9. Doświadczenia Mendla: łańcuchy Markowa w klasycznej genetyce I
W kolejnych wykładach przejdziemy do omówienia podstaw genetyki klasycznej, w szczególności praw dziedziczenia postulowanych przez Mendla na podstawie wyników przeprowadzonych przez niego doświadczeń. Gregor Mendel, żyjący w XIX wieku czeski zakonnik, przez wiele lat zajmował się pracą w ogrodzie. Hodował różne rośliny, w szczególności groszek w dwóch odmianach — o strąkach zielonych i żółtych. Mendel zauważył, że można wyróżnić groszki ,,czysto żółte”, ,,czysto zielone” i ,,mieszane”. Jeśli krzyżuje się dwie rośliny, jedną ,,czysto żółtą”, a drugą ,,czysto zieloną”, to w następnym pokoleniu otrzymuje się rośliny o strąkach zielonych, natomiast przy dalszym krzyżowaniu ze sobą tak otrzymanych roślin, w kolejnym pokoleniu ![]() osobników ma strąki zielone, a
osobników ma strąki zielone, a ![]() żółte. Wyniki swoich badań opublikował w 1866 roku i na ich podstawie wysnuł teorię, którą obecnie nazywamy całkowitą dominacją genów.
żółte. Wyniki swoich badań opublikował w 1866 roku i na ich podstawie wysnuł teorię, którą obecnie nazywamy całkowitą dominacją genów.
W opisie doświadczeń Mendla będziemy używać stosowanych obecnie w genetyce pojęć, w szczególności jednostki kodujące dane cechy nazywać będziemy genami. Cecha badana przez Mendla, czyli kolor strąków groszku, kodowana jest przez parę genów, dziedziczonych po jednym od każdego z rodziców. Gen występuje w dwóch odmianach, które nazywamy allelami: dominującej, którą oznaczymy ![]() i recesywnej
i recesywnej ![]() . Mamy więc trzy genotypy:
. Mamy więc trzy genotypy: ![]() ,
, ![]() ,
, ![]() , ponieważ nie rozróżniamy kolejności występowania genów, zatem
, ponieważ nie rozróżniamy kolejności występowania genów, zatem ![]() i
i ![]() dają ten sam genotyp. Jeśli w genotypie pojawia się choć jeden gen dominujący, to odpowiadająca mu cecha uwidacznia się w danym osobniku, czyli taki groszek ma strąki zielone. Rozróżniamy więc dwa fenotypy — genotypom
dają ten sam genotyp. Jeśli w genotypie pojawia się choć jeden gen dominujący, to odpowiadająca mu cecha uwidacznia się w danym osobniku, czyli taki groszek ma strąki zielone. Rozróżniamy więc dwa fenotypy — genotypom ![]() i
i ![]() odpowiada fenotyp zielony, natomiast
odpowiada fenotyp zielony, natomiast ![]() ma fenotyp żółty. W zależności od genotypu, stosujemy też następujące nazewnictwo:
ma fenotyp żółty. W zależności od genotypu, stosujemy też następujące nazewnictwo:
-
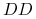 to osobnik (czysto) dominujący;
to osobnik (czysto) dominujący; -
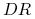 to hybryda;
to hybryda; -
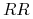 to osobnik (czysto) recesywny.
to osobnik (czysto) recesywny.
