14. Semistrukturalne bazy danych – wprowadzenie
Rozpowszechnienie Internetu i jego zasobów informacyjnych, dostępnych w postaci stron WWW, pociągnęło naturalnie za sobą myśl o wykorzystaniu ich jako baz danych. Stwarza to jednak szereg problemów.
Dane przechowywane w postaci stron HTML czy plików XML nie posiadają tak regularnej struktury, jak relacyjne bazy danych. Do określenia takich źródeł danych zaczęto używać terminu dane semistrukturalne.
14.1. Dane semistrukturalne
Dane semistrukturalne to nowy model danych oparty na drzewach. Reprezentacja danych jest bardziej elestyczna niż w relacyjnych bazach danych — jako podstawę matematyczną modelu wybrano graf skierowany.
Schemat bazy jest często wpisany bezpośrednio w dane, można to określić jako dane ,,samo-opisujące się”. Taka struktura bardzo dobrze pasuje do plików w XML, popularnej notacji do przechowywania informacji opartej na SGML.
Model demistrukturalny przydaje się też przy integracji informacji ze źródeł o nieco różnej strukturze, zwłaszcza przy budowie hurtowni wirtualnych.
Przykład takiej (niewielkiej) bazy danych możemy obejrzeć poniżej
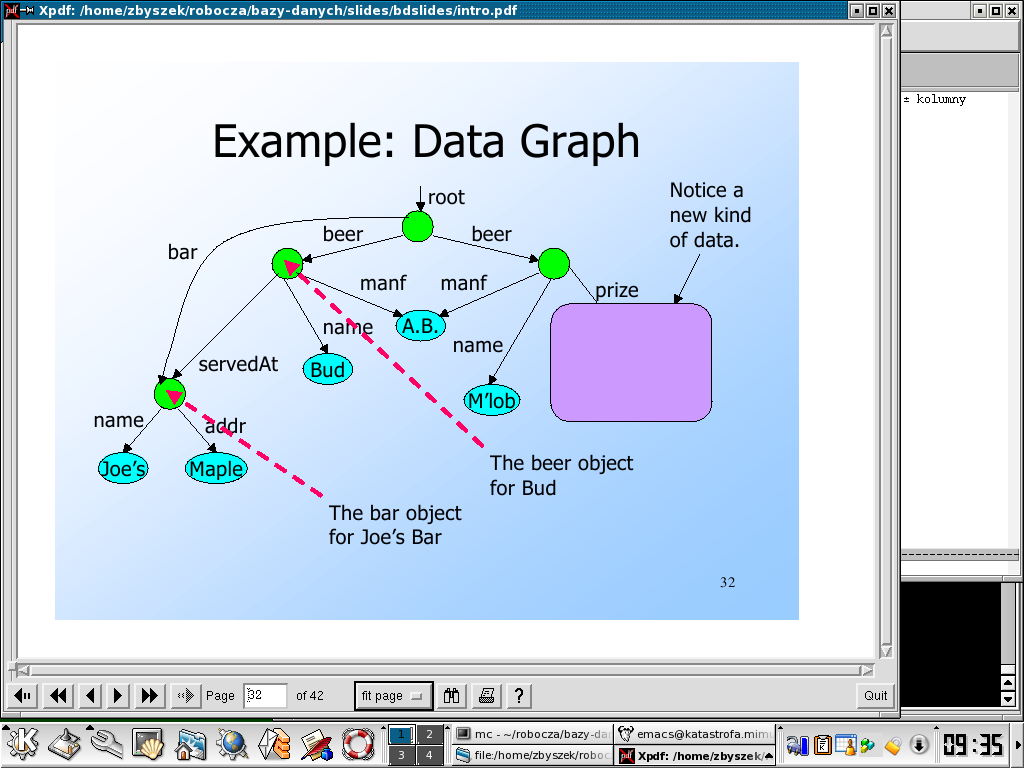
14.2. Graf semistrukturalny
Grafem semistrukturalnym nazywamy graf skierowany o następujących własnościach:
-
Jego wierchołkami są obiekty.
-
Krawędzie są etykietowane atrybutami obiektu, z którego wychodzą.
-
Wartości (atomowe) znajdują się wyłącznie w liściach drzewa.
Jak widać z powyższej definicji, model semistrukturalny daje dużą elastyczność: brak jest ograniczeń na etykiety wychodzących krawędzi ani na liczbę następników wierzchołka.
14.3. Zapytania
Języki zapytań (np. Lorel) są oparte na pojęciu ścieżki. Ścieżka jest to wyrażenie regularne, opisujące drogę od korzenia do poszukiwanego wierzchołka (lub wierzchołków).
