Zagadnienia
4. Język SQL — część 2
4.1. Wstawianie wierszy
Nowe wiersze do tabeli wstawiamy poleceniem INSERT
INSERT INTO tabela VALUES (wartość,...);na przykład
INSERT INTO Gatunki
VALUES ('krowa','Europa',FALSE,FALSE);
Wartości można podawać w innej kolejności niż w definicji tabeli, wtedy jednak trzeba po nazwie tabeli podać w nawiasach listę nazw kolumn w odpowiedniej kolejności. Dzięki temu można nie podawać wartości dla kolumn dopuszczających NULL.
INSERT INTO Gatunki(nazwa,chroniony,kontynent)
VALUES ('krowa',FALSE,'Europa');
Daty zapisujemy wyrażeniem
DATE '2008-03-11'chociaż dla kolumny typu DATE podanie napisu jest też akceptiowane i powoduje wykonanie automatycznej konwersji.
Czas podajemy wyrażeniem
TIME '15:00:07'zaś łączny zapis daty i czasu ma postać
TIMESTAMP '2008-03-11 15:00:10'
4.2. Modyfikacja wierszy
Zawartość niektórych kolumn może ulegać zmianom. Takich zmian dokonuje się poleceniem UPDATE
UPDATE tabela SET kolumna = wartość, ... WHERE warunek;
Zmiana dotyczy wszystkich wierszy, dla których jest spełniony warunek. Jeśli warunek został pominięty, zmiana dotyczy wszystkich wierszy w tabeli!
Czasem zmiana słuzy do uzupełnienia lub korekty informacji
UPDATE Gatunki SET grozny = FALSE WHERE nazwa = 'krowa';
Często dokonanie zmian jest wymuszone przez zmiany w otaczającym świecie
UPDATE Zwierz SET wiek = wiek + 1;
4.3. Usuwanie wierszy
Usuwanie wierszy to najprostsza operacja modyfikacji
DELETE FROM tabela WHERE warunek;
Usuwane są wszystkie wiersze, dla których jest spełniony warunek. Jeśli warunek został pominięty, usuwane są wszystkie wiersze w tabeli!
DELETE FROM Gatunki WHERE nazwa = 'krowa';
4.4. Zapytania na kilku tabelach
Czasem poszukiwana informacja znajduje się w kilku tabelach. Aby zapytanie dotyczyło kilku tabel, należy je podać we frazie FROM
Jeśli w używanych tabelach powtarzają się nazwy atrybutów, należy użyć notacji tabela.atrybut
Zaczniemy od przykładu zwykłego złączenie dwóch relacji. Zapytajmy o imiona wszystkich zwierzaków pochodzących z Afryki.
SELECT imie FROM Zwierz, Gatunki WHERE Gatunki.nazwa = Zwierz.gatunek AND kontynent = 'Afryka';
Bardzo niepraktyczna semantyka formalna mogłaby wyglądać tak
-
Utwórz iloczyn kartezjański wszystkich tabel z frazy FROM.
-
Używając otrzymanego wyniku, postępuj jak dla zapytania opartego na pojedynczej tabeli.
Warto też obejrzeć uproszczoną semantykę operacyjną
-
Z każdą tabelą z frazy FROM związujemy ukrytą zmienną krotkową (zwykle nazywającą się tak jak tabela i wskazującą na ,,bieżący” wiersz).
-
Przy dwóch tabelach:
-
Dla każdej wartości zmiennej krotkowej z pierwszej tabeli znajdujemy wszystkie ,,pasujące” wiersze z drugiej tabeli, przechodząc po niej jej zmienną krotkową.
-
Dla każdego znalezionego wiersza łączymy go z wierszem z pierwszej tabeli i przetwarzamy jak dla pojedynczej tabeli (tzn. sprawdzamy warunek itd.).
-
-
Analogicznie postępujemy przy większej liczbie tabel wprowadzając kolejne zagnieżdżone pętle iteracyjne.
4.4.1. Jawne zmienne krotkowe
Czasami w zapytaniu chcemy dwukrotnie użyć tej samej tabeli. Aby móc odróżniać te wystąpienia tabeli, we frazie FROM po nazwie tabeli można umieścić zmienną krotkową.
Oczywiście można tak zrobić dla dowolnej tabeli, np. aby w innych frazach używać krótszej nazwy.
Pora na przykład samozłączenia — złączenia tabeli z nią samą. Mamy napisać zapytanie spełniające następujące warunki:
-
Podaj wszystkie pary zwierzaków (ich imiona) tego samego gatunku.