W teorii Mendla zakłada się, że osobniki łączą się losowo i potomek dziedziczy losowo po jednym genie od każdego z rodziców, przy czym wybór genów od rodziców jest niezależny. Sprawdźmy więc, jaki genotyp ma potomstwo ustalonej pary rodziców:
-
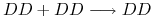 , jeśli krzyżujemy dwa osobniki dominujące, to z prawdopodobieństwem
, jeśli krzyżujemy dwa osobniki dominujące, to z prawdopodobieństwem 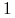 potomek dziedziczy od każdego z rodziców gen dominujący
potomek dziedziczy od każdego z rodziców gen dominujący 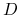 , zatem każdy potomek ma ten sam genotyp ;
, zatem każdy potomek ma ten sam genotyp ; -
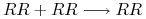 , podobnie jeśli krzyżujemy dwa osobniki recesywne, to z prawdopodobieństwem potomek dziedziczy od każdego z rodziców gen dominujący
, podobnie jeśli krzyżujemy dwa osobniki recesywne, to z prawdopodobieństwem potomek dziedziczy od każdego z rodziców gen dominujący 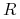 , zatem każdy potomek ma ten sam genotyp ;
, zatem każdy potomek ma ten sam genotyp ; -
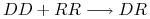 , jeśli krzyżujemy osobnika dominującego z recesywnym, to z prawdopodobieństwem potomek dziedziczy od jednego z rodziców gen , a od drugiego gen , zatem każdy potomek jest hybrydą;
, jeśli krzyżujemy osobnika dominującego z recesywnym, to z prawdopodobieństwem potomek dziedziczy od jednego z rodziców gen , a od drugiego gen , zatem każdy potomek jest hybrydą; -
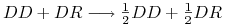 , przy krzyżowaniu osobnika dominującego z hybrydą od osobnika dominującego potomek dziedziczy gen z prawdopodobieństwem , natomiast od hybrydy — albo gen z prawdopodobieństwem
, przy krzyżowaniu osobnika dominującego z hybrydą od osobnika dominującego potomek dziedziczy gen z prawdopodobieństwem , natomiast od hybrydy — albo gen z prawdopodobieństwem 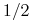 , albo gen , także z prawdopodobieństwem , zatem potomek jest z prawdopodobieństwem albo hybrydą, albo dominantą;
, albo gen , także z prawdopodobieństwem , zatem potomek jest z prawdopodobieństwem albo hybrydą, albo dominantą; -
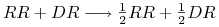 , podobnie przy krzyżowaniu osobnika recesywnego z hybrydą potomek jest z prawdopodobieństwem albo recesywny, albo hybrydyczny;
, podobnie przy krzyżowaniu osobnika recesywnego z hybrydą potomek jest z prawdopodobieństwem albo recesywny, albo hybrydyczny; -
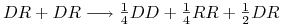 , jeśli natomiast krzyżujemy dwie hybrydy, to z prawdopodobieństwem osobnik dziedziczy albo , albo od każdego z rodziców, stąd mamy rozkład genotypów potomka
, jeśli natomiast krzyżujemy dwie hybrydy, to z prawdopodobieństwem osobnik dziedziczy albo , albo od każdego z rodziców, stąd mamy rozkład genotypów potomka 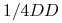 ,
, 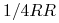 oraz
oraz 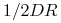 (pamiętając, że nie rozróżniamy układu i
(pamiętając, że nie rozróżniamy układu i 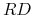 ).
).
Przedstawiony powyżej rozkład genotypów pokazuje, skąd w doświadczeniu Mendla wzięły się proporcje ![]() strąków zielonych i
strąków zielonych i ![]() strąków żółtych. Jeśli bowiem Mendel skrzyżował w pierwszym pokoleniu osobnika czysto dominującego z czysto recesywnym, to każdy osobnik potomny był hybrydą. Następnie krzyżując hybrydy, jeśli tylko potomków w drugiej generacji było dostatecznie dużo, otrzymywał rozkład genotypów odpowiadający proporcjom: po
strąków żółtych. Jeśli bowiem Mendel skrzyżował w pierwszym pokoleniu osobnika czysto dominującego z czysto recesywnym, to każdy osobnik potomny był hybrydą. Następnie krzyżując hybrydy, jeśli tylko potomków w drugiej generacji było dostatecznie dużo, otrzymywał rozkład genotypów odpowiadający proporcjom: po ![]() osobników dominujących i recesywnych oraz
osobników dominujących i recesywnych oraz ![]() hybryd, co uzewnętrzniło się jako
hybryd, co uzewnętrzniło się jako ![]() fenotypu żółtego i
fenotypu żółtego i ![]() fenotypu zielonego.
fenotypu zielonego.
Tego typu doświadczenia można oczywiście powtarzać, ale jeśli znamy genotyp rodziców, to wiemy też, jaki powinien być wynik doświadczenia. Znacznie ciekawsze doświadczenie może polegać na tym, że na podstawie otrzymanych wyników eksperymentów chcemy wnioskować na temat genotypu rodziców. Opiszemy trzy takie doświadczenia, które nazwiemy ciągłym krzyżowaniem z osobnikiem dominującym, recesywnym i hybrydą. Każde z tych doświadczeń przeprowadzamy w taki sam sposób: ustalamy jednego z rodziców (wybieramy osobnika o danym genotypie) i krzyżujemy go z osobnikiem o genotypie nieznanym. Zakładamy, że mamy dostatecznie dużo potomstwa, tak by rozkład genotypów odpowiadał prawdopodobieństwom obliczonym na podstawie prawa Mendla, wybieramy losowo jednego potomka i ponownie krzyżujemy go z tym samym ustalonym osobnikiem. Doświadczenie powtarzamy wielokrotnie. Otrzymujemy więc ciąg doświadczeń, w których wynik kolejnego doświadczenia zależy od wyniku poprzedniego, mamy więc łańcuch Markowa. W celu zinterpretowania wyników eksperymentów przypomnimy podstawowe pojęcia i twierdzenia z teorii łańcuchów Markowa [7, 1].
