Zagadnienia
10. Zadanie telekomunikacyjne
Rozważmy następujące zagadnienie, które pojawia się w analizie sieci
telekomunikacyjnych26Zadanie to przedstawił mi dr hab. Piotr Pokarowski z
Uniwersytetu Warszawskiego. Wiele podobnych przykładów Czytelnik znajdzie w
[28].. Otóż przypuśćmy, że mamy ![]() źródeł pakietów,
które podłączone są do routera, który składa się z systemu kolejkującego pakiety i procesora, który je przetwarza. Źródła mogą w danej chwili być albo włączone, albo wyłączone, a wysyłać pakiety mogą oczywiście tylko wtedy, gdy są włączone.
źródeł pakietów,
które podłączone są do routera, który składa się z systemu kolejkującego pakiety i procesora, który je przetwarza. Źródła mogą w danej chwili być albo włączone, albo wyłączone, a wysyłać pakiety mogą oczywiście tylko wtedy, gdy są włączone.
Przyjmujemy, że ![]() -te źródło przechodzi ze stanu wyłączonego w stan włączony ze średnią częstością
-te źródło przechodzi ze stanu wyłączonego w stan włączony ze średnią częstością ![]() , a ze stanu włączonego do wyłączonego — z częstością
, a ze stanu włączonego do wyłączonego — z częstością ![]() . Znaczy to na przykład, że średnio co
. Znaczy to na przykład, że średnio co ![]() jednostek czasu źródło, które jest wyłączone, przechodzi do stanu włączonego. Gdy
jednostek czasu źródło, które jest wyłączone, przechodzi do stanu włączonego. Gdy ![]() -te źródło jest włączone, może wysłać pakiet danych do routera, który je kolejkuje i następnie, jeden po drugim, przetwarza w procesie składającym się z
-te źródło jest włączone, może wysłać pakiet danych do routera, który je kolejkuje i następnie, jeden po drugim, przetwarza w procesie składającym się z ![]() etapów pośrednich.
etapów pośrednich.
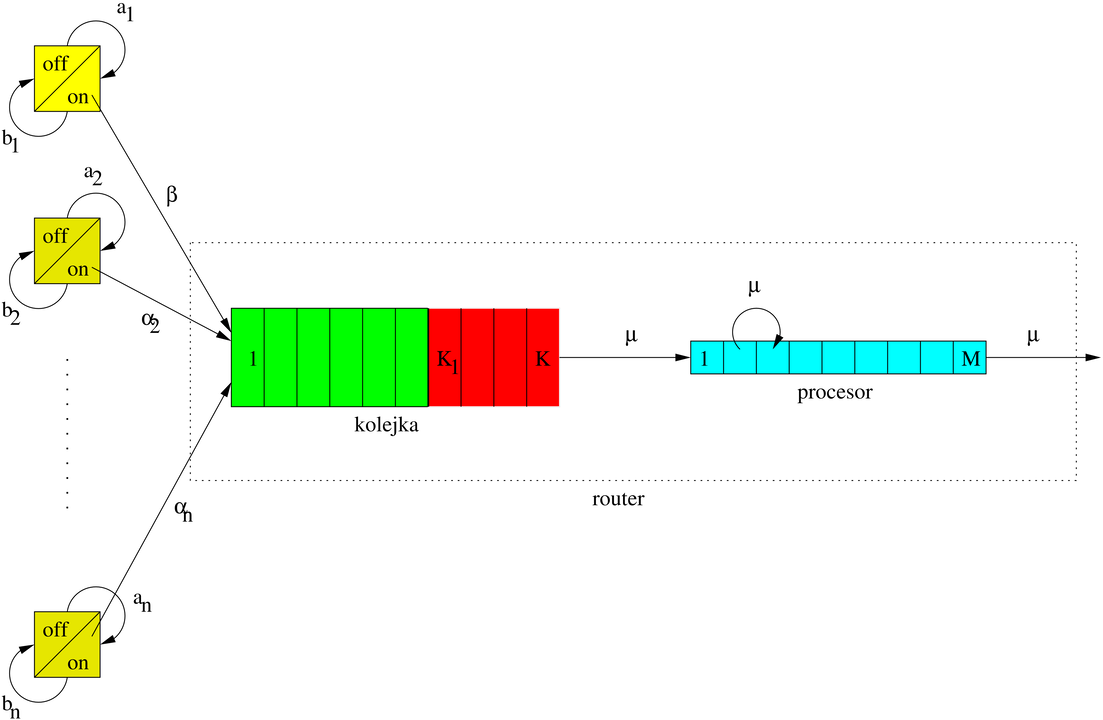
Zakładamy, że średnia szybkość przetwarzania pakietu w procesorze wynosi ![]() , czyli średnio co
, czyli średnio co ![]() jednostek czasu pakiet przechodzi do kolejnego etapu przetwarzania. Jeśli w procesorze nie ma pakietu, z tą samą częstością może zostać pobrany do przetwarzania nowy pakiet z kolejki.
jednostek czasu pakiet przechodzi do kolejnego etapu przetwarzania. Jeśli w procesorze nie ma pakietu, z tą samą częstością może zostać pobrany do przetwarzania nowy pakiet z kolejki.
Kolejka ma pojemność ![]() pakietów i jest typu FIFO (first in, first out). Nowe pakiety są wysyłane do kolejki z
pakietów i jest typu FIFO (first in, first out). Nowe pakiety są wysyłane do kolejki z ![]() -tego źródła z częstością
-tego źródła z częstością ![]() (pod naturalnym warunkiem, że jest ono włączone).
Dodatkowo przyjmujemy, że pierwsze źródło jest uprzywilejowane i gdy długość kolejki przekroczy pewien zadany próg
bezpieczeństwa
(pod naturalnym warunkiem, że jest ono włączone).
Dodatkowo przyjmujemy, że pierwsze źródło jest uprzywilejowane i gdy długość kolejki przekroczy pewien zadany próg
bezpieczeństwa ![]() , przyjmowane są pakiety tylko z pierwszego źródła: pakiety z pozostałych źródeł są tracone. Oczywiście, gdy kolejka jest pełna, pakiety ze wszystkich źródeł są odrzucane i tracone.
, przyjmowane są pakiety tylko z pierwszego źródła: pakiety z pozostałych źródeł są tracone. Oczywiście, gdy kolejka jest pełna, pakiety ze wszystkich źródeł są odrzucane i tracone.
Dla zmniejszenia liczby parametrów modelu przyjmiemy (niezbyt realistycznie), że ![]() oraz
oraz ![]() , natomiast
, natomiast ![]() oraz
oraz ![]() .
.
W danej chwili, stan takiego układu źródła–kolejka–router jest więc
charakteryzowany przez trójkę liczb naturalnych: ![]() , gdzie
, gdzie
-
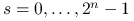 oznacza stan źródeł (każde ze źródeł może byc albo wyłączone (stan jednostkowy ,,0”) albo włączone (stan jednostkowy ,,1”); jeśli więc
oznacza stan źródeł (każde ze źródeł może byc albo wyłączone (stan jednostkowy ,,0”) albo włączone (stan jednostkowy ,,1”); jeśli więc 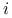 -te źródło jest w jednostkowym stanie
-te źródło jest w jednostkowym stanie 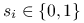 , to kładziemy
, to kładziemy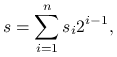
czyli
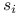 są cyframi zapisu
są cyframi zapisu 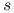 w układzie dwójkowym:
w układzie dwójkowym: 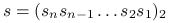 ;
; -
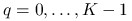 oznacza długość kolejki;
oznacza długość kolejki; -
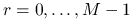 oznacza etap przetwarzania pakietu w
procesorze.
oznacza etap przetwarzania pakietu w
procesorze.