-
Unikaj par identycznych typu (Kropka,Kropka).
-
W ramach pary zachowaj porządek alfabetyczny, tzn. (Kropka,Puszek) a nie (Puszek,Kropka).
SELECT z1.imie,z2.imie FROM Zwierz z1, Zwierz z2 WHERE z1.gatunek = z2.gatunek AND z1.name < z2.name;
4.5. Podzapytania
Nawiasowane wyrażenie SELECT (podzapytanie) można umieszczać we frazach WHERE i FROM (a w pewnych sytuacjach także we frazie SELECT, ale nie próbujcie robić tego w domu).
We frazie FROM po podzapytaniu musi wystąpić zmienna krotkowa, a wynik podzapytania traktowany jest w zewnętrznym zapytaniu tak, jak dodatkowa tabela (a ściślej perspektywa). Przykład: podaj imiona najcięższych zwierzaków z każdego gatunku
SELECT imie
FROM Zwierz, (SELECT gatunek,MAX(waga) AS maks
FROM Zwierz
GROUP BY gatunek) mwg
WHERE Zwierz.gatunek = mwg.gatunek
AND waga = maks;
Jeśli używamy podzapytania we frazie WHERE w zwykłym porównaniu, to powinno ono zwracać pojedynczą wartość. Przykład: podaj imiona zwierzaków, które ważą najwięcej
SELECT imie
FROM Zwierz
WHERE waga = (SELECT MAX(waga)
FROM Zwierz);
Podzapytania bardzo często używa się w połączeniu z operatorem IN. Może ono wtedy zwracać wiele wartości, ale może mieć tylko jedną kolumnę w wyniku.
Podaj imiona wszystkich zwierzaków pochodzących z Afryki.
SELECT imie
FROM Zwierz
WHERE gatunek IN (SELECT nazwa
FROM Gatunki
WHERE kontynent = 'Afryka');
4.6. Złączenia
-
Warunki łączące dla złączeń można zapisywać we frazie FROM
-
Jeszcze raz imiona wszystkich zwierzaków pochodzących z Afryki.
SELECT imie FROM Zwierz JOIN Gatunki ON (Gatunki.nazwa = Zwierz.gatunek) WHERE kontynent = 'Afryka';
Standard SQL-92 podaje operatory złączeń do używania we frazie FROM:
| T1 CROSS JOIN T2 | Iloczyn kartezjański |
|---|---|
| T1 NATURAL JOIN T2 | Złączenie naturalne (równościowe po kolumnach o tych samych nazwach) |
| T1 INNER JOIN T2 | Zwykłe złączenie |
| T1 LEFT OUTER JOIN T2 | Złączenia zewnętrzne |
| T1 RIGHT OUTER JOIN T2 | |
| T1 FULL OUTER JOIN T2 |
Po takim wyrażeniu dodatkowo podajemy
| USING (kolumna, ...) | nazwy kolumn po których łączymy |
| ON warunek | warunek ograniczający na złączenie |
4.7. Perspektywy
W SQL relacja to tabela lub perspektywa.
Tworzenie perspektywy
CREATE VIEW nazwa [(atrybut ...)] AS zapytanie;na przykład
CREATE VIEW GatunkiAfryki AS SELECT * FROM Gatunki WHERE kontynent = 'Afryka';
Usuwanie perspektywy
DROP VIEW nazwa;
Uproszczona semantyka operacyjna dla zapytań z perspektywami:
-
Nazwę perspektywy we frazie FROM w zapytaniu zastępuje się relacjami, na podstawie których ją utworzono.
-
Warunki z definicji perspektywy dołącza się do warunków zapytania.
Modyfikacje są dozwolone tylko dla aktualizowalnych perspektyw:
-
zbudowanych na podstawie pojedynczej tabeli, oraz
-
obejmujących wszystkie atrybuty nie posiadające wartości domyślnych.
Warto zabronić operacji wstawiania i modyfikacji perspektywy dających wiersze, które nie bedą należeć do perspektywy, używając podczas jej tworzenia frazy WITH CHECK OPTION:
CREATE VIEW GatunkiAfryki AS SELECT * FROM Gatunki WHERE kontynent = 'Afryka' WITH CHECK OPTION;
4.8. Kursory
-
Kursory służą do krokowego przeglądania wyniku zapytania. Używa się ich przede wszystkim w procedurach składowanych.