9.1. Łańcuchy Markowa
Zajmiemy się teraz opisem ciągu zależnych doświadczeń losowych. Niech ![]() oznacza pewne doświadczenie, którego zbiór możliwych wyników
oznacza pewne doświadczenie, którego zbiór możliwych wyników ![]() ,
, ![]() ,
, ![]() , znamy. W trakcie powtarzania tego doświadczenia w próbie z numerem
, znamy. W trakcie powtarzania tego doświadczenia w próbie z numerem ![]() dostajemy wynik o numerze
dostajemy wynik o numerze ![]() , przy czym prawdopodobieństwa różnych wartości
, przy czym prawdopodobieństwa różnych wartości ![]() w ogólnym przypadku mogą zależeć od wyników wszystkich poprzednich doświadczeń. Taki obiekt nazwiemy skończonym procesem stochastycznym. Z kolei łańcuch Markowa to pewien szczególny rodzaj procesu stochastycznego, w którym wynik kolejnej próby zależy tylko od wyniku próby poprzedniej.
w ogólnym przypadku mogą zależeć od wyników wszystkich poprzednich doświadczeń. Taki obiekt nazwiemy skończonym procesem stochastycznym. Z kolei łańcuch Markowa to pewien szczególny rodzaj procesu stochastycznego, w którym wynik kolejnej próby zależy tylko od wyniku próby poprzedniej.
Definicja 9.1
Niech ![]() oznacza ciąg zmiennych losowych o wartościach całkowitych. Jeśli w próbie z numerem
oznacza ciąg zmiennych losowych o wartościach całkowitych. Jeśli w próbie z numerem ![]() zrealizowało się zdarzenie
zrealizowało się zdarzenie ![]() , to przyjmiemy
, to przyjmiemy ![]() . Ciąg zmiennych losowych
. Ciąg zmiennych losowych ![]() nazwiemy łańcuchem Markowa, jeśli
nazwiemy łańcuchem Markowa, jeśli
przy czym jeśli ![]() nie zależy od numeru próby
nie zależy od numeru próby ![]() , to taki łańcuch nazywamy jednorodnym. Wyniki poszczególnych prób nazwiemy stanami łańcucha.
, to taki łańcuch nazywamy jednorodnym. Wyniki poszczególnych prób nazwiemy stanami łańcucha.
Podamy teraz kilka prostych przykładów:
— Rzut monetą to jeden z najprostszych możliwych procesów stochastycznych. Mamy dwa możliwe wyniki każdej próby orzeł ![]() i reszka
i reszka ![]() , przy czym zawsze prawdopodobieństwo otrzymania każdego z tych dwóch wyników wynosi
, przy czym zawsze prawdopodobieństwo otrzymania każdego z tych dwóch wyników wynosi ![]() , niezależnie od tego, jakie wyniki otrzymywaliśmy w przeszłości. Wobec tego rzut monetą jest przykładem jednorodnego łańcucha Markowa.
, niezależnie od tego, jakie wyniki otrzymywaliśmy w przeszłości. Wobec tego rzut monetą jest przykładem jednorodnego łańcucha Markowa.