Alternatywnie, można byłoby rozpatrywać nie trójwymiarową, ale ![]() –wymiarową przestrzeń stanów, gdzie pierwsze
–wymiarową przestrzeń stanów, gdzie pierwsze ![]() stanów mogłoby przyjmować tylko wartości
stanów mogłoby przyjmować tylko wartości ![]() albo
albo ![]() . Numerując wszystkie
. Numerując wszystkie ![]() stanów możemy utworzyć macierz przejścia
stanów możemy utworzyć macierz przejścia ![]() , w której element
, w której element ![]() odpowiada częstości przejścia ze stanu
odpowiada częstości przejścia ze stanu ![]() do stanu
do stanu ![]() ; ponadto kładziemy
; ponadto kładziemy ![]() . Przyjmując, że modelowany przez nas układ ,,nie ma pamięci”, to znaczy: stan chwili następnej zależy jedynie od stanu w chwili bieżącej, konkludujemy, że mamy do czynienia z łańcuchem Markowa z ciągłym czasem i dyskretną przestrzenią stanów.
. Przyjmując, że modelowany przez nas układ ,,nie ma pamięci”, to znaczy: stan chwili następnej zależy jedynie od stanu w chwili bieżącej, konkludujemy, że mamy do czynienia z łańcuchem Markowa z ciągłym czasem i dyskretną przestrzenią stanów.
Zgodnie z regułami omówionymi na początku, mogą zajść następujące zdarzenia:
-
któreś ze źródeł się włączy lub wyłączy,
-
kolejka powiększy się o kolejny pakiet,
-
zostanie ukończony kolejny etap przetwarzania pakietu w procesorze,
-
procesor pobierze z kolejki nowy pakiet.
W naszym modelu założymy, że w jednej chwili możliwe jest wystąpienie tylko jednego z nich.
Zatem jeśli zmiana stanu dotyczy źródeł, to w danym momencie może zmienić się stan tylko jednego z nich: albo przestanie nadawać, albo przestanie wysyłać (ewentualnie nie zmieni stanu). Dlatego jeśli w zapisie binarnym ![]() , to
, to ![]() może przyjąć tylko takie nowe wartości, które różnią się dokładnie jedną cyfrą zapisu binarnego.
może przyjąć tylko takie nowe wartości, które różnią się dokładnie jedną cyfrą zapisu binarnego.
Dalej, może zwiększyć się długość kolejki. Jeśli jest włączonych ![]() źródeł, w tym uprzywilejowane, to długości kolejki wzrośnie o 1 z częstością
źródeł, w tym uprzywilejowane, to długości kolejki wzrośnie o 1 z częstością ![]() (o ile nie są przekroczone wartości graniczne, o których była mowa na samym początku). Oznacza to przejście ze stanu
(o ile nie są przekroczone wartości graniczne, o których była mowa na samym początku). Oznacza to przejście ze stanu ![]() do stanu
do stanu ![]() ze wspomnianą wyżej częstością. Gdy kolejka przekroczy długość
ze wspomnianą wyżej częstością. Gdy kolejka przekroczy długość ![]() , wtedy dopuszczane są tylko pakiety ze źródła uprzywilejowanego: gdy jest ono włączone, długości kolejki wzrośnie o 1 z częstością
, wtedy dopuszczane są tylko pakiety ze źródła uprzywilejowanego: gdy jest ono włączone, długości kolejki wzrośnie o 1 z częstością ![]() .
.
W końcu, stan może zmienić się wskutek przetworzenia pakietu przez procesor. Jeśli router wypuści pakiet na zewnątrz, układ przechodzi ze stanu ![]() do stanu
do stanu ![]() . Jeśli router jest wolny (czyli już jest w stanie
. Jeśli router jest wolny (czyli już jest w stanie ![]() ), z kolejki może zostać pobrany nowy pakiet (czyli przejdziemy do stanu
), z kolejki może zostać pobrany nowy pakiet (czyli przejdziemy do stanu ![]() ; jeśli kolejka jest pusta, nie stanie się nic). Wreszcie, pakiet przetwarzany przez procesor może przesunąć się do kolejnego etapu przetwarzania, to znaczy — do stanu
; jeśli kolejka jest pusta, nie stanie się nic). Wreszcie, pakiet przetwarzany przez procesor może przesunąć się do kolejnego etapu przetwarzania, to znaczy — do stanu ![]() . Wszystkie te zależne od procesora zmiany stanu odbywają się z częstością
. Wszystkie te zależne od procesora zmiany stanu odbywają się z częstością ![]() .
.
W zastosowaniach interesujący jest stan stacjonarny ![]() naszego łańcucha, to znaczy stan, w jakim powinien ustabilizować się nasz układ
po bardzo długim czasie. Współrzędna
naszego łańcucha, to znaczy stan, w jakim powinien ustabilizować się nasz układ
po bardzo długim czasie. Współrzędna ![]() odpowiada średniemu procentowi
czasu, w którym nasz system znajduje się w stanie o numerze
odpowiada średniemu procentowi
czasu, w którym nasz system znajduje się w stanie o numerze ![]() . Możemy więc
być zainteresowani takim doborem parametrów sieci (tzn. częstości lub
np. długości kolejki), by np. nie tracić (średnio) zbyt wielu pakietów.
Stan stacjonarny
. Możemy więc
być zainteresowani takim doborem parametrów sieci (tzn. częstości lub
np. długości kolejki), by np. nie tracić (średnio) zbyt wielu pakietów.
Stan stacjonarny ![]() jest dany równaniem [28]
jest dany równaniem [28]
| (10.1) |
przy czym ![]() oraz
oraz ![]() .
.
I to jest właśnie zadanie z jakim się zmierzymy: spróbujemy znaleźć wektor ![]() , spełniający (10.1).
, spełniający (10.1).
10.1. Konstrukcja macierzy przejścia
Jak widzieliśmy powyżej, w naszym przypadku, z danego stanu
układ może przejść jedynie do kilku — dokładniej: do ![]() innych (lub pozostać w
stanie niezmienionym). Znaczy to, że macierz
innych (lub pozostać w
stanie niezmienionym). Znaczy to, że macierz ![]() jest silnie rozrzedzona, co oznacza, że musimy ją reprezentować w postaci macierzy rzadkiej.
jest silnie rozrzedzona, co oznacza, że musimy ją reprezentować w postaci macierzy rzadkiej.
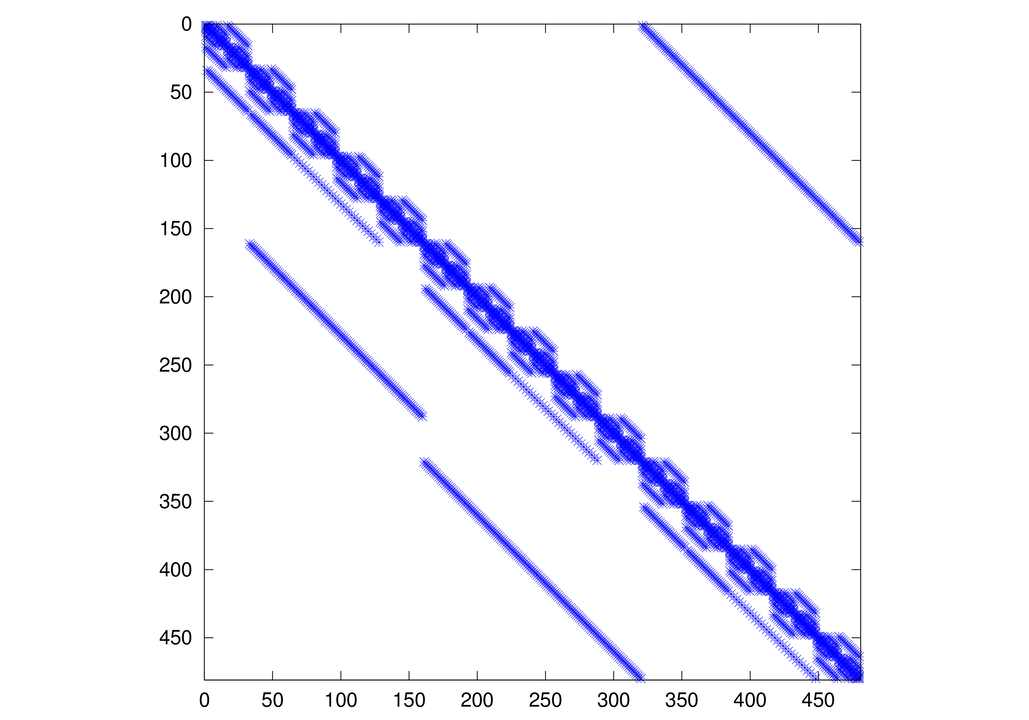
Wszystkich stanów jest ![]() i, aby skonstruować macierz
i, aby skonstruować macierz ![]() , musimy je najpierw ponumerować według jakiejś reguły27Wybór
reguły może mieć znaczenie dla efektywności działania metody rozwiązywania układu równań (10.1)!. Ale jak?
