Zagadnienia
12. Globalizacja zbieżności
Zarówno metoda Newtona, jak i omawiane przez nas jej modyfikacje, mogą zawieść (to znaczy: mogą nie być zbieżne lub dobrze określone), gdy początkowe przybliżenie ![]() będzie zbyt daleko od rozwiązania i założenia standardowe nie będą spełnione w
będzie zbyt daleko od rozwiązania i założenia standardowe nie będą spełnione w ![]() . Ponieważ zwykle trudno wiedzieć a priori, czy jesteśmy dostatecznie blisko rozwiązania, opracowano szereg mniej lub bardziej heurystycznych technik globalizacji zbieżności metod typu Newtona, pozwalających w końcu dotrzeć w takie pobliże rozwiązania, w którym już nastąpi szybka zbieżność.
. Ponieważ zwykle trudno wiedzieć a priori, czy jesteśmy dostatecznie blisko rozwiązania, opracowano szereg mniej lub bardziej heurystycznych technik globalizacji zbieżności metod typu Newtona, pozwalających w końcu dotrzeć w takie pobliże rozwiązania, w którym już nastąpi szybka zbieżność.
Podobny charakter ma inny — jakże często spotykany w zastosowaniach — problem: równanie nieliniowe z parametrem, w którym celem jest wyznaczenie nie jednego, jak dotychczas, ale całej rodziny rozwiązań (w zależności od parametru). Przykładowo, mogłaby nas interesować charakterystyka prądowo–napięciowa pewnego układu elektronicznego o nieliniowych własnościach: wtedy dla zadanych wartości napięcia musielibyśmy rozwiązać równanie nieliniowe, określające prąd w obwodzie. Ponieważ aby narysować dokładny wykres takiej charakterystyki, należałoby próbkować wartości natężenia w bardzo wielu (powiedzmy, kilkuset) podanych napięciach — dobrze byłoby te kilkaset układów równań rozwiązać możliwie efektywnie. Pokażemy więc pożyteczną metodę wyznaczania bardzo dobrych punktów startowych ![]() w przypadku, gdy zależność rozwiązania od parametru jest dostatecznie regularna.
w przypadku, gdy zależność rozwiązania od parametru jest dostatecznie regularna.
Co ciekawe, tę technikę można wykorzystać także w celu globalizacji zbieżności metody typu Newtona dla pojedynczego równania nieliniowego!
12.1. Metoda nawrotów
Przypomnijmy, że rozważane przez nas metody iteracyjne są postaci
Zacznijmy od prostej obserwacji, że — gdy ![]() jest daleko od rozwiązania — poprawka
jest daleko od rozwiązania — poprawka ![]() jest co prawda słuszna co do kierunku (idziemy wszak w stronę, w którą funkcja lokalnie maleje), ale być może przesadna co do wielkości i spowodować, że w następnej iteracji wartość residuum wzrośnie, a nie zmaleje…
jest co prawda słuszna co do kierunku (idziemy wszak w stronę, w którą funkcja lokalnie maleje), ale być może przesadna co do wielkości i spowodować, że w następnej iteracji wartość residuum wzrośnie, a nie zmaleje…
Metoda nawrotów (ang. backtracking) reprezentuje prostą strategię, polegającą na zachowaniu kierunku poprawki i następnie na ewentualnym jej skróceniu tak, by residuum w ![]() było mniejsze od residuum w
było mniejsze od residuum w ![]() : dzięki temu zawsze będziemy redukować
: dzięki temu zawsze będziemy redukować ![]() w nadziei, że tym samym będziemy zbliżać się do rozwiązania.
w nadziei, że tym samym będziemy zbliżać się do rozwiązania.