— Rosyjska ruletka I to wersja gry, w której używa się sześciostrzałowego rewolweru z jedną kulą. Po zakręceniu bębenkiem oddaje się strzał i w pierwszej próbie wynik z prawdopodobieństwem ![]() jest martwy
jest martwy ![]() , a z prawdopodobieństwem
, a z prawdopodobieństwem ![]() — żywy
— żywy ![]() . Wynik kolejnej próby zależy od poprzedniego. Jeśli osoba, do której się strzela, została zastrzelona w poprzedniej próbie, to oczywiście w każdej następnej
jest martwa z prawdopodobieństwem
. Wynik kolejnej próby zależy od poprzedniego. Jeśli osoba, do której się strzela, została zastrzelona w poprzedniej próbie, to oczywiście w każdej następnej
jest martwa z prawdopodobieństwem ![]() , natomiast jeśli jest żywa, to w drugiej próbie będzie martwa z prawdopodobieństwem
, natomiast jeśli jest żywa, to w drugiej próbie będzie martwa z prawdopodobieństwem ![]() , w trzeciej z prawdopodobieństwem
, w trzeciej z prawdopodobieństwem ![]() , następnie
, następnie ![]() ,
, ![]() i ostatecznie w szóstej próbie wynik jest zawsze
i ostatecznie w szóstej próbie wynik jest zawsze ![]() z prawdopodobieństwem
z prawdopodobieństwem ![]() . Widzimy więc, że taka wersja rosyjskiej ruletki stanowi łańcuch Markowa, ale nie jest to łańcuch jednorodny.
. Widzimy więc, że taka wersja rosyjskiej ruletki stanowi łańcuch Markowa, ale nie jest to łańcuch jednorodny.
— Rosyjska ruletka II to inna wersja, w której za każdym razem używa się sześciostrzałowego rewolweru z jedną kulą, ale przed każdą próbą ponownie kręci się bębenkiem. Zatem przy każdej próbie otrzymywane wyniki są jednakowe: ![]() z prawdopodobieństwem
z prawdopodobieństwem ![]() oraz
oraz ![]() z prawdopodobieństwem
z prawdopodobieństwem ![]() . Mamy więc jednorodny łańcuch Markowa.
. Mamy więc jednorodny łańcuch Markowa.
W dalszej części wykładu zajmiemy się tylko łańcuchami jednorodnymi, wobec tego nie będziemy już powtarzać określenia ,,jednorodny łańcuch Markowa”, tylko pisząc ,,łańcuch Markowa” będziemy mieli na myśli łańcuch jednorodny. Taki łańcuch Markowa możemy w jednoznaczny sposób zdefiniować podając jego stany, czyli możliwe wyniki kolejnych eksperymentów, oraz macierz przejścia
![]() , czyli prawdopodobieństwa
, czyli prawdopodobieństwa ![]() przejścia ze stanu
przejścia ze stanu ![]() w próbie
w próbie ![]() do stanu
do stanu ![]() w kolejnej próbie
w kolejnej próbie ![]() . Macierz przejścia ma oczywiście następujące własności:
. Macierz przejścia ma oczywiście następujące własności:
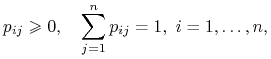 |
ponieważ dla dowolnych ![]() liczba
liczba ![]() jest prawdopodobieństwem, a jeśli łańcuch znajduje się w pewnym stanie
jest prawdopodobieństwem, a jeśli łańcuch znajduje się w pewnym stanie ![]() w chwili
w chwili ![]() , to musi przejść do jakiegoś stanu
, to musi przejść do jakiegoś stanu ![]() w chwili
w chwili ![]() . Macierze o tych własnościach nazywamy macierzami stochastycznymi. Pełny opis łańcucha Markowa możemy także przedstawić za pomocą grafu skierowanego ważonego.
. Macierze o tych własnościach nazywamy macierzami stochastycznymi. Pełny opis łańcucha Markowa możemy także przedstawić za pomocą grafu skierowanego ważonego.
Definicja 9.2
Grafem skierowanym nazywamy parę ![]() , gdzie
, gdzie ![]() jest zbiorem elementów nazywanych wierzchołkami grafu, natomiast
jest zbiorem elementów nazywanych wierzchołkami grafu, natomiast ![]() stanowi zbiór uporządkowanych par wierzchołków, które nazywamy krawędziami grafu.
stanowi zbiór uporządkowanych par wierzchołków, które nazywamy krawędziami grafu.
W przypadku grafu ważonego każdej istniejącej krawędzi prowadzącej od wierzchołka ![]() do
do ![]() przypisujemy pewną wagę
przypisujemy pewną wagę ![]() . Graf opisujący łańcuch Markowa budujemy w następujący sposób
. Graf opisujący łańcuch Markowa budujemy w następujący sposób
-
wierzchołek z numerem
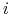 ,
, 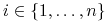 odpowiada wynikowi
odpowiada wynikowi 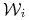 ;
; -
od wierzchołka z numerem
do wierzchołka z numerem 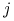 przeprowadzamy krawędź
przeprowadzamy krawędź 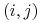 , o ile
, o ile 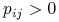 , a jeśli
, a jeśli 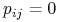 , to takiej krawędzi nie ma;
, to takiej krawędzi nie ma; -
zbudowanej krawędzi
nadajemy wagę 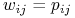 .