Narzuca się jedno z sześciu naturalnych rozwiązań28Na razie przyjmijmy, że
indeksujemy od zera.:
, musimy je najpierw ponumerować według jakiejś reguły27Wybór
reguły może mieć znaczenie dla efektywności działania metody rozwiązywania układu równań (10.1)!. Ale jak?
Narzuca się jedno z sześciu naturalnych rozwiązań28Na razie przyjmijmy, że
indeksujemy od zera.:
- sqr
-
- srq
-
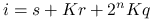
- rsq
-
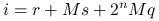
- rqs
-
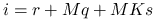
- qsr
-
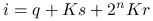
- qrs
-
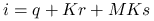
Pytanie o to, który z nich okaże się najlepszy (i czy możliwy jest jeszcze lepszy sposób) zostawimy na później. Na razie przyjmiemy wybór reguły silnych powiązań, dzięki czemu uzyskamy macierz o możliwie zagęszczonych wokół diagonali elementach. Ponieważ stany źródeł mogą zmieniać się aż na ![]() sposobów, wybierzemy je jako najszybciej zmieniającą się współrzędną trójki
sposobów, wybierzemy je jako najszybciej zmieniającą się współrzędną trójki ![]() i zdecydujemy się na zakodowanie numeru przez
i zdecydujemy się na zakodowanie numeru przez
W praktycznej implementacji będziemy musieli jeszcze pamiętać o tym, że w Octave i MATLABie elementy wektora musimy indeksować od ,,![]() ”, a w języku C — od ,,
”, a w języku C — od ,,![]() ”.
”.
10.1.1. Implementacja w małej skali: Octave
Jak widać z powyższego — i tak właśnie bardzo często zdarza się w najrozmaitszych zadaniach obliczeniowych matematyki stosowanej —
nasz probleme skaluje się, to znaczy można go postawić zarówno dla niewielkiej liczby niewiadomych (na przykład dla ![]() i
i ![]() ), jak też dla bardzo dużej liczby parametrów (wystarczy wziąć dostatecznie duże
), jak też dla bardzo dużej liczby parametrów (wystarczy wziąć dostatecznie duże ![]() : już dla
: już dla ![]() liczba samych stanów źródeł,
liczba samych stanów źródeł, ![]() , przekroczy możliwości adresowania współczesnych procesorów!).
, przekroczy możliwości adresowania współczesnych procesorów!).
Możemy więc na próbę, dla testów i wstępnych
obserwacji spróbować wykorzystać środowisko Octave dla małych ![]() . Utworzone przez nas narzędzia dla zadania małej skali mogą przydać się np, do pre- lub
postprocessingu danych lub wyników zadania w dużej skali.
. Utworzone przez nas narzędzia dla zadania małej skali mogą przydać się np, do pre- lub
postprocessingu danych lub wyników zadania w dużej skali.
Naszą macierz ![]() będziemy tworzyć wierszami, według schematu:
będziemy tworzyć wierszami, według schematu:
for r=0:M-1 for q = 0:K-1 for s = 0:2^n-1 % wyznacz numer stanu i odpowiadający trójce (s,q,r) % wyznacz częstości w_ij przejścia od stanu i=(s,q,r) do innego stanu j end end end
Alternatywnie, moglibyśmy użyć jednej pętli po wszystkich numerach stanów:
for i=1:N % wyznacz trójkę (s,q,r) odpowiadającą stanowi i % wyznacz częstości przejścia od stanu (s,q,r) do innego stanu j end
Będzie więc nam potrzebna funkcja, która danemu stanowi, reprezentowanemu przez trójkę ![]() , przyporządkowuje jego numer kolejny, na przykład
, przyporządkowuje jego numer kolejny, na przykład
function i = triple2state(x,z,p) % nadaje numer "i" stanowi reprezentowanemu trojka [x(1),x(2),x(3)] % zakladamy, ze x(1) = 0..2^n-1, x(2) = 0..K-1, x(3) = 0..M-1, % gdzie z = [2^n K M] % p jest sposobem numerowania, np. aby dostac sposob "sqr", bierzemy p = [1 2 3], % dla sposobu "qrs" kladziemy p = [2 3 1], itp. % schemat "p(1)-p(2)-p(3)" i = 1 + x(p(1)) + z(p(1)) * ( x(p(2)) + z(p(2)) * x(p(3)) ); % stany powinnismy numerowac od jedynki, bo numer stanu % bedzie indeksem w macierzy! end
Ćwiczenie 10.1
Zaprogramuj w Octave funkcję odwrotną do triple2state, to znaczy — wyznaczającą trójkę ![]() na podstawie numeru stanu.
na podstawie numeru stanu.
Poniżej przykładowy kod.
function x = state2triple(k,z,p) % zamienia numer stanu k na trojke opisujaca stan, [x(1),x(2),x(3)] % zakladamy, ze x(1) = 0..2^n-1, x(2) = 0..K-1, x(3) = 0..M-1 % gdzie z = [2^n K M] x = [-1,-1,-1]; k = k-1; q = fix(k/z(p(1))); a = k - q*z(p(1)); c = fix(q/z(p(2))); b = q - c*z(p(2)); x(p) = [a,b,c]; end
10.1.1.1. Praca z numerami stanów źródeł
Ze względu na to, że stany kolejnych źródeł kodujemy ustawiając konkretne bity w liczbie ![]() , musimy nauczyć się pracować z pojedynczymi bitami w danej zmiennej całkowitoliczbowej. Poniżej przypomnijmy więc podstawowe informacje na ten temat:
, musimy nauczyć się pracować z pojedynczymi bitami w danej zmiennej całkowitoliczbowej. Poniżej przypomnijmy więc podstawowe informacje na ten temat:
- Sprawdzenie bitu
-
Aby sprawdzić, czy
-ty bit liczby 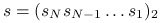 jest równy jeden, musimy wykonać bitową operację AND na i na
jest równy jeden, musimy wykonać bitową operację AND na i na 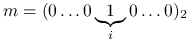 . Wynik nie jest zerem wtedy i tylko wtedy, gdy
. Wynik nie jest zerem wtedy i tylko wtedy, gdy 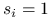 .
. - Zapalenie bitu
-
Aby ustawić wartość
-tego bitu liczby na 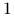 , należy wykonać bitową operację OR na i
, należy wykonać bitową operację OR na i 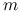 .
. - Zgaszenie bitu
-
Aby ustawić wartość
-tego bitu liczby na 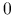 , należy wykonać bitową operację AND na i NOT , czyli na i na
, należy wykonać bitową operację AND na i NOT , czyli na i na 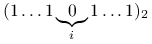 .
. - Przełączenie bitu
-
Aby zmienić wartość
-tego bitu liczby na inną (czyli z na i na odwrót, możemy wykorzystać gotowy operator w języku C, w przeciwnym razie musimy skorzystać z opisanych powyżej funkcji.