12.1.1. Prosta metoda nawrotów
W swojej najbardziej podstawowej (raczej nie stosowanej) postaci, metoda nawrotów wyznacza poprawkę ![]() następująco:
następująco:
Metoda nawrotów, wersja bazowa
| TEST: |
| if |
| |
| else begin |
| |
| goto TEST; |
| end |
W praktyce powyższe kryterium akceptacji poprawki ![]() może być zbyt łagodne i dlatego raczej stosuje się tzw. regułę Armijo:
może być zbyt łagodne i dlatego raczej stosuje się tzw. regułę Armijo:
Metoda nawrotów z regułą Armijo
| TEST: |
| if |
| |
| else begin |
| |
| goto TEST; |
| end |
Parametr relaksacyjny ![]() dobiera się na wyczucie, zwykle trochę poniżej jedności. Oczywiście, nie można dać się zwariować i stosować zbyt małych mnożników
dobiera się na wyczucie, zwykle trochę poniżej jedności. Oczywiście, nie można dać się zwariować i stosować zbyt małych mnożników ![]() , bo prowadziłoby to do stagnacji metody (lepiej potraktować to jako informację o kłopotach ze zbieżnością i następnie restartować metodę z zupełnie innym
, bo prowadziłoby to do stagnacji metody (lepiej potraktować to jako informację o kłopotach ze zbieżnością i następnie restartować metodę z zupełnie innym ![]() ).
).
Metoda nawrotów, jakkolwiek często istotnie poprawia charakter zbieżności metody Newtona, może także załamać się, gdy ![]() stanie się osobliwa. Nie musi także gwarantować zbieżności do prawdziwego rozwiązania, gdyż może zdarzyć się, że na przykład
stanie się osobliwa. Nie musi także gwarantować zbieżności do prawdziwego rozwiązania, gdyż może zdarzyć się, że na przykład
iteracje
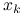 dążą do lokalnego ekstremum
dążą do lokalnego ekstremum 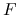 , a nie do miejsca zerowego;
, a nie do miejsca zerowego;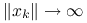 (bo na przykład
(bo na przykład 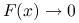 dla
dla 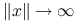 ).
).
12.1.2. Wielomianowe nawroty
Zamiast stosować dość prymitywną regułę wyznaczania nowego mnożnika poprawki: ![]() , można wybierać nowe
, można wybierać nowe ![]() jako argument minimalizujący wartość wielomianu interpolacyjnego dla funkcji
jako argument minimalizujący wartość wielomianu interpolacyjnego dla funkcji ![]() , opartego na węzłach będących poprzednio wybieranymi wartościami
, opartego na węzłach będących poprzednio wybieranymi wartościami ![]() . Taką strategię nazywa się strategią nawrotów wielomianowych. Inna metoda — obszaru ufności (ang. trust region) — pozwala dobrać nie tylko mnożnik poprawki, ale dodatkowo nieco zmienić jej kierunek; jest więc nieco bardziej elastyczna, ale za cenę wyższego kosztu.
. Taką strategię nazywa się strategią nawrotów wielomianowych. Inna metoda — obszaru ufności (ang. trust region) — pozwala dobrać nie tylko mnożnik poprawki, ale dodatkowo nieco zmienić jej kierunek; jest więc nieco bardziej elastyczna, ale za cenę wyższego kosztu.
Przykład 12.1 (Metoda wielomianowych nawrotów oparta na dwóch punktach)
Wybierając
po teście ![]() , dysponujemy następującymi trzema(!) wartościami
, dysponujemy następującymi trzema(!) wartościami ![]() :
:
Zauważmy, że jeśli ![]() było wyznaczone metodą Newtona, to wtedy faktycznie
było wyznaczone metodą Newtona, to wtedy faktycznie ![]() , a więc
, a więc ![]() maleje w kierunku
maleje w kierunku ![]() . Na podstawie tych trzech wartości możemy skonstruować wielomian interpolacyjny (Hermite'a) drugiego stopnia oraz wyznaczyć
. Na podstawie tych trzech wartości możemy skonstruować wielomian interpolacyjny (Hermite'a) drugiego stopnia oraz wyznaczyć ![]() , minimalizujące ten wielomian:
, minimalizujące ten wielomian:
Ćwiczenie 12.1
Wyprowadź powyższy wzór na ![]() .