.
Zaprezentujemy teraz macierze przejścia i grafy przejścia, por. rys. 9.1, odpowiadające wymienionym w przykładach łańcuchom: rzutowi monetą i rosyjskiej ruletce w wersji II.

Macierz przejścia ![]() odzwierciedla dynamikę łańcucha w jednym kroku, natomiast my jak zwykle chcemy zbadać, co będzie się działo asymptotycznie, czyli czego możemy się spodziewać, jeśli będziemy nasze doświadczenia powtarzać dostatecznie długo. Do tego celu musimy obliczyć prawdopodobieństwa przejścia wyższego rzędu, czyli
odzwierciedla dynamikę łańcucha w jednym kroku, natomiast my jak zwykle chcemy zbadać, co będzie się działo asymptotycznie, czyli czego możemy się spodziewać, jeśli będziemy nasze doświadczenia powtarzać dostatecznie długo. Do tego celu musimy obliczyć prawdopodobieństwa przejścia wyższego rzędu, czyli ![]() , które opisuje przejście ze stanu
, które opisuje przejście ze stanu ![]() do stanu
do stanu ![]() w
w ![]() krokach, czyli po wykonaniu
krokach, czyli po wykonaniu ![]() prób. Mamy więc
prób. Mamy więc ![]() .
Zgodnie ze wzorem na prawdopodobieństwo całkowite dla
.
Zgodnie ze wzorem na prawdopodobieństwo całkowite dla ![]() otrzymujemy
otrzymujemy
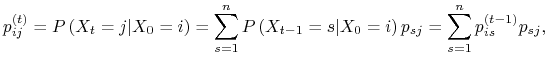 |
czyli rekurencyjną zależność ![]() od prawdopodobieństw niższego rzędu
od prawdopodobieństw niższego rzędu ![]() . Stąd jeśli
. Stąd jeśli ![]() jest macierzą przejścia wyższego rzędu, to dostajemy zależność
jest macierzą przejścia wyższego rzędu, to dostajemy zależność
Wnioskujemy zatem, że rozkład łańcucha w dowolnym kroku jest jednoznacznie wyznaczony przez macierz przejścia i początkowy rozkład prawdopodobieństwa
![]() ,
, ![]() .
.
W kontekście opisywanych powyżej doświadczeń genetycznych chcemy poznać asymptotykę dwóch konkretnych typów łańcuchów Markowa. Zanim jednak przejdziemy do badania asymptotyki, podamy potrzebne definicje, w tym klasyfikację stanów łańcucha.
9.2. Klasyfikacja stanów i łańcuchów
Zaczniemy od podziału stanów łańcucha na pewne specjalne grupy.
Definicja 9.3
Stan ![]() nazwiemy nieistotnym, jeśli istnieje taki stan
nazwiemy nieistotnym, jeśli istnieje taki stan ![]() i liczba
i liczba ![]() , że
, że ![]() oraz
oraz ![]() dla dowolnego
dla dowolnego ![]() . W przypadku przeciwnym stan
. W przypadku przeciwnym stan ![]() nazywamy istotnym.
nazywamy istotnym.
Definicja 9.4
Stany istotne ![]() ,
, ![]() nazywamy komunikującymi się, jeśli istnieją takie
nazywamy komunikującymi się, jeśli istnieją takie ![]() ,
, ![]() , dla których
, dla których ![]() i
i ![]() .
.
Podzielmy teraz wszystkie stany danego łańcucha na podklasy: niech ![]() oznacza klasę wszystkich stanów nieistotnych, następnie wybierzmy jakikolwiek stan istotny
oznacza klasę wszystkich stanów nieistotnych, następnie wybierzmy jakikolwiek stan istotny ![]() i oznaczmy przez
i oznaczmy przez ![]() zbiór wszystkich stanów komunikujących się z
zbiór wszystkich stanów komunikujących się z ![]() . Ten zbiór stanów nazywa się także czasem zbiorem stochastycznie zamkniętym. W taki sposób podzielimy łańcuch na rozłączne klasy stanów komunikujących się
. Ten zbiór stanów nazywa się także czasem zbiorem stochastycznie zamkniętym. W taki sposób podzielimy łańcuch na rozłączne klasy stanów komunikujących się ![]() ,
, ![]() . Jeśli łańcuch znalazł się w pewnym momencie w stanie istotnym
. Jeśli łańcuch znalazł się w pewnym momencie w stanie istotnym ![]() , to już nigdy nie wyjdzie z odpowiadającej mu klasy.