Wszystkie powyższe operacje można w prosty sposób przeprowadzić w języku C i w Octave/MATLABie, ale należy pamiętać, że w C bity indeksujemy od zera.
| Operacja na |
C ( |
Octave ( |
|---|---|---|
| Czy zapalony | z = s & (1<<i) |
z = bitget(s,i) |
| Zapalenie | S = s | (1<<i) |
S = bitset(s,i,1) |
| Zgaszenie | S = s & ~(1<<i) |
S = bitset(s,i,0) |
| Przełączenie | S = s ^ (1<<i) |
S = bitset(s,i,~bitget(s,i)) |
Znaczy to, że jeśli chcemy znaleźć wszystkie możliwe stany osiągalne z danego stanu ![]() i nadać wartości częstości przejścia źródeł ze stanu
i nadać wartości częstości przejścia źródeł ze stanu ![]() do nowego stanu, musimy wykonać pętlę
do nowego stanu, musimy wykonać pętlę
S = triple2state([s,q,r],z,ord); % numer biezacego stanu %%%%%%%% zmiana stanu z powodu zmiany stanu zrodla for i = 1:n bit = bitget(s,i); sn = bitset(s,i,~bit); % zmienia i-ty bit na przeciwny: to nowy numer stanu zrodla SN = triple2state([sn,q,r],z,ord); % numer nowego stanu zrodla if bit == 0 W(S,SN) = a; % przejscie od wylaczonego do wlaczonego else W(S,SN) = b; % przejscie od wlaczonego do wylaczonego end end
Z kolei zmianę stanu kolejki realizowałby następujący kod:
S = triple2state(s,q,r); % numer bieżącego stanu łańcucha %%%%%%%% zmiana stanu z powodu zmiany stanu kolejki if q < (K-1) % tylko wtedy mozna wydluzyc kolejke, w przeciwnym razie wszystkie pakiety sa odrzucane SN = triple2state([s,q+1,r],z,ord); % nowy stan: przyjeto pakiet do kolejki bs = bitsum(s); % ile jest wlaczonych b0 = bitget(s,1); % czy zerowy jest wlaczony if bs > 0 % cokolwiek nadaje W(S,SN) = 0; if b0 > 0 % specjalne traktowanie pierwszego zrodla W(S,SN) = beta; end if q < (K1-1) % pakiety z innych sa odrzucane jesli kolejka ma dlugosc K1 lub wieksza W(S,SN) = W(S,SN) + (bs-b0)*alpha; end end end
Wreszcie, może zmienić się stan procesora:
S = triple2state(s,q,r); % numer bieżącego stanu łańcucha %%%%%%%% zmiana stanu z powodu zmiany stanu procesora switch r case (M-1) SN = triple2state([s,q,0],z,ord); W(S,SN) = mu; case 0 if (q > 0) SN = triple2state([s,q-1,1],z,ord); W(S,SN) = mu; end otherwise SN = triple2state([s,q,r+1],z,ord); W(S,SN) = mu; end
Powyżej określone operacje traktowały ![]() jak macierz gęstą. W realnej implementacji wybierzemy format macierzy rzadkiej, dlatego ostateczna funkcja generująca macierz przejścia
jak macierz gęstą. W realnej implementacji wybierzemy format macierzy rzadkiej, dlatego ostateczna funkcja generująca macierz przejścia ![]() będzie postaci:
będzie postaci:
function spW = sptelecomtrans(n,K,M,K1,rate) % create (sparse) transition rate matrix spW % % queue length 0..K-1 % source states 0..2^n-1 % processing phases 0..M-1 % queue threshold K1 if nargin < 5 rate = [1 1 1 1 1]; end a = rate(1); % off -> on b = rate(2); % on -> off alpha = rate(3); % src -> queue beta = rate(4); % priority src -> queue mu = rate(5); % advance processing stage N = 2^n; z = [N, K, M]; ord = [1 2 3]; % fprintf(stderr,'Problem data:\nn=%d N=%d K=%d M=%d K1=%d\na=%g b=%g alpha=%g beta=%g mu=%g\n', n, N, K, M, K1, a, b, alpha, beta, mu); dim = triple2state(z-1,z,ord); % total dimension of W, dim = N*M*K nz = 0; % count nonzero elements of W % disp(['Constructing sparse matrix of size ', num2str(dim), ' and at most ', num2str(dim*(n+3)),' zeros']); IW = nan(dim*(n+3),1); % oszacowanie liczby elementow niezerowych JW = nan(size(IW)); VW = zeros(size(IW)); RW = zeros(dim,1); for s = 0:N-1 % stan zrodla for q = 0:K-1 % stan kolejki for r = 0:M-1 % stan procesora S = triple2state([s,q,r],z,ord); % numer biezacego stanu %%%%%%%% zmiana stanu z powodu zmiany stanu zrodla for i = 1:n bit = bitget(s,i); sn = bitset(s,i,~bit); % zmienia i-ty bit na przeciwny: to nowy numer stanu zrodla SN = triple2state([sn,q,r],z,ord); % numer nowego stanu zrodla nz = nz+1; IW(nz) = S; JW(nz) = SN; if bit == 0 % przejscie od wylaczonego do wlaczonego VW(nz) = a; RW(S) = RW(S) + a; else % przejscie od wlaczonego do wylaczonego VW(nz) = b; RW(S) = RW(S) + b; end end %%%%%%%% zmiana stanu z powodu zmiany stanu kolejki if q < (K-1) % tylko wtedy mozna wydluzyc kolejke, w przeciwnym razie wszystkie pakiety sa odrzucane SN = triple2state([s,q+1,r],z,ord); % nowy stan: przyjeto pakiet do kolejki bs = bitsum(s,n); % ile jest wlaczonych sposrod n mozliwych b0 = bitget(s,1); % czy zerowy jest wlaczony % fprintf(stderr,'s = %d bit = %d sum = %d\n',s,b0, bs); if bs > 0 % cokolwiek nadaje nz = nz+1; IW(nz) = S; JW(nz) = SN; VW(nz) = 0; if b0 > 0 % specjalne traktowanie pierwszego zrodla VW(nz) = beta; RW(S) = RW(S) + beta; end if q < (K1-1) % pakiety z innych sa odrzucane jesli kolejka ma dlugosc K1 lub wieksza VW(nz) = VW(nz) + (bs-b0)*alpha; RW(S) = RW(S) + (bs-b0)*alpha; end end end %%%%%%%% zmiana stanu z powodu zmiany stanu procesora switch r case (M-1) SN = triple2state([s,q,0],z,ord); nz = nz+1; IW(nz) = S; JW(nz) = SN; VW(nz) = mu; RW(S) = RW(S) + mu; case 0 if (q > 0) SN = triple2state([s,q-1,1],z,ord); nz = nz+1; IW(nz) = S; JW(nz) = SN; VW(nz) = mu; RW(S) = RW(S) + mu; end otherwise SN = triple2state([s,q,r+1],z,ord); nz = nz+1; IW(nz) = S; JW(nz) = SN; VW(nz) = mu; RW(S) = RW(S) + mu; end end % for... end % for... end % for... % suma wyrazow w wierszu: RW(i) = pstwo pozostania w stanie i % W + diag(RW) to macierz czestosci % konstrukcja macierzy prawdopodobienstw IW(nz+[1:dim]) = [1:dim]; JW(nz+[1:dim]) = [1:dim]; VW(nz+[1:dim]) = -RW; nz = nz + dim; disp([num2str(nz), ' nonzeros in the transition matrix']); spW = sparse(IW(1:nz),JW(1:nz),VW(1:nz),dim,dim); end % function function bs = bitsum(s,n) % wyznacza liczbe zapalonych bitow liczby s bs = sum(bitget(s,1:n)); end % function function info = isprobability(p) % sprawdza, czy 0 <= p <= 1 info = all(p >= 0) & all(p <= 1); if (~info) && (nargout < 1) warning([inputname(1), ' = [', num2str(p,' %g'), '] is not a probability']); end end % function
Dobrze, że zaczynamy od Octave; tu najprościej testować implementacje, np. moglibyśmy szybko na kilku przykładach sprawdzić, czy nasze procedury: przypisywania częstości przejścia oraz numerowania stanów działają poprawnie. Nie sposób przecenić czasu (i nerwów) jakie dzięki tym wstępnym testom można zaoszczędzić.