.
Wspominany wielomian interpolacyjny Hermite'a dla ![]() to
to
Dla metody Broydena także można sformułować regułę podobną do reguły Armijo dla metody Newtona, [9].
Jeszcze innym sposobem globalizacji zbieżności metody Newtona może być wykorzystanie metody kontynuacji — o czym w następnym rozdziale.
12.2. Metody kontynuacji
W wielu praktycznych zastosowaniach mamy do czynienia nie z jednym równaniem nieliniowym, ale z całą rodziną równań, indeksowaną pewnym parametrem (lub zestawem parametrów). Dla ustalenia uwagi, rozważmy więc rodzinę równań indeksowaną parametrem ![]() ,
,
| (12.1) |
gdzie ![]() , gdzie
, gdzie ![]() jest otwartym niepustym podzbiorem
jest otwartym niepustym podzbiorem ![]() .
.
W ogólności zbiór wszystkich rozwiązań (12.1) może być dziwaczny, ale my zajmiemy się regularnym — spotykanym w niektórych zastosowaniach — przypadkiem, kiedy możemy lokalnie jednoznacznie określić funkcję ![]() taką, że
taką, że
Dokładniej, załóżmy, że ![]() i dla pewnego parametru
i dla pewnego parametru ![]() i dla pewnego
i dla pewnego ![]() zachodzi
zachodzi
Jeśli dodatkowo założymy, że pochodna cząstkowa ![]() jest nieosobliwa, to na mocy twierdzenia o funkcji uwikłanej istnieje
jest nieosobliwa, to na mocy twierdzenia o funkcji uwikłanej istnieje ![]() , gdzie
, gdzie ![]() , takie, że dla
, takie, że dla ![]() jest jednoznacznie wyznaczone rozwiązanie
jest jednoznacznie wyznaczone rozwiązanie ![]() ,
,
Ponadto, ![]() oraz
oraz
| (12.2) |
Mówimy w takim przypadku, że ![]() jest regularną gałęzią rozwiązań (12.1), przechodzącą przez
jest regularną gałęzią rozwiązań (12.1), przechodzącą przez ![]() . W dalszym ciągu zajmiemy się właśnie metodami wyznaczania takiej regularnej gałęzi rozwiązań.
. W dalszym ciągu zajmiemy się właśnie metodami wyznaczania takiej regularnej gałęzi rozwiązań.
12.2.1. Wyznaczanie dobrego przybliżenia początkowego dla metody typu Newtona
Przypuśćmy, że dla parametru ![]() wyznaczyliśmy już rozwiązanie
wyznaczyliśmy już rozwiązanie ![]() . Naszym zadaniem jest wyznaczenie
. Naszym zadaniem jest wyznaczenie ![]() , gdzie
, gdzie ![]() jest małe15W szczególności,
jest małe15W szczególności, ![]() .. Odpowiada to wziętej z życia sytuacji, gdy chcemy prześledzić przebieg gałęzi
.. Odpowiada to wziętej z życia sytuacji, gdy chcemy prześledzić przebieg gałęzi ![]() , próbkując jej wartości dla kolejnych (zapewne gęsto rozmieszczonych w
, próbkując jej wartości dla kolejnych (zapewne gęsto rozmieszczonych w ![]() ) wartości parametru
) wartości parametru ![]() .
.