Przykłady ścieżek:
biblio.ksiazka|artykul.autor biblio._*.autor
14.3.1. Przykłady zapytań
Popatrzmy na kilka przykładów zapytań.
Podaj wszystkich autorów książek:
Query z1 select autor: x from biblio.ksiazka.autor x;
Podaj wszystkie pozycje, których autorem jest Jeffrey Ullman:
Query z2 select pozycja: x from biblio._ x where "Jeffrey Ullman" in X.autor;
Podaj autorów wszystkich pozycji z bazą danych w tytule:
Query z3 select autor: x from biblio._ x, x.autor y, x.tytul z where ".*(D|d)atabase.*" ̃ z;
Podaj autorów i tytuły wszystkich książek:
Query z4 select pozycja: tytul: y, autor: z from biblio.ksiazka x, x.tytul y, x.autor z;
14.4. XML
Dzięki gwałtownemu rozwojowi sieci WWW i stron pisanych w HTML odkryto na nowo zalety nawiasowanej reprezentacji danych. Rozwój języka XML (eXtensible Markup Language), opartego na SGML, zmierza w kierunku standaryzacji reprezentacji danych zapisywanych tekstowo w plikach i przesyłanych siecią.
Obecnie większość narzędzi do wspomagania budowy oprogramowania (CASE — Computer-Aided Software Engineering jest wyposażona w możliwość odczytywania (importu) i zapisywania (eksportu) plików w notacji XML.
Język XML, podobnie jak HTML, służy do pisania dokumentów ze znacznikami (tags). W HTML jednak jest ustalony zbiór znaczników. Wybrano je pod kątem ,,prezentacji” informacji (inaczej mówiąc do jej formatowania), np. <blockquote> czy <pre.
W XML natomiast znaczniki są badziej semantyczne, np. <student>, i mogą być dowolnie definiowane przez piszącego.
Generalnie, XML jest to język do reprezentowania danych posiadających strukturę (najlepiej drzewiastą). Wyrażenie XML jest to w pełni nawiasowana forma zapisu danych. Nawiasy w XML posiadają etykiety (inaczej mówiąc są to znaczniki frazowe), na przykład zamiast zapisywać listę liczb 3, 5 i 4 w postaci
(3 5 4)
w XML napiszemy
<nawias>3 5 4</nawias>
Jednostki <nawias> i </nawias> nazywa się znacznikiem
początkowym i znacznikiem końcowym, można jednak traktować je
po prostu jako nawiasy otwierające i zamykające. Oczywiście nazwa
znacznika w powyższym przykładzie nie została wybrana najlepiej, lepsza
byłaby ,,lista”.
14.4.1. Elementy
Używając XML można obudować znacznikami niemal dowolny ciąg znaków. Parę znaczników wraz z tekstem pomiędzy nimi nazywa się elementem, np.
<actor> ... </actor>
Ciąg znaków zawarty w znaczniku stanowi nazwą elementu, zaś tekst pomiędzy znacznikami to zawartość elementu, ponadto znacznik początkowy wyrażenia XML może zawierać atrybuty, na przykład poniższy element
<nawias title="oceny" date="2004-10-22"> 3 5 4 </nawias>
ma dwa atrybuty: title i date. Wartościami tych
atrybutów są napisy "oceny" oraz "2004-10-22".
Wyjątek stanowią znane nam z HTML elementy proste, np. <br>. Nie posiadają one zawartości. W wersji HTML zgodnej z XML (tzw. XHTML) muszą one być zapisywane następująco: <br />. Uwaga: odstęp przed ukośnikiem nie jest konieczny, ale niektóre przeglądarki HTML go wymagają.
14.4.2. Zapis listowy w XML
Przypuśćmy, że chcemy zapisać protokół ocen studentów. W językach wysokiego poziomu o bogatej składni literałów (np. w Lispie, Prologu lub Dylanie) moglibyśmy użyć nawiasowanej listy
("Technologia produkcji oprogramowania" "Zima/2004"
("201" 78 88 69)
("202" 88 87 86)
("203" 99 88 88)
("204" 77 78 77)
("205" 90 89 81)
("206" 67 78 81))
Powyższa reprezentacja pochodzi z Lispu, w Prologu użylibyśmy nawiasów kwadratowych, a elementy list oddzielalibyśmy przecinkami.
Tę samą informację można zapisać w postaci wyrażenia XML. Warto zauważyć, że w tym zapisie informacja dotycząca przedmiotu i semestru podana jest w atrybutach elementu <egzamin>, co ułatwia wymianę informacji. Podobnie nazwisko studenta i indeks podane są jako atrybuty elementu <wyniki>. Dodatkowo ocena za każde zadanie została wydzielona w osobny element.
