sprzedaży jest na ogół sumowana
-
Temperatura lub cena będą raczej uśredniane.
-
-
W analitycznej bazie danych trzymane są w zasadzie dane zagregowane.
-
Aby obejrzeć dane szczegółowe (drill-through) konieczne jest sięgnięcie do hurtowni danych lub bazy operacyjnej.
-
Ponieważ jest to kosztowne czasowo, taka potrzeba nie powinna występować zbyt często.
Operacje na danych
-
Przecinanie i rzutowanie (slice and dice)
-
Zmiana poziomu szczegółowości: drążenie lub rozwijanie (drill-down) i zwijanie (roll-up),
-
obracanie (pivot): zmienia położenie wymiaru na ,,wykresie”.
Podejścia do budowy bazy OLAP
-
ROLAP = ,,relacyjny OLAP”: dopasowujemy relacyjny DBMS do schematu gwiazdy.
-
MOLAP = ,,wielowymiarowy OLAP”: używamy specjalizowanego DBMS z modelem w rodzaju ,,kostka danych”.
Schemat gwiazdy
-
Schemat gwiazdy to typowy sposób organizacji danych dla relacyjnej bazy danych dla OLAP.
-
Obejmuje:
-
Tabelę faktów: olbrzymi zbiór faktów takich jak informacje o sprzedaży.
-
Tabele wymiarów: mniejsze, statyczne informacje o obiektach, których dotyczą fakty.
-
-
Uogólnienie: model płatka śniegu.
-
Hierarchie tabel dla poszczególnych wymiarów: normalizacja wymiarów.
-
Przykład schematu gwiazdy
-
Chcemy gromadzić w hurtowni danych informacje o sprzedaży piwa: bar, marka piwa, piwosz, który je zakupił, dzień, godzina oraz cena.
-
Tabelą faktów będzie relacja:
Sprzedaż(bar,piwo,piwosz,dzień,godzina,cena)
-
Tabele wymiarów zawierają informacje o barach, piwach i piwoszach:
Bary(bar,adres,licencja) Piwa(piwo,prod) Piwosze(piwosz,adres,tel)
Atrybuty wymiarów i atrybuty zależne
-
Dwa rodzaje atrybutów w tabeli faktów:
-
Atrybuty wymiarów: klucze tabel wymiarów.
-
Atrybuty zależne: wartości wyznaczone przez atrybuty wymiarów krotki.
-
Przykład: atrybut zależny
-
cena jest atrybutem zależnym w przykładowej relacji Sprzedaż.
-
Jest ona wyznaczona przez kombinację atrybutów wymiarów: bar, piwo, piwosz i czas (kombinacja atrybutów daty i godziny).
Techniki ROLAP
-
Indeksy bitmapowe: dla każdej wartości klucza indeksowego w tabeli wymiaru (np. dla każdego piwa w tabeli Piwa) tworzymy wektor bitowy podający, które krotki w tabeli faktów zawierają tę wartość.
-
Perspektywy zmaterializowane: w hurtowni przechowujemy gotowe odpowiedzi na kilka użytecznych zapytań (perspektywy).
Typowe zapytanie OLAP
-
Zapytanie OLAP często zaczyna się od ,,star join”: złączenia naturalnego tabeli faktów z wszystkimi lub większością tabel wymiarów.
-
Przykład:
SELECT * FROM Sprzedaż,Bary,Piwa,Piwosze WHERE Sprzedaż.bar = Piwa.bar AND Sprzedaż.piwo = Piwa.piwo AND Sprzedaż.piwosz = Piwosze.piwosz;
-
Rozpoczyna się złączeniem gwiaździstym.
-
Wybiera interesujące krotki używając danych z tabel wymiarów.
-
Grupuje po jednym lub więcej wymiarach.
-
Agreguje niektóre atrybuty wyniku.
Przykład zapytania OLAP
-
Dla każdego baru w Poznaniu podaj całkowitą sprzedaż każdego piwa wytwarzanego przez browar Anheuser-Busch.
-
Filtr: adres = “Poznań” i prod = “Anheuser-Busch”.
-
Grupowanie: po bar i piwo.
-
Agregacja: Suma po cena.
Przykład: SQL
SELECT bar, piwo, SUM(cena)
FROM Sprzedaż NATURAL JOIN Bary
NATURAL JOIN Piwa
WHERE addr = 'Poznań'
AND prod = 'Anheuser-Busch'
GROUP BY bar, piwo;
Perspektywy zmaterializowane
-
Bezpośrednie wykonanie naszego zapytania dla tabeli Sprzedaż i tabel wymiarów może trwać za długo.
-
Jeśli utworzymy perspektywę zmaterializowaną zawierającą odpowiednie informacje, będziemy mogli znacznie szybciej podać odpowiedź.
Przykład: Perspektywa zmaterializowana
-
Jaka perspektywa mogłaby nam pomóc?
-
Podstawowe wymagania:
-
Musi łączyć co najmniej Sprzedaż, Bary i Piwa.
-
Musi grupować co najmniej po bar i piwo.
-
Nie musi wybierać barów w Poznaniu ani piw Anheuser-Busch.