Naturalnie, do wyznaczenia ![]() możemy użyć dowolnej z wcześniej opisywanych metod — ale czy nie udałoby się wykorzystać informacji uzyskanej dla
możemy użyć dowolnej z wcześniej opisywanych metod — ale czy nie udałoby się wykorzystać informacji uzyskanej dla ![]() w celu wyznaczenia przybliżenia
w celu wyznaczenia przybliżenia ![]() dla
dla ![]() tak, by metoda Newtona od razu startowała z dobrego przybliżenia początkowego? Ze względu na regularny charakter gałęzi
tak, by metoda Newtona od razu startowała z dobrego przybliżenia początkowego? Ze względu na regularny charakter gałęzi ![]() nietrudno zgadnąć, że niezłym przybliżeniem dla
nietrudno zgadnąć, że niezłym przybliżeniem dla ![]() mogłoby być
mogłoby być ![]() . Rzeczywiście, niech
. Rzeczywiście, niech
Wtedy (na mocy lematu o wartości średniej 9.1)
więc jeśli ![]() jest dostatecznie małe względem
jest dostatecznie małe względem ![]() , to
, to ![]() będzie dostatecznie blisko
będzie dostatecznie blisko ![]() , by zagwarantować szybką (kwadratową) zbieżność metody Newtona (pod oczywistym warunkiem, że spełnione są założenia standardowe, por. rozdział 9.3.1). Ten sposób wyboru
, by zagwarantować szybką (kwadratową) zbieżność metody Newtona (pod oczywistym warunkiem, że spełnione są założenia standardowe, por. rozdział 9.3.1). Ten sposób wyboru ![]() , zaproponowany przez Poincaré'go, nazywa się klasyczną metodą kontynuacji.
, zaproponowany przez Poincaré'go, nazywa się klasyczną metodą kontynuacji.
Można jednak, niewiele większym kosztem, uzyskać jeszcze lepsze przybliżenie początkowe dla metody Newtona (lub podobnej).
Ponieważ zachodzi (12.2) z warunkiem początkowym ![]() , to przybliżoną wartość
, to przybliżoną wartość ![]() możnaby uzyskać, stosując jakiś schemat różnicowy dla (12.2). Na przykład, korzystając dla (12.2) z jawnego schematu Eulera z krokiem
możnaby uzyskać, stosując jakiś schemat różnicowy dla (12.2). Na przykład, korzystając dla (12.2) z jawnego schematu Eulera z krokiem ![]() , jako
, jako ![]() położymy
położymy
Ten sposób wyznaczania początkowego przybliżenia ![]() nazywa się kontynuacją wzdłuż stycznej. Aby więc wyznaczyć
nazywa się kontynuacją wzdłuż stycznej. Aby więc wyznaczyć ![]() , musimy rozwiązać układ równań z macierzą pochodnej
, musimy rozwiązać układ równań z macierzą pochodnej ![]() (wyznaczoną dla poprzednio znalezionego rozwiązania — to przecież macierz występująca w iteracji Newtona!) no i wyznaczyć wartość
(wyznaczoną dla poprzednio znalezionego rozwiązania — to przecież macierz występująca w iteracji Newtona!) no i wyznaczyć wartość ![]() — co zwykle nie jest zbyt trudne analitycznie (w przeciwnym przypadku, możemy zadowolić się, jak zwykle, różnicową aproksymacją).
— co zwykle nie jest zbyt trudne analitycznie (w przeciwnym przypadku, możemy zadowolić się, jak zwykle, różnicową aproksymacją).
Jeśli ![]() , to jakość tak uzyskanego przybliżenia jest znacznie wyższa niż w przypadku klasycznej metody kontynuacji. Rzeczywiście,
, to jakość tak uzyskanego przybliżenia jest znacznie wyższa niż w przypadku klasycznej metody kontynuacji. Rzeczywiście,
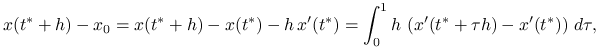 |
skąd, oznaczając ![]() , dostajemy na mocy lematu o wartości średniej oszacowanie
, dostajemy na mocy lematu o wartości średniej oszacowanie
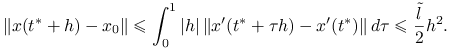 |
Ćwiczenie 12.2
Dlaczego w metodzie kontynuacji wzdłuż stycznej, zastosowanie schematu niejawnego do rozwiązywania (12.2) nie miałoby większego sensu?