<egzamin przedmiot="TPO ZSI" semestr="Jesień 2004">
<oceny indeks="201">
<pkt>78</pkt> <pkt>88</pkt> <pkt>69</pkt>
</oceny>
<oceny indeks="202">
<pkt>88</pkt> <pkt>87</pkt> <pkt>86</pkt>
</oceny>
<oceny indeks="203">
<pkt>99</pkt> <pkt>88</pkt> <pkt>88</pkt>
</oceny>
<oceny indeks="204">
<pkt>77</pkt> <pkt>78</pkt> <pkt>77</pkt>
</oceny>
<oceny indeks="205">
<pkt>90</pkt> <pkt>89</pkt> <pkt>81</pkt>
</oceny>
<oceny indeks="206">
<pkt>67</pkt> <pkt>78</pkt> <pkt>81</pkt>
</oceny>
</egzamin>
Widać tu wyraźnie, że XML jest uogólnieniem nawiasowanego zapisu list. Nawiasy są nazywane (etykietowane), a każdy nawiasowany element może mieć dodatkowe atrybuty.
Jakkolwiek XML dopuszcza używanie dowolnych znaczników, w praktyce każdy dokument XML powinien posiadać uprzednio zdefiniowany schemat. Schemat dokumentu XML opisuje hierarchiczną strukturę dokumentu oraz dozwolone znaczniki używane dla elementów i ich atrybuty.
Używa się do tego osobnych dokumentów o specjalnej budowie. Początkowo było to DTD (Document Type Description), nowsze rozwiązanie to XML Schema.
Na opis schematu dokumentu można patrzeć jak na definicję używanego słownika.
14.4.3. Dokument
Z formalnego punktu widzenia dokument XML jest pojedynczym elementem (oczywiście zapewne zagnieżdżonym). Może być poprzedzony opcjonalnym prologiem zawierającym
-
deklarację wersji XML
<?xml version="1.0" ?>
-
definicję typu dokumentu (DTD), najczęściej zawierającą odwołanie do osobnego pliku
<!DOCTYPE nazwa głównego elementu SYSTEM "plik.dtd">
<?xml version="1.0" standalone="no" ?> <!DOCTYPE Student SYSTEM "student.dtd"> <Student> ... </Student>
Poprawność dokumentu XML można określić na dwóch poziomach. Pierwszy poziom to dokument poprawnie zbudowany (well-formed). Wymagana jest poprawność syntaktyczna, znaczniki muszą być ,,sparowane”: każdemu znacznikowi otwierającemu (np. <student> musi odpowiadać znacznik zamykający (np. </student>). Wartości atrybutów zawsze muszą być w cudzysłowach. Nie wymaga się natomiast określania DTD.
Poziom drugi określa się terminem Valid: dokument musi być dodatkowo opisany zadeklarowanym schematem DTD (Document Type Definition) i zgodny z nim ;-)
14.4.3.1. DTD
DTD powinien zawierać definicje wszystkich używanych w dokumencie elementów (czyli znaczników). Każdy element deklarujemy znacznikiem !ELEMENT, w którym podajemy nazwę elementu i jego składniki (czyli zawartość).
-
<!DOCTYPE element-główny [ element ... ]>
-
<!ELEMENT element (składnik,...)>
Przykład
<!DOCTYPE Studenci [ <!ELEMENT Studenci (Student*)> <!ELEMENT Student (imie,nazwisko,adres,rok)> <!ELEMENT imie (#PCDATA)> <!ELEMENT nazwisko (#PCDATA)> ... ]>
Przy deklarowaniu składników elementu w znacznikach DTD używa się odmiany wyrażeń regularnych. Oprócz nazwanych elementów mogą tam wystąpić specjalne elementy, oznaczające zwykłe teksty
-
#PCDATA to dowolny tekst nie zawierający znaczników
-
CDATA to dowolny tekst
Po składnikach i pomiędzy nimi mogą wystąpić operatory oznaczające
| ? | element opcjonalny |
| * | 0 lub więcej powtórzen |
| + | 1 lub więcej powtórzen |
| | | alternatywa |
Popatrzmy na przykład użycia DTD
<?xml version="1.0" standalone="no" ?> <!DOCTYPE Studenci SYSTEM "student.dtd"> <Studenci> <Student> <imie>Onufry</imie> <nazwisko>Zagłoba</nazwisko> <adres>Dzikie Pola</adres> <rok>1648</rok> </Student> <Student> ... </Student> ... ]> </Studenci>
Oprócz znaczników opisujących elementy w DTD mogą wystąpić znaczniki opisujące atrybuty elementów. Mają one postać
-
<!ATTLIST element atrybut zbiór wartości opcje>
Opcje mogą zawierać
-
wartość domyślną (ze zbioru wartości)
-
#REQUIRED oznaczające atrybut wymagany
Przykład DTD z atrybutami
<!DOCTYPE Giełda [ <!ELEMENT giełda (tytuł?, kurs*)> <!ELEMENT kurs (#PCDATA)> <!ATTLIST kurs waluta CDATA #REQUIRED typ (sprzedaż|kupno|średni) "średni"> ... ]>
i jego użycie
<?xml version="1.0" ?> <giełda> <tytuł>Kursy walut</tytuł> <kurs waluta="USD">4,235</kurs> ... </giełda>
14.4.3.2. DTD — atrybuty
Atrybuty umieszcza się w znaczniku otwierającym, aby sprecyzować pewne jego cechy. Każdy atrybut ma postać: atrybut=”wartość”.