-
Kursor deklarujemy poleceniem DECLARE
DECLARE kursor_gatkon CURSOR FOR SELECT gatunek, kontynent FROM Gatunki;
-
Z kursora można pobierać kolejne wiersze używając polecenia
FETCH [ kierunek ] [ ile ] IN | FROM cursor
-
Parametr kierunek definiuje kierunek pobierania wierszy i może być równy
FORWARD pobiera następne wiersze (zachowanie domyślne) BACKWARD pobiera poprzednie wiersze. -
Parametr ile określa, ile wierszy należy pobrać i może być równy
n Liczba ze znakiem podająca liczbę wierszy do pobrania. Podanie liczby ujemnej zamienia znaczenie FORWARD i BACKWARD. ALL Wszystkie pozostałe wiersze. NEXT Równoważny podaniu 1. PRIOR Równoważny podaniu -1.
Aby pobrać dwa kolejne wiersze z kursora
=> FETCH 2 FROM kursor_gatkon; gatunek kontynent ---------------------- lew Afryka bóbr Europa
Po kursorze można się cofać
FETCH -1 FROM kursor_gatkon;lub
-- Pobierz poprzedni wiersz FETCH BACKWARD 1 FROM kursor_gatkon;
-
Kursor można pozycjonować bez pobierania wierszy poleceniem
MOVE [ kierunek ] [ ile ] IN | FROM kursor
Znaczenie parametrów jest takie, jak dla FETCH. -
Aby przestawić kursor o 5 wierszy do przodu
MOVE 5 FROM kursor_gatkon;
-
Na zakończenie kursor należy zamknąć
CLOSE kursor_gatkon;
-
Uwaga: kursory działają tylko wewnątrz transakcji, czyli przed ich użyciem należy wykonać
BEGIN WORK;
(o ile nie jesteśmy wewnątrz otwartej transakcji), a potem (niekoniecznie natychmiast) zamknąć transakcjęCOMMIT WORK;
-
Nie jest możliwa aktualizacja bieżącego wiersza kursora, trzeba używać niezależnego polecenia UPDATE.
-
SQL92 nie zawiera polecenia MOVE, ale za to pozwala na absolutne pozycjonowanie kursora, co w PostgresSQL nie jest zrealizowane.
4.9. Asercje i dziedziny
-
Nie występują nigdzie poza standardem. Składnia:
CREATE ASSERTION nazwa CHECK (warunek);
-
Przykład użycia:
CREATE ASSERTION DodatniaWaga CHECK (NOT EXISTS (SELECT * FROM Zwierz WHERE waga < 0));
Służą do określania typów danych. Polecenie
CREATE DOMAIN AdresTyp AS VARCHAR(40) DEFAULT 'Nieznany';tworzy nowy typ, którego można użyć wewnątrz CREATE TABLE
CREATE TABLE Studenci ( indeks CHAR(6) PRIMARY KEY, imie VARCHAR(15) NOT NULL, nazwisko VARCHAR(15) NOT NULL, adres AdresTyp );
Dziedzinę usuwamy poleceniem
DROP DOMAIN Adres;
4.10. Indeksy
-
Polecenie CREATE INDEX definiuje nowy indeks dla podanej tabeli. Pojawiło się dopiero w SQL-99.
CREATE [ UNIQUE ] INDEX nazwa-indeksu ON tabela (kolumna [, ...]) [ WHERE warunek ]
-
Parametr UNIQUE powoduje sprawdzanie duplikatów w tabeli podczas tworzenia indeksu i przy każdej modyfikacji.
-
Utworzony indeks będzie oparty na kluczu powstałym przez konkatenację podanych kolumn.
-
Do usuwania indeksu służy polecenie DROP INDEX.
-
Utworzymy indeks na kolumnie kontynent tabeli Gatunki
CREATE INDEX IndGat ON Gatunki(kontynent);
-
Indeks może obejmować kilka kolumn.
CREATE INDEX IndKontChron ON Gatunki(kontynent,chroniony);
-
Usuwanie indeksu:
DROP INDEX IndGat;
-
Istnieje też inna postać definicji indeksu:
CREATE [ UNIQUE ] INDEX nazwa-indeksu ON tabela ( funkcja( kolumna [, ... ]) ) [ WHERE warunek ]
-
Służy ona do definiowania indeksów funkcyjnych, gdzie wartością klucza indeksowego jest wynik wywołania określonej przez użytkownika funkcji, której parametrami są podane kolumny indeksowanej tabeli.