-
Nie musi wycinać kolumn adres ani prod.
-
-
A oto przydatna perspektywa:
CREATE VIEW BaPiS(bar, adres, piwo, prod, sprzedaż) AS SELECT bar, adres, piwo, prod, SUM(cena) sprzedaż FROM Sprzedaż NATURAL JOIN Bary NATURAL JOIN Piwa GROUP BY bar, adres, piwo, prod; -
Ponieważ bar
 adres oraz piwo
prod, jest to pozorne grupowanie, konieczne ponieważ
adres i prod występują we frazie SELECT.
adres oraz piwo
prod, jest to pozorne grupowanie, konieczne ponieważ
adres i prod występują we frazie SELECT.
-
Przeformułowane zapytanie z użyciem zmaterializowanej perspektwy BaPiS:
SELECT bar, piwo, sprzedaż FROM BaPiS WHERE adres = 'Poznań' AND prod = 'Anheuser-Busch';
Aspekty materializacji
-
Typ i częstość zapytań
-
Czas odpowiedzi na zapytania
-
Koszt pamięci
-
Koszt aktualizacji
MOLAP i kostki danych
-
Klucze tabel wymiarów stają się wymiarami hiperkostki.
-
Przykład: dla danych z tabeli Sprzedaż mamy cztery wymiary: bar, piwo, piwosz i czas.
-
-
Atrybuty zależne (np. cena) występują w punktach (kratkach) kostki.
Marginesy
-
Kostka często zawiera również agregacje (zwykle SUM) wzdłuż hiper-krawędzi kostki.
-
Marginesy obejmują agregacje jednowymiarowe, dwuwymiarowe, …
Przykład: marginesy
-
Nasza 4-wymiarowa kostka Sprzedaż obejmuje sumy cena dla każdego baru, każdego piwa, każdego piwosza i każdej jednostki czasu (zapewne dni).
-
Zawiera też sumy cena dla wszystkich par bar-piwo, trójek bar-piwosz-dzień, …
Struktura kostki
-
Każdy wymiar należy traktować jako mający dodatkową wartość *.
-
Punkt wewnętrzny z jedną lub więcej współrzędną * zawiera agregaty po wymiarach z *.
-
Przykład: Sprzedaż('Pod Żaglem', 'Bud', *, *) zawiera sumę piwa Bud wypitego w ,,Pod Żaglem” przez wszystkich piwoszy w dowolnym czasie.
Rozwijanie (drill-down)
-
Drill-down = ,,deagregacja” = rozbija agregację na jej składniki.
-
Przykład: po stwierdzeniu, że ,,Pod Żaglem” sprzedaje się bardzo mało piw Okocim, rozbić tę sprzedaż na poszczególne gatunki piw Okocim.
Zwijanie (roll-up)
-
Roll-up = agregacja po jednym lub więcej wymiarach.
-
Przykład: mając tabelę podającą jak wiele piwa Okocim wypija każdy piwosz w każdym barze, zwinąć ją do tabeli podającej ogólną ilość piwa Okocim wypijanego przez każdego z piwoszy.
Roll-Up i Drill-Down: przykłady
-
Anheuser-Busch dla piwosz/bar
Jim Bob Mary Joe's Bar 45 33 30 Nut-House 50 36 42 Blue Chalk 38 31 40 -
Zwinięcie po Bary
-
A-B / piwosz
Jim Mary Bob 133 100 112
-
Rozwinięcie po Piwa
-
Piwa A-B / piwosz
Jim Bob Mary Bud 40 29 40 M'lob 45 31 37 Bud Light 48 40 35
Zmaterializowane perspektywy kostek danych
-
Dla kostek danych warto robić perspektywy zmaterializowane agregujące po jednym lub więcej wymiarach.
-
Wymiary nie powinny być całkowicie agregowane — można ewentualnie grupować po atrybucie z tabeli wymiaru.
Przykład
-
Zmaterializowana perspektywa dla naszej kostki Sprzedaż mogłaby:
-
Agregować całkowicie po piwosz.
-
Nie agregować wcale po piwo.
-
Agregować po czasie według tydzień.
-
Agregować po miasto dla barów.
-
Indeksy
-
Tradycyjne techniki
-
B-drzewa, tablice haszujące, R-drzewa, gridy, …
-
-
Specyficzne
-
listy odwrócone
-
indeksy bitmapowe
-
indeksy złączeniowe
-
indeksy tekstowe
-
Użycie list odwróconych
-
Zapytanie:
-
Podaj osoby dla których wiek = 20 i imię = ,,Fred”
-
-
Lista dla wiek = 20: r4, r18, r34, r35
-
Lista dla imię = ,,Fred”: r18, r52
-
Odpowiedzią jest przecięcie: r18
Użycie bitmap
-
Zapytanie:
-
Podaj osoby dla których wiek = 20 i imię = ,,Fred”
-
-
Mapa dla wiek = 20: 1101100000
-
Mapa dla imię = ,,Fred”: 0100000001
-
Odpowiedzią jest przecięcie: 010000000000
-
Dobre jeśli mało wartości danych.
-
Wektory bitowe można kompresować.