Oprócz określania drugorzędnych cech znacznika atrybuty są także używane do łączenia elementów jako łączniki (links).
Atrybuty deklaruje się w DTD konstrukcją
<!ATTLIST element atrybut typ ...>
A oto przykład DTD z atrybutami
<!DOCTYPE Studenci [
<!ELEMENT Studenci (Student*)>
<!ELEMENT Student (imie,nazwisko,adres,rok)>
<!ATTLIST Student
studentID ID
chodziNa IDREFS>
<!ELEMENT nazwisko (#PCDATA)>
...
]>
i sposób jego użycia
<?xml version="1.0" standalone="no" ?> <!DOCTYPE Studenci SYSTEM "student.dtd"> <Studenci> <Student studentID="OZ" chodziNa="ms,gpp"> <imie>Onufry</imie> <nazwisko>Zagłoba</nazwisko> <adres>Dzikie Pola</adres> <rok>1648</rok> </Student> <Student> ... </Student> ... ]> </Studenci>
14.4.4. Powiązania między dokumentami
14.4.4.1. Atrybuty łączące
Atrybuty łączące mają ustalone, standardowe nazwy.
Atrybut ID to podaje identyfikator znacznika z myślą o wykorzystaniu tego identyfikatora w innych elementach i dokumentach.
Atrybut IDREF jest to właśnie referencja do wartości atrybutu ID w innym elemencie.
Wadą atrybutów łączących jest brak ,,kontroli typów”! Jest to bowiem najprostszy mechanizm, można użyć bogatszych: XLink i XPointer.
Podjęzyk XLL (eXtensible Link Language), inaczej XLink, daje więcej możliwości opisu niż klasyczne odsyłacze HTML. Można tworzyć odsyłacz do wielu dokumentów (z wyborem przez użytkownika) oraz do grup dokumentów (odpowiednik ramki z wykazem pozostałych).
14.4.5. Wyświetlanie
Dokument zapisany w XML można przekształcić na inną postać, a także umieścić jako stronę na serwerze WWW. Trzeba jednak wtedy określić sposób wyświetlania.
Do prostych zastosowań wystarczą kaskadowe arkusze stylów (CSS, Cascading Style Sheets) z HTML. Arkusz CSS deklaruje się zwykle w nagłówku dokumentu konstrukcją
<link rel="stylesheet" type="text/css" href="nazwa.css">
Elementy stylu można też umieszczać jako atrybuty elementów
<li style="color: red">
W SGML do opisu sposobu prezentacji używa się DSSSL — języka zbliżonego do języka programowania Scheme.
W XML możemy określić sposób wyświetlania znaczników używając XSL (eXtensible Stylesheet Language), pozwalającego określić np. że
-
znacznik <giełda> ma być wyświetlany jako tabela (<table>).
-
znacznik <kurs> ma być wyświetlany jako wiersz tabeli (<tr>).
Istnieją parsery XML (i ogólnie SGML) pozwalające dokonać konwersji na dowolną inną postać (np. TeX).
14.4.6. Wymiana informacji a XML
Jedno z popularnych zastosowań dokumentów XML to wymiana informacji między różnymi narzędziami CASE.
Strukturę aplikacji wymodelowaną w UML w takich narzędziach jak Rational Rose, Umbrello czy Visual Paradigm można zapisać jako dokument XML i następnie wczytać do innego narzędzia, np. generatora specjalizowanej aplikacji, lub umieścić na stronie WWW.
Zasady odwzorowania:
-
obiekty
 dokumenty XML
dokumenty XML -
klasy
schematy XML
14.4.6.1. XMI
Do tych celów OMG (Object Management Group) [www.omg.org] zaproponowała jako standardowy format wymiany schemat XMI (XML Metadata Interchange) [http://cgi.omg.org/cgi-bin/doc?ad/01-06-12]. Wiele ciekawych informacji na ten temat mozna znależć na stronie [http://XMLmodeling.com].