Ćwiczenie 10.2
Sprawdź na małych przykładach, czy otrzymujesz poprawne macierze przejścia. Na przykład29Doświadczenie uczy, że wykonanie tylko tego jednego testu to za mało, by wychwycić wszystkie dotąd popełnione pomyłki., dla ![]() i
i ![]() (co prawda nie można nadać im znaczenia częstości, ale to bez znaczenia dla testów) powinieneś otrzymać macierz
(co prawda nie można nadać im znaczenia częstości, ale to bez znaczenia dla testów) powinieneś otrzymać macierz
Pamiętaj, wyrazy na diagonali ![]() są określone zależnością
są określone zależnością ![]() !
!
10.2. Wyznaczenie stanu stacjonarnego
Wydaje się, że nasze zadanie polega na znalezieniu jądra macierzy ![]() , a następnie wyłuskaniu zeń (i unormowaniu) odpowiedniego wektora. Rzeczywiście, w Octave jest funkcja
, a następnie wyłuskaniu zeń (i unormowaniu) odpowiedniego wektora. Rzeczywiście, w Octave jest funkcja
W = sptelecomtrans(n,K,M,K1,[a,b,alpha,beta,mu]); X = null(W');
która wyznacza jądro zadanej macierzy. Jeśli więc jądro jest jednowymiarowe (tego nie wiemy), a wszystkie współrzędne są dodatnie (to musimy sprawdzić i ewentualnie sobie zagwarantować), to
X = X*sign(X(1)); % gwarancja znaku if all(X>0) % sprawdzenie dodatniości Pi = X/norm(X,1); else Pi = NaN(size(X)); end residW = norm(W'*Pi,Inf)
Niestety, wyznaczanie jądra macierzy generalnie przy dużych ![]() może być bardzo kosztowne obliczeniowo. W dodatku, jego implementacja w Octave wykorzystuje słuszną, ale drogą metodę rozkładu SVD macierzy. Dzięki temu, że
może być bardzo kosztowne obliczeniowo. W dodatku, jego implementacja w Octave wykorzystuje słuszną, ale drogą metodę rozkładu SVD macierzy. Dzięki temu, że ![]() jest rozrzedzona i ma kilka innych ciekawych matematycznych własności, będziemy mogli obejść to ograniczenie.
jest rozrzedzona i ma kilka innych ciekawych matematycznych własności, będziemy mogli obejść to ograniczenie.
Ćwiczenie 10.3
Zaimplementuj metodę rozwiązywania zadania wykorzystującą null i zbadaj, jakie maksymalnie mogą być ![]() dla których otrzymasz sensowne rozwiązanie w sensownym czasie.
dla których otrzymasz sensowne rozwiązanie w sensownym czasie.
Generalnie, wszystkie potrzebne komendy zostały wcześniej przedstawione, ale powinniśmy jeszcze zabezpieczyć się przed sytuacją, w której null zwróci więcej niż jeden wektor. Taką sytuację należy potraktować jako indykator, że zadanie nie jest dobrze postawione i zgłosić przynajmniej ostrzeżenie:
X = null(W');
if size(X,2) > 1
warning('Nonunique solution');
X = X(:,end); % wybieramy jakikolwiek (zwykle ostatni odpowiada wartosci szczegolnej najblizszej zera)
end
10.2.1. Wybór właściwej metody
Najwyższy czas, by sięgnąć do literatury. W monografii [28], dotyczącej numerycznego wyznaczania różnych cech — także stanów stacjonarnych — łańcuchów Markowa jest omówiona metoda, w której poprzez usunięcie jednego wiersza i jednej kolumny z macierzy ![]() można zadanie sprowadzić do zwykłego zadania rozwiązywania układu równań liniowych z macierzą nieosobliwą. Zapewne dla średnich rozmiarów macierzy
można zadanie sprowadzić do zwykłego zadania rozwiązywania układu równań liniowych z macierzą nieosobliwą. Zapewne dla średnich rozmiarów macierzy ![]() to byłaby całkiem dobra alternatywa — wszak
to byłaby całkiem dobra alternatywa — wszak ![]() jest macierzą rozrzedzoną i taką pozostanie po usunięciu wiersza i kolumny — ale musielibyśmy nieco obawiać się postępującego wypełnienia bloków czynników rozkładu LU macierzy.
jest macierzą rozrzedzoną i taką pozostanie po usunięciu wiersza i kolumny — ale musielibyśmy nieco obawiać się postępującego wypełnienia bloków czynników rozkładu LU macierzy.
Inny sposób podejścia do zadania wyznaczenia stanu stacjonarnego łańcucha Markowa (por. [27]) to wykonanie tzw. odwrotnej metody potęgowej na macierzy (raz tylko sfaktoryzowanej!) ![]() . Jest to metoda iteracyjna rozwiązywania zagadnienia własnego, której zasadniczym składnikiem jest wielokrotne rozwiązywanie układu równań postaci
. Jest to metoda iteracyjna rozwiązywania zagadnienia własnego, której zasadniczym składnikiem jest wielokrotne rozwiązywanie układu równań postaci ![]() . Aby więc metoda była efektywna, musimy umieć wyznaczyć rozkład macierzy
. Aby więc metoda była efektywna, musimy umieć wyznaczyć rozkład macierzy ![]() na prostsze składniki, najlepiej — wykorzystując fakt, że macierz
na prostsze składniki, najlepiej — wykorzystując fakt, że macierz ![]() jest mocno rozrzedzona. Więcej na temat metody potęgowej i odwrotnej metody potęgowej można przeczytać w wykładzie z Matematyki Obliczeniowej~II. Jednak w naszym przypadku domyślnie stosowana w Octave metoda rozkładu macierzy rozrzedzonych zabiera zbyt wiele czasu i jest mało efektywna, gdy
jest mocno rozrzedzona. Więcej na temat metody potęgowej i odwrotnej metody potęgowej można przeczytać w wykładzie z Matematyki Obliczeniowej~II. Jednak w naszym przypadku domyślnie stosowana w Octave metoda rozkładu macierzy rozrzedzonych zabiera zbyt wiele czasu i jest mało efektywna, gdy ![]() jest duże.
jest duże.
Na szczęście, jest jeszcze jedna droga, wykorzystująca dodatkowe właściwości naszego zadania. (Skąd my to znamy?…) Skoro mamy do czynienia z łańcuchem Markowa, to możemy zapisać zadanie w równoważnej postaci z macierzą stochastyczną30Czyli taką, której elementy są nieujemne i w każdej kolumnie sumują się do jedności. ![]() ,
,
gdzie ![]() , przy czym
, przy czym ![]() (dowód równoważności i stochastyczności
(dowód równoważności i stochastyczności ![]() zostawiamy Czytelnikowi jako niezobowiązujące ćwiczonko, zob. [27]). Zatem poszukiwany wektor
zostawiamy Czytelnikowi jako niezobowiązujące ćwiczonko, zob. [27]). Zatem poszukiwany wektor ![]() jest wektorem własnym macierzy (kolumnami) stochastycznej
jest wektorem własnym macierzy (kolumnami) stochastycznej ![]() , odpowiadającym wartości własnej równej
, odpowiadającym wartości własnej równej ![]() . Jest to znacząca informacja, gdyż to pociąga za sobą, że:
. Jest to znacząca informacja, gdyż to pociąga za sobą, że:
-
istnieje wektor własny odpowiadający wartości własnej
(rzeczywiście, lewostronny wektor własny dla to wektor  .
. -
wartość własna
jest dominującą wartością własną (rzeczywiście, 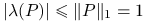 ) i nie ma innych wartości własnych o module równym (wynika to z twierdzenia Gerszgorina).
) i nie ma innych wartości własnych o module równym (wynika to z twierdzenia Gerszgorina).