, to już nigdy nie wyjdzie z odpowiadającej mu klasy.
Definicja 9.5
Jeśli klasa ![]() składa się z jednego stanu
składa się z jednego stanu ![]() , to taki stan nazywamy pochłaniającym (absorbującym).
, to taki stan nazywamy pochłaniającym (absorbującym).
Definicja 9.6
Łańcuch Markowa składający się z jednej klasy stanów istotnych komunikujących się nazywamy łańcuchem nieprzywiedlnym. Jeśli łańcuch zawiera więcej niż jedną klasę, to jest przywiedlny.
Badając łańcuch Markowa sprowadzamy najpierw jego macierz do postaci kanonicznej numerując stany w taki sposób, aby na początku znalazły się stany nieistotne, a następnie poszczególne stany z kolejnych klas. Macierz ma wtedy postać
![\mathbf{P}=\begin{array}[]{ccccc}&\mathcal{S}^{0}&\mathcal{S}^{1}&\mathcal{S}^{2}&\\
\mathcal{S}^{0}&\begin{array}[]{cc}\ldots&\ldots\\
\ldots&\ldots\end{array}&\begin{array}[]{cc}\ldots&\ldots\\
\ldots&\ldots\end{array}&\begin{array}[]{cc}\ldots&\ldots\\
\ldots&\ldots\end{array}&\begin{array}[]{cc}\ldots&\ldots\\
\ldots&\ldots\end{array}\\
\mathcal{S}^{1}&0&\begin{array}[]{cc}\vdots&\vdots\\
\vdots&\vdots\end{array}&0&0\\
\mathcal{S}^{2}&0&0&\begin{array}[]{cc}\vdots&\vdots\\
\vdots&\vdots\end{array}&0\\
\begin{array}[]{c}\vdots\\
\end{array}&&&&\\
\end{array},](wyklady/mbm/mi/mi769.png) |
a powstałe macierze ![\left(\begin{array}[]{cc}\vdots&\vdots\\
\vdots&\vdots\end{array}\right)](wyklady/mbm/mi/mi755.png) są macierzami stochastycznymi i każda z nich odpowiada łańcuchowi nieprzywiedlnemu.
są macierzami stochastycznymi i każda z nich odpowiada łańcuchowi nieprzywiedlnemu.
Oznaczmy
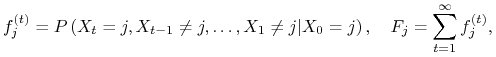 |
gdzie ![]() oznacza prawdopodobieństwo, że układ po wyjściu ze stanu
oznacza prawdopodobieństwo, że układ po wyjściu ze stanu ![]() wróci do tego stanu po raz pierwszy po
wróci do tego stanu po raz pierwszy po ![]() krokach, a
krokach, a ![]() to prawdopodobieństwo, że po wyjściu z tego stanu wróci do niego kiedykolwiek.
to prawdopodobieństwo, że po wyjściu z tego stanu wróci do niego kiedykolwiek.
– Stan ![]() nazywamy powracającym, jeśli
nazywamy powracającym, jeśli ![]() , natomiast niepowracającym, gdy
, natomiast niepowracającym, gdy ![]() .
.
– Stan ![]() nazywamy zerowym, jeśli
nazywamy zerowym, jeśli ![]() przy
przy ![]() .
.
– Stan ![]() nazywamy okresowym o okresie
nazywamy okresowym o okresie ![]() , jeśli powrót z dodatnim prawdopodobieństwem możliwy jest w liczbie kroków równej wielokrotności
, jeśli powrót z dodatnim prawdopodobieństwem możliwy jest w liczbie kroków równej wielokrotności ![]() i
i ![]() jest najmniejszą liczbą o tej własności (czyli
jest najmniejszą liczbą o tej własności (czyli ![]() jest NWD zbioru
jest NWD zbioru ![]() ).
).
– Stan powracający, niezerowy i nieokresowy nazywamy ergodycznym.