-
Przykładowo, użycie funkcji upper(kolumna) pozwoli podczas indeksowania ignorować rozróżnianie dużych i małych liter.
CREATE INDEX test1_idx ON test1 (upper(kol1));
-
Wartość funkcji używanej w indeksie musi zależeć jedynie od jej argumentów. Podczas jej tworzenia należy ją oznaczyć jako ustaloną (immutable).
-
Jeśli w definicji indeksu występuje klauzula WHERE, to powstanie indeks częściowy, zawierający pozycje tylko dla wierszy tabeli spełniających podany warunek.
-
Na przykład w tabeli zamówień można by zdefiniować indeks tylko dla wierszy zawierających 'tak' w kolumnie zapłacono.
-
Wyrażenie w klauzuli WHERE może odwoływać się tylko do kolumn indeksowanej tabeli, nie wolno też używać podzapytań ani funkcji agregujących.
4.11. Sekwencje
-
Służą do otrzymania kolejnych wartości dla kolumn typu całkowitego.
-
Tworzenie
CREATE SEQUENCE sekw_kat INCREMENT BY 1 START WITH 1;
-
Generowanie kolejnej wartości funkcją nextval (jej argumentem jest nazwa generatora):
SELECT nextval('sekw_kat'); -
Wywołanie nextval można też umieścić we frazie DEFAULT definicji kolumny w poleceniu CREATE TABLE.
-
Do otrzymania bieżącej wartości generatora sekwencji służy funkcja curval.
SELECT curval('sekw_kat');zaś do ustawienia na konkretną wartość funkcja setvalSELECT setval('sekw_kat', 12); -
Zamiast umieszczać wywołanie nextval we frazie DEFAULT, można jako typ takiej kolumny podać SERIAL. Zostanie wtedy automatycznie utworzona sekwencja, a kolumna będzie w rzeczywistości typu INT4.
4.12. Varia
Zmiana hasła użytkownika
ALTER USER nazwa PASSWORD 'nowe-hasło';
4.13. Laboratorium: typy danych
4.13.1. Napisy
4.13.1.1. Wbudowane operacje na napisach
Najczęściej używane operacje to:
-
length(nap) podaje długość napisu nap w znakach;
-
trim(nap) zwraca napis nap z usuniętymi początkowymi i końcowymi spacjami. Warianty: trim(BOTH, nap), trim(LEADING, nap), trim(TRAILING, nap).
-
substr(str,m,n) zwraca fragment napisu str, rozpoczynający się od znaku o numerze m o długości n znaków. Parametr n można pomijać, otrzymamy wtedy całą resztę napisu. Oczywiście wynki jest napisem.
-
substring(kol FROM m FOR n) — to samo.
-
rpad(kol,n[,znak]) zwraca napis w kolumnie
koluzupełniony na końcu spacjami do szerokościn. Opcjonalny trzeci argument podaje inny znak do wypełniania. -
lpad(kol,n[,znak]) jak poprzednia, ale uzupełnia na początku.
-
lower(kol) zamienia dużę litery w napisie na małe.
-
upper(kol) zamienia małe litery w napisie na dużę.
-
initcap(kol) ustawia pierwszą literę na dużą.
-
position(str1 IN kol) szuka napisu str1 w napisie str2 i zwraca numer pierwszego znaku znalezionego wystąpienia napisu str1.
-
strpos(kol,pos) — to samo.
-
str1 || str2 zwraca konkatenację napisów str1 i str2.
Przypuśćmy, że w kolumnie student mamy zapisaną informację w postaci 'nazwisko imię', a chcemy odwrócić tę kolejność na postać 'imię nazwisko':
substr(student, position(' ' IN student) + 1)
|| ' '
|| substr(student, 1, position(' ' IN student))
4.13.2. Daty i czas
W Postgresie daty i czas są obsługiwane zgodnie ze standardem SQL2. Cztery podstawowe wbudowane typy to DATE, TIME, TIMESTAMP i INTERVAL. Typ TIMESTAMP obejmuje zarówno datę jak i czas.
Typów takich jak DATE używa się tak samo jak innych, na przykład do tworzenia kolumn tabeli
CREATE TABLE x(a int, b date);
4.13.2.1. Zewnętrzna reprezentacja dat
Przed wyświetleniem daty zamieniane są automatycznie na napis.