Ponadto nasza macierz ![]() jest nieredukowalna (w języku łańcuchów Markowa, łańcuch jest nieprzywiedlny: każdy stan jest osiągalny z każdego innego, w skończonej liczbie kroków), więc na mocy twierdzenia Perrona–Frobeniusa [3, 28] wartość własna
jest nieredukowalna (w języku łańcuchów Markowa, łańcuch jest nieprzywiedlny: każdy stan jest osiągalny z każdego innego, w skończonej liczbie kroków), więc na mocy twierdzenia Perrona–Frobeniusa [3, 28] wartość własna ![]() macierzy
macierzy ![]() jest pojedyncza, a odpowiada jej wektor własny
jest pojedyncza, a odpowiada jej wektor własny ![]() o dodatnich współrzędnych.
o dodatnich współrzędnych.
Te wszystkie fakty oznaczają, że — zamiast kosztownego SVD — możemy spróbować użyć na przykład metody potęgowej wyznaczania dominującej wartości własnej macierzy ![]() !
!
Należy pamiętać, że metoda potęgowa, oprócz ewidentnej zalety (jest metodą iteracyjną, więc można obliczenia przerwać w bardziej dogodnym momencie, a iteracja opiera się na bardzo tanim mnożeniu, ![]() , przez macierz rozrzedzoną
, przez macierz rozrzedzoną ![]() ; ma też minimalne wymagania pamięciowe, co istotne przy dużych
; ma też minimalne wymagania pamięciowe, co istotne przy dużych ![]() ), ma też wady: jeśli druga co do wielkości wartość własna macierzy,
), ma też wady: jeśli druga co do wielkości wartość własna macierzy, ![]() , jest bliska dominującej —
, jest bliska dominującej — ![]() — zbieżność metody może być bardzo wolna.
— zbieżność metody może być bardzo wolna.
W Octave możemy wyznaczyć dominującą wartość własną na dwa sposoby: zaimplementować wprost metodę potęgową, albo wykorzystać funkcję eigs, wykorzystującą bardziej zaawansowane techniki wyznaczania ekstremalnych wartości własnych. Poniżej wybieramy właśnie ten drugi wariant:
opts.maxit = MAXIT; opts.tol = TOL; tic; [V, D, info] = eigs(spW, 6, 'lm', opts); toc D = diag(D); [m i] = max(abs(D)); if (abs(m-1) > 1e1*eps) warning(['Dominant eigenvalue = ', num2str(m, '%e'), ' not equal to 1. Difference: ', num2str(abs(m-1))]); end Pi = V(:,i); Pi = abs(Pi); % ustalamy znak Pi Pi = Pi/sum(Pi);
Pozostaje jeszcze przerobić macierz ![]() na macierz
na macierz ![]() ; w naszym przypadku zastąpimy funkcję
; w naszym przypadku zastąpimy funkcję W = sptelecomtrans(..) funkcją [P, W] = sptelecom(..), wyznaczającą przede wszystkim macierz ![]() , a macierz
, a macierz ![]() — tylko opcjonalnie.
— tylko opcjonalnie.
function [spP, spW] = sptelecom(n,K,M,K1,rate)
% create (sparse) transition probability matrix spP and (if requested)
% transition rate matrix spW
%
% queue length 0..K-1
% source states 0..2^n-1
% processing phases 0..M-1
% queue threshold K1
if nargin < 5
rate = [1 1 1 1 1];
end
a = rate(1); % off -> on
b = rate(2); % on -> off
alpha = rate(3); % src -> queue
beta = rate(4); % priority src -> queue
mu = rate(5); % advance processing stage
N = 2^n;
z = [N, K, M];
ord = [1 2 3];
% fprintf(stderr,'Problem data:\nn=%d N=%d K=%d M=%d K1=%d\na=%g b=%g alpha=%g beta=%g mu=%g\n', n, N, K, M, K1, a, b, alpha, beta, mu);
dim = triple2state(z-1,z,ord); % total dimension of W, dim = N*M*K
nz = 0; % count nonzero elements of W
% disp(['Constructing sparse matrix of size ', num2str(dim), ' and at most ', num2str(dim*(n+3)),' zeros']);
IW = nan(dim*(n+3),1); % oszacowanie liczby elementow niezerowych
JW = nan(size(IW));
VW = zeros(size(IW));
RW = zeros(dim,1);
for s = 0:N-1 % stan zrodla
for q = 0:K-1 % stan kolejki
for r = 0:M-1 % stan procesora
S = triple2state([s,q,r],z,ord); % numer biezacego stanu
%%%%%%%% zmiana stanu z powodu zmiany stanu zrodla
for i = 1:n
bit = bitget(s,i);
sn = bitset(s,i,~bit); % zmienia i-ty bit na przeciwny: to nowy numer stanu zrodla
SN = triple2state([sn,q,r],z,ord); % numer nowego stanu zrodla
nz = nz+1;
IW(nz) = S; JW(nz) = SN;
if bit == 0
% przejscie od wylaczonego do wlaczonego
VW(nz) = a;
RW(S) = RW(S) + a;
else
% przejscie od wlaczonego do wylaczonego
VW(nz) = b;
RW(S) = RW(S) + b;
end
end
%%%%%%%% zmiana stanu z powodu zmiany stanu kolejki
if q < (K-1) % tylko wtedy mozna wydluzyc kolejke, w przeciwnym razie wszystkie pakiety sa odrzucane
SN = triple2state([s,q+1,r],z,ord); % nowy stan: przyjeto pakiet do kolejki
bs = bitsum(s,n); % ile jest wlaczonych sposrod n mozliwych
b0 = bitget(s,1); % czy zerowy jest wlaczony
% fprintf(stderr,'s = %d bit = %d sum = %d\n',s,b0, bs);
if bs > 0 % cokolwiek nadaje
nz = nz+1;
IW(nz) = S; JW(nz) = SN;
VW(nz) = 0;
if b0 > 0 % specjalne traktowanie pierwszego zrodla
VW(nz) = beta;
RW(S) = RW(S) + beta;
end
if q < (K1-1) % pakiety z innych sa odrzucane jesli kolejka ma dlugosc K1 lub wieksza
VW(nz) = VW(nz) + (bs-b0)*alpha;
RW(S) = RW(S) + (bs-b0)*alpha;
end
end
end
%%%%%%%% zmiana stanu z powodu zmiany stanu procesora
switch r
case (M-1)
SN = triple2state([s,q,0],z,ord);
nz = nz+1;
IW(nz) = S; JW(nz) = SN;
VW(nz) = mu;
RW(S) = RW(S) + mu;
case 0
if (q > 0)
SN = triple2state([s,q-1,1],z,ord);
nz = nz+1;
IW(nz) = S; JW(nz) = SN;
VW(nz) = mu;
RW(S) = RW(S) + mu;
end
otherwise
SN = triple2state([s,q,r+1],z,ord);
nz = nz+1;
IW(nz) = S; JW(nz) = SN;
VW(nz) = mu;
RW(S) = RW(S) + mu;
end
end % for...
end % for...
end % for...