Bo, po pierwsze, wymagałoby rozwiązania podobnego równania nieliniowego, a po drugie — byłoby niepotrzebnie kosztowne. Przecież nas i tak interesuje tylko wykonanie jednego kroku takiego schematu!
W świetle powyższego, nabiera znaczenia kwestia doboru właściwej wielkości kroku kontynuacji ![]() . Na razie dysponujemy jedynie informacją jakościową, że ,,dla
. Na razie dysponujemy jedynie informacją jakościową, że ,,dla ![]() dostatecznie małego”, dostaniemy zbieżność. Jednak w praktyce chcielibyśmy używać rozsądnie małych (czytaj: nie za małych)
dostatecznie małego”, dostaniemy zbieżność. Jednak w praktyce chcielibyśmy używać rozsądnie małych (czytaj: nie za małych) ![]() — bo obniża to koszt wyznaczenia aproksymacji
— bo obniża to koszt wyznaczenia aproksymacji ![]() dla
dla ![]() . Istnieją na szczęście strategie kontroli kroku kontynuacji
. Istnieją na szczęście strategie kontroli kroku kontynuacji ![]() [5], analogiczne jak w przypadku równań różniczkowych, ale dostosowane do tej konkretnej sytuacji: zagwarantowania (kwadratowej) zbieżności metody Newtona startującej z
[5], analogiczne jak w przypadku równań różniczkowych, ale dostosowane do tej konkretnej sytuacji: zagwarantowania (kwadratowej) zbieżności metody Newtona startującej z ![]() .
.
Warto także wiedzieć, że istnieją bardziej wyrafinowane techniki kontynuacji, które pozwalają przejść przez punkty krytyczne gałęzi (w których pochodna po ![]() jest nieokreślona)
jest nieokreślona)
12.2.2. Metoda homotopii
Jeśli trudno znaleźć dobry punkt startowy dla metody Newtona dla równania
możemy spróbować sztucznie wprowadzić parametr ![]() i określić równanie (12.1) tak, by
i określić równanie (12.1) tak, by
oraz
przy czym dla ![]() jesteśmy w stanie łatwo wygenerować dobry punkt startowy. Jeśli tak, to postępując zgodnie z metodą kontynuacji — rozwiązując
jesteśmy w stanie łatwo wygenerować dobry punkt startowy. Jeśli tak, to postępując zgodnie z metodą kontynuacji — rozwiązując ![]() dla kolejnych wartości
dla kolejnych wartości ![]() , poczynając od zera — dojdziemy w końcu do
, poczynając od zera — dojdziemy w końcu do ![]() , i tym samym wygenerujemy dlań dobre przybliżenie startowe.
, i tym samym wygenerujemy dlań dobre przybliżenie startowe.
Taka metoda globalizacji zbieżności metody Newtona — przez wykorzystanie kontynuacji dla odpowiednio spreparowanej rodziny zadań z parametrem — nosi nazwę metody homotopii, gdyż w sposób ciągły przeprowadzamy zadanie ,,łatwe” na zadanie ,,trudne”. Należy jednak pamiętać, że w praktyce ta metoda może, ale nie musi się sprawdzić, gdyż znalezienie dobrej homotopii ![]() może być sprawą znacznie trudniejszą niż znalezienie dobrego
może być sprawą znacznie trudniejszą niż znalezienie dobrego ![]() ! Zazwyczaj ,,naturalne” pomysły na
! Zazwyczaj ,,naturalne” pomysły na ![]() , np. wziąć ,,bardzo łatwą”
, np. wziąć ,,bardzo łatwą” ![]() i określić
i określić
albo położyć jeszcze prostszą
są zbyt proste, aby były skuteczne.