Do konwersji używa się funkcji to_char, według ustalonego
formatu domyślnego. U nas domyślnym formatem jest ISO, tzn.
'YYYY-MM-DD', na przykład
SELECT b FROM x; B ---------- 2004-04-01
Sposób wyświetlania daty można zmienić wywołując samemu to_char
z własnym formatem
SELECT to_char(b, 'YYYY/MM/DD') AS b FROM x; B ---------- 2004/04/01
Funkcja to_char ma składnię:
to_char(data, 'format')
W formacie można używać rozmaitych specyfikacji, najpopularniejsze to:
| MM | Miesiąc cyframi (np. 07) |
|---|---|
| MON | Skrócona nazwa miesiąca (np. JUL) |
| MONTH | Pełna nazwa miesiąca (np. JULY) |
| DD | Dzień cyframi (np. 24) |
| DY | Skrócona nazwa dnia tygodnia (np. FRI) |
| YYYY | Rok czterema cyframi (np. 2004) |
| YY | Dwie ostatnie cyfry roku (np. 04) |
Przy wczytywaniu dat używa się funkcji date, zamieniającej napis na datę zgodnie z domyślnym formatem. Zwykle nie wywołuje się jej jawnie, ponieważ Postgres tam, gdzie jest wymagany argument typu data, automatycznie zamienia napis na datę wołając date, na przykład
insert into x values(99, '2004-05-31');W innych sytuacjach trzeba jawnie wywoływać funkcję date.
Chcąc użyć innego formatu należy wywołać funkcje to_date:
INSERT INTO x
VALUES(99, to_date('2004/05/31', 'yyyy/mm/dd'));
Funkcja to_date ma składnię:
to_date(napis, 'format')
gdzie dla formatu obowiązują te same opcje co dla to_char.
Domyślny format daty zmienia się instrukcją SET DATESTYLE, na przykład:
SET DATESTYLE TO SQL, DMY;Dozwolone wartości pierwszego parametru to: ISO, SQL, POSTGRES, a drugiego: EUROPEAN, US, NONEUROPEAN.
4.13.2.2. Bieżąca data i czas
Standardowe zmienne current_date i current_time zwracają
bieżącą datę i czas.
SELECT current_date AS "Bieżąca data", current_time AS "Teraz"; Bieżąca data Teraz ---------------------------- 2004-01-01 21:18:27
Zmienna current_timestamp podaje zarówno datę jak i czas.
4.13.2.3. Operacje na datach
Daty można porównywać standardowymi operatorami porównania =, !=, >, itp.
Daty można odejmować od siebie, Otrzymując wynik typu TIMESPAN.
Do dat można dodawać liczby lub odejmować je od nich, na przykład current_date + 1 to dzień jutrzejszy.
Po przekształceniu na napis funkcją to_char, można na datach
wykonywać wszelkie operacje dla napisów, na przykład
to_char(date, 'DD-MON-YY') LIKE '%JUN%'
zwraca prawdę jeśli mamy do czynienia z datą czerwcową.
4.13.3. Liczby
Dla liczbe określone są funkcje abs, round i trunc.
4.14. Zadania
Ćwiczenie 4.1
Dane jest tabela ![]() oraz zapytania w SQL
oraz zapytania w SQL
|
|
SELECT DISTINCT a,b FROM R; |
|---|---|
|
|
SELECT a,b FROM R GROUP BY a,b; |
Które z poniższych stwierdzeń są prawdziwe
-
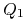 i
i 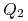 dają ten sam wynik.
dają ten sam wynik. -
Odpowiedź na
może zawierać mniej wierszy niż odpowiedź
na . -
i mogą dać inne wyniki.
Pierwsze.
Ćwiczenie 4.2
Dana jest tabela Sprawdzian
| student | kolokwium | egzamin |
|---|---|---|
| A | 45 | NULL |
| B | NULL | 90 |
| C | 100 | 80 |
Czy następujące zapytanie w SQL
SELECT student FROM Sprawdzian WHERE (kolokwium > egzamin AND egzamin > 75) OR kolokwium < 50
zwróci wiersz dla studenta
-
A
-
B
-
C
-
Tak
-
Nie
-
Tak
Ćwiczenie 4.3
Dana jest tabela R(A,B,C,D) oraz szkielet zapytania:
SELECT [...] FROM R GROUP BY a,b;
Które wyrażenie wolno wstawić w miejsce […]?
-
MIN(c+d)
-
a,b
-
b,c
Pierwsze i drugie.