% suma wyrazow w wierszu: RW(i) = pstwo pozostania w stanie i
% W + diag(RW) to macierz czestosci
% konstrukcja macierzy prawdopodobienstw
deltaW = 0.99/max(abs(RW));
VW = VW*deltaW;
IW(nz+[1:dim]) = [1:dim];
JW(nz+[1:dim]) = [1:dim];
VW(nz+[1:dim]) = 1-RW*deltaW;
nz = nz + dim;
disp([num2str(nz), ' nonzeros in the probability matrix P']);
file=fopen('mout.dat','w');
fprintf(file, '%d %d %g\n', [JW(1:nz),IW(1:nz),VW(1:nz)]');
fclose(file);
spP = sparse(JW(1:nz),IW(1:nz),VW(1:nz),dim,dim);
% sprawdzmy, czy teraz W jest kolumnami stochastyczna
if (norm(spsum(spP,1)-1,Inf) > 10*eps) || any(spP(:) < 0) || any(spP(:) > 1)
warning('P may be not a Markov transition probability matrix');
end
if nargout > 1
VW = VW/deltaW; % niezbyt eleganckie
VW(nz-dim+1:nz) = -RW;
spW = sparse(IW(1:nz),JW(1:nz),VW(1:nz),dim,dim);
end
end % function
function bs = bitsum(s,n)
% wyznacza liczbe zapalonych bitow liczby s
bs = sum(bitget(s,1:n));
end % function
function info = isprobability(p)
% sprawdza, czy 0 <= p <= 1
info = all(p >= 0) & all(p <= 1);
if (~info) && (nargout < 1)
warning([inputname(1), ' = [', num2str(p,' %g'), '] is not a probability']);
end
end % function
Parametry zadania zapiszemy w prostym skrypcie Octave, o nazwie telecomparam.m:
a = 3.33; b = 3.52; alpha = 1; beta = 2; mu = 34e-1; % uwaga n = 13; K = 8; M = 5; K1 = 7; MAXIT = 100; TOL = 1e-6;
Aby wygenerować macierz ![]() , wystarczy więc wydać polecenia:
, wystarczy więc wydać polecenia:
telecomparam; P = sptelecom(n,K,M,K1,[a,b,alpha,beta,mu]);
10.3. Zadanie w dużej skali
Ponieważ liczba wszystkich stanów ![]() zależy eksponencjalnie od
zależy eksponencjalnie od ![]() , to gdy
, to gdy ![]() jest większe niż kilka, generowanie samej macierzy
jest większe niż kilka, generowanie samej macierzy ![]() w Octave będzie trwało potwornie wolno: z powodu konieczności zinterpretowania wielokrotnie zagnieżdżonych pętli.
w Octave będzie trwało potwornie wolno: z powodu konieczności zinterpretowania wielokrotnie zagnieżdżonych pętli.
Dlatego, aby móc prowadzić obliczenia dla dużych ![]() , powinniśmy przyspieszyć proces generowania macierzy
, powinniśmy przyspieszyć proces generowania macierzy ![]() , implementując procedurę na przykład w języku C.
, implementując procedurę na przykład w języku C.
10.3.1. Implementacja procedury generowania macierzy w C
W zasadzie wystarczy wprost przetłumaczyć tekst procedury z Octave na język C, pamiętając wszakże o następujących pułapkach, które czyhają na nas po drodze:
-
tablice w C indeksujemy od zera, dlatego
-
licznik
nzbędziemy inicjalizować na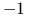 ,
, -
funkcja
triple2statebędzie zwracaćs+N*(q+K*r), a nie jak w Octave,1+s+N*(q+K*r),
-
-
bity w C numerujemy od zera, dlatego pętla po bitach źródeł powinna być dla
 :
: for (i = 0; i < n; i++), a bitem źródła uprzywilejowanego źródła jest bit zerowyb0 = bitget(s,0); funkcjabitget(s,i)powinna akceptować wartości; -
w kodzie zakładamy, że
bitget()zwraca zero lub 1, dlatego nie możemy użyć prostegos & (1<<i), które może zwracać wartości większe od 1;
Ponadto, nie będziemy już generować (niepotrzebnej w tej chwili) macierzy częstości ![]() , a tylko samą macierz
, a tylko samą macierz ![]() .
.
Warto zwrócić uwagę na fragment pozwalający prosto odczytać wszystkie parametry zadania zapisane w pliku Octave telecomparam.m.
Głównym celem programu sptelecom.c jest wyznaczenie macierzy rozrzedzonej ![]() w formacie współrzędnych i zapisanie jej do pliku (aby można było następnie wczytać ją do Octave i potraktować
w formacie współrzędnych i zapisanie jej do pliku (aby można było następnie wczytać ją do Octave i potraktować eigs).
Tu kryje się jeszcze jedna pułapka. Zapisując macierz w formacie tekstowym, ryzykujemy utratę dokładności reprezentacji wartości elementów macierzy ![]() . Dlatego, lepiej będzie zapisywać dane w formacie binarnym — i tak faktycznie zrobimy: patrz kod źródłowy programu w języku C.
. Dlatego, lepiej będzie zapisywać dane w formacie binarnym — i tak faktycznie zrobimy: patrz kod źródłowy programu w języku C.
/*
gcc -o sptelecom sptelecom.c -lm
time ./sptelecom < telecomparam.m
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define NPARAM 11 /* liczba parametrow do wczytania z pliku */
/* zmienne, do ktorych wczytamy parametry z pliku */
int n, N, K, M, K1;
double a, b, alpha, beta, mu;
int MAXIT; double TOL;
int triple2state(int s, int q, int r)
{
return(s+N*(q+K*r)); /* zero-based */
}
int bitget(int s, int i)
{
return( (s & (1<<i)) > 0 ); /* zwraca zero lub 1 */
}
int bitflip(int s, int i)
{
return( s ^ (1<<i) );
}
int bitsum(int s)
{
int bs = 0, i;
if (s <= 1)
return(s);
for (i=0; i < n; i++)
{
bs += bitget(s,i);
}
return(bs);
}
void multW(int *IW, int *JW, double *VW, double *X, double *Y, int dim, int nz)
{
/*
Mnozy macierz W (w formacie wspolrzednych IW,JW,VW) przez wektor X i wynik zapisuje do Y
*/
int i;
for(i = 0; i < dim; i++)
Y[i] = 0.0;
for(i = 0; i < nz; i++)
Y[IW[i]] += VW[i]*X[JW[i]];
}
int main(int argc, char **argv)
{
int s,q,r, S, SN, dim, nz, nnz, sn, bit, i;
int *IW, *JW;
double *VW, *RW;
double *X, *Y, nrm;
FILE *fp;
/* prymitywny lecz skuteczny sposob wczytania parametrow */
/*
#include "telecomparam.m"
*/
{
/* standardowe wczytanie parametrow */
char name[32];
double val;
double params[NPARAM];
char names[NPARAM][15] = {"n", "K", "M", "K1",
"a", "b", "alpha", "beta", "mu", "MAXIT", "TOL" };
int i,k;
for (i=0; i < NPARAM; i++)
params[i] = -1;
for (i=0; i < NPARAM; i++)
{
scanf("%s = %lf;%*[^\n]\n", name, &val);
fprintf(stderr, "\tReading: %g for %s\n", val, name);
for (k = 0; k < NPARAM; k++)
if (strcmp(name,names[k]) == 0)
{
params[k] = val;
break;
}
}
k = 1;
for (i=0; i < NPARAM; i++)
{
if (params[i] < 0)
{
k = -1;
fprintf(stderr, "Parameter '%s' not set\n", names[i]);
}
}
if (k == -1)
{
fprintf(stderr, "Exiting!\n");
exit(-1);
}
n = params[0];
K = params[1];
M = params[2];
K1 = params[3];
a = params[4];
b = params[5];
alpha = params[6];
beta = params[7];
mu = params[8];
MAXIT = params[9];