Wymienimy teraz dwa typy łańcuchów, które są istotne z punktu widzenia doświadczeń genetycznych, jakie za ich pomocą chcemy opisywać.
Definicja 9.7
Łańcuchem pochłaniającym (absorbującym) nazwiemy taki łańcuch przywiedlny, którego klasy stanów istotnych składają się z pojedynczych stanów pochłaniających.
Drugi typ stanowią oczywiście łańcuchy nieprzywiedlne.
Każdy typ łańcucha przywiedlnego możemy analizować korzystając z własności łańcuchów pochłaniających i łańcuchów nieprzywiedlnych. Dopóki łańcuch nie trafi do któregoś ze zbiorów ![]() ,
, ![]() , możemy traktować łańcuch jak łańcuch pochłaniający, natomiast jak już trafi do zbioru
, możemy traktować łańcuch jak łańcuch pochłaniający, natomiast jak już trafi do zbioru ![]() ,
, ![]() , to ten zbiór tworzy łańcuch nieprzywiedlny.
, to ten zbiór tworzy łańcuch nieprzywiedlny.
Wróćmy teraz do naszych prostych przykładów i spróbujmy w ich kontekście zastosować poznane definicje.
-
Rzut monetą: zauważmy, że prawdopodobieństwa przejścia z każdego z dwóch stanów łańcucha
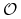 ,
, 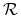 do każdego z nich jest zawsze równe , bez względu na stan w kroku poprzednim, zatem
do każdego z nich jest zawsze równe , bez względu na stan w kroku poprzednim, zatem 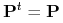 , czyli oba stany są istotne i komunikujące się, tworzą więc łańcuch nieprzywiedlny.
, czyli oba stany są istotne i komunikujące się, tworzą więc łańcuch nieprzywiedlny. -
Rosyjska ruletka II: stan
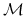 jest oczywiście pochłaniający, natomiast stan
jest oczywiście pochłaniający, natomiast stan 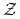 tworzy zbiór
tworzy zbiór 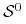 i jest stanem nieistotnym, ponieważ
i jest stanem nieistotnym, ponieważ 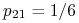 , natomiast
, natomiast 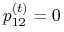 dla dowolnego
dla dowolnego  , gdyż
, gdyż  jest pochłaniający, czyli łańcuch ma własności wymienione w def. 9.7, zatem stanowi łańcuch pochłaniający.
jest pochłaniający, czyli łańcuch ma własności wymienione w def. 9.7, zatem stanowi łańcuch pochłaniający.
Zauważmy, że asymptotycznie te dwa typy łańcuchów (czyli nieprzywiedlny i pochłaniający) mają diametralnie różne własności. W łańcuchu nieprzywiedlnym każdy stan jest osiągany z dodatnim prawdopodobieństwem w dowolnej próbie, natomiast w łańcuchu pochłaniającym w pewnej próbie łańcuch wynosi
trafia do jakiegoś stanu pochłaniającego, z którego już nie wychodzi.
W przypadku rzutu monetą, ponieważ dla dowolnego
![]() zachodzi
zachodzi ![]() , więc bez względu na liczbę prób zawsze średnio dostajemy połowę orłów i połowę reszek. Z kolei w przypadku rosyjskiej ruletki prawdopodobieństwo pozostania
żywym maleje do
, więc bez względu na liczbę prób zawsze średnio dostajemy połowę orłów i połowę reszek. Z kolei w przypadku rosyjskiej ruletki prawdopodobieństwo pozostania
żywym maleje do ![]() wraz z rosnącą liczbą prób, co łatwo możemy bezpośrednio
obliczyć iterując macierz przejścia
wraz z rosnącą liczbą prób, co łatwo możemy bezpośrednio
obliczyć iterując macierz przejścia
![\mathbf{P}_{{\text{rr}}}^{t}=\left(\begin{array}[]{cc}1&0\\
1-\left(\tfrac{5}{6}\right)^{t}&\left(\tfrac{5}{6}\right)^{t}\end{array}\right).](wyklady/mbm/mi/mi743.png) |
Co ciekawe, oczekiwane liczba kroków przed absorpcją wynosi ![]() , czyli tyle, ile maksymalna liczba kroków możliwa w wersji I.
Wykażemy to poniżej.
, czyli tyle, ile maksymalna liczba kroków możliwa w wersji I.
Wykażemy to poniżej.