TOL = params[10];
}
if (argc > 1)
{
MAXIT = atoi(argv[1]);
fprintf(stderr, "\tChanging MAXIT to %d\n", MAXIT);
}
N = 1<<n;
fprintf(stderr,"Problem data:\nn=%d N=%d K=%d M=%d K1=%d\na=%g b=%g alpha=%g beta=%g mu=%g\n", n, N, K, M, K1, a, b, alpha, beta, mu);
dim = triple2state(N-1,K-1,M-1)+1;
nz = -1; /* indeks ostatnio dodanego niezerowego elementu macierzy W */
nnz = dim*(n+3); /* nieco przeszacowana maksymalna liczba niezerowych elementow w macierzy W */
fprintf(stderr,"Constructing sparse matrix of size %d and at most %d nonzeros.\n", dim, nnz);
IW = (int *)calloc(nnz, sizeof(int));
JW = (int *)calloc(nnz, sizeof(int));
VW = (double *)calloc(nnz, sizeof(double));
RW = (double *)calloc(dim, sizeof(double)); /* tablice wyzerowane! */
for (s = 0; s < N; s++) /* stan zrodla */
for (q = 0; q < K; q++) /* stan kolejki */
for (r = 0; r < M; r++) /* stan procesora */
{
S = triple2state(s,q,r); /* numer biezacego stanu */
/*
* zmiana stanu z powodu zmiany stanu zrodla
*/
for (i = 0; i < n; i++)
{
bit = bitget(s,i);
sn = bitflip(s,i); /* zmienia i-ty bit na przeciwny: to nowy numer stanu zrodla */
SN = triple2state(sn,q,r); /* numer nowego stanu zrodla */
nz++;
IW[nz] = S; JW[nz] = SN;
if (bit == 0)
{
/* przejscie od wylaczonego do wlaczonego */
VW[nz] = a;
RW[S] += a;
}
else
{
/* przejscie od wlaczonego do wylaczonego */
VW[nz] = b;
RW[S] += b;
}
}
/*
* zmiana stanu z powodu zmiany stanu kolejki
*/
if (q < (K-1)) /* tylko wtedy mozna wydluzyc kolejke, w przeciwnym razie wszystkie pakiety sa odrzucane */
{
int bs, b0;
SN = triple2state(s,q+1,r); /* nowy stan: przyjeto pakiet do kolejki */
bs = bitsum(s); /* ile jest wlaczonych */
b0 = bitget(s,0); /* czy zerowy jest wlaczony */
/* fprintf(stderr,"s = %d bit = %d sum = %d\n",s,b0, bs); */
if (bs > 0) /* cokolwiek nadaje */
{
nz++;
IW[nz] = S; JW[nz] = SN;
VW[nz] = 0;
if (b0 > 0) /* specjalne traktowanie pierwszego zrodla */
{
VW[nz] = beta;
RW[S] += beta;
}
if (q < (K1-1)) /* pakiety z innych sa odrzucane jesli kolejka ma dlugosc K1 lub wieksza */
{
VW[nz] += (bs-b0)*alpha;
RW[S] += (bs-b0)*alpha;
}
}
}
/*
* zmiana stanu z powodu zmiany stanu procesora
*/
if (r == (M-1))
{
SN = triple2state(s,q,0);
nz++;
IW[nz] = S; JW[nz] = SN;
VW[nz] = mu;
RW[S] += mu;
}
else if (r == 0)
{
if (q > 0)
{
SN = triple2state(s,q-1,1);
nz++;
IW[nz] = S; JW[nz] = SN;
VW[nz] = mu;
RW[S] += mu;
}
}
else
{
SN = triple2state(s,q,r+1);
nz++;
IW[nz] = S; JW[nz] = SN;
VW[nz] = mu;
RW[S] += mu;
}
}
nz++;
/*
suma wyrazow w wierszu: RW(i) = pstwo pozostania w stanie i
W + diag(RW) to macierz czestosci
konstrukcja macierzy prawdopodobienstw
*/
{
double deltaW = 0.0;
// max of RW
for (i = 0; i < dim; i++)
deltaW = (RW[i] > deltaW ? RW[i] : deltaW);
deltaW = 0.99/deltaW;
for (i = 0; i < nz; i++)
VW[i] *= deltaW;
for (i = 0; i < dim; i++)
{
IW[nz+i] = JW[nz+i] = i;
VW[nz+i] = 1.0-RW[i]*deltaW;
}
nz += dim;
}
free(RW);
fprintf(stderr, "%d nonzeros in the probability matrix\n", nz);
fp = fopen("cout.dat","wb"); /* zapis macierzy W w formacie binarnym, to wazne! */
fwrite(&nz, sizeof(int), 1, fp);
fwrite(JW, sizeof(int), nz, fp);
fwrite(IW, sizeof(int), nz, fp);
fwrite(VW, sizeof(double), nz, fp);
fclose(fp);
/*
metoda potegowa, tylko dla porownania z eigs z Octave
*/
X = (double *)calloc(dim, sizeof(double));
Y = (double *)calloc(dim, sizeof(double));
for (i = 0; i < dim; i++)
X[i] = 1.0/dim;
for (s = 0; s < MAXIT; s++)
{
multW(JW,IW,VW,X,Y,dim,nz);
multW(JW,IW,VW,Y,X,dim,nz);
nrm = 0.0;
for (i = 0; i < dim; i++)
{
double diff = fabs(Y[i]-X[i]);
nrm = (diff > nrm) ? diff : nrm;
}
if (nrm < TOL)
break;
}
fprintf(stderr,"Total %d iterations\n", s);
fp = fopen("coutx.dat","w"); /* wynik: wektor stanu stacjonarnego */
for(i = 0; i < dim; i++)
fprintf(fp, "%g\n", X[i]);
fclose(fp);
return(0);
}
10.3.2. Rozwiązanie zadania w Octave
Mając macierz ![]() w formacie współrzędnych, w postaci binarnej, musimy najpierw zmusić Octave do wczytania jej właśnie w tej postaci:
w formacie współrzędnych, w postaci binarnej, musimy najpierw zmusić Octave do wczytania jej właśnie w tej postaci:
function [spW, dim] = sptelecomload(filename) fp = fopen(filename,'rb'); nz = fread(fp, 1, 'int'); IJ = fread(fp, [nz,2], 'int'); IJ = IJ+1; % indeksy nie od zera, ale od 1 dim = max(IJ(:,1)); V = fread(fp, nz, 'double'); fclose(fp); spW = sparse(IJ(:,1), IJ(:,2), V, dim, dim); end
Teraz możemy już rozwiązać zadanie:
-
Wpisać poprawne wartości parametrów do pliku
telecomparam.m -
Wygenerować plik z macierzą
 :
:
make sptelecom ./sptelecom < telecomparam.m
-
Wyznaczyć wektor
 :
:
telecomparam; system ('make cout.dat'); [P, dim] = sptelecomload('cout.dat'); opts.maxit = MAXIT; opts.tol = TOL; tic; [V, D, info] = eigs(P, 2, 'lm', opts); toc D = diag(D); [m i] = max(abs(D)); if (abs(m-1) > 1e1*eps) warning(['Dominant eigenvalue = ', num2str(m, '%e'), ' not equal to 1. Difference: ', num2str(abs(m-1))]); end Pi = V(:,i); Pi = abs(Pi); Pi = Pi/sum(Pi); residP = norm(Pi-P*Pi,Inf) if (abs(residP) > 1e1*eps) warning(['Residual ||(P-I)*Pi|| = ', num2str(residP)]); end semilogy([0:K-1],sum(sum(reshape(Pi,[2^n,K,M]),3),1),'o-'); % semilogy([0:2^n-1],sum(sum(reshape(Pi,[2^n,K,M]),3),2),'o-'); file=fopen('moutx.dat','w'); fprintf(file, '%23.18e\n', Pi'); fclose(file);
Ponieważ Octave potrafi uruchamiać z poziomu sesji inne programy systemowe, wykorzystaliśmy to do automatycznego wygenerowania nowych danych, jak tylko zmieniły się parametry zapisane w pliku, lub zmianie uległ sam kod źródłowy.
Ćwiczenie 10.4
Która współrzędna ![]() jest największa, gdy
jest największa, gdy ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ? Sprawdź, jaki jest przewidywany procent czasu, w którym kolejka ma zadaną długość
? Sprawdź, jaki jest przewidywany procent czasu, w którym kolejka ma zadaną długość ![]() z przedziału
z przedziału ![]() . Z jakim prawdopodobieństwem będziemy tracić pakiety z nie-priorytetowych źródeł?
. Z jakim prawdopodobieństwem będziemy tracić pakiety z nie-priorytetowych źródeł?
semilogy([0:K-1],sum(sum(reshape(Pi,[2^n,K,M]),3),1),'o-');


