Zagadnienia
11. Równanie reakcji–dyfuzji
Ten wykład jest modyfikacją jednego z rozdziałów w [17], uwzględniającą demonstrację sposobu poprowadzenia wizualizacji rozwiązań.
Rozważmy proste nieliniowe zagadnienie ewolucyjne (zmienną ![]() będziemy interpretować jako czas), określone na prostokącie
będziemy interpretować jako czas), określone na prostokącie ![]() :
:
| (11.1) |
Niewiadomą jest funkcja ![]() . Zadana funkcja
. Zadana funkcja ![]() określa wartość rozwiązania w chwili początkowej
określa wartość rozwiązania w chwili początkowej ![]() . Symbolem
. Symbolem ![]() oznaczamy
dwuwymiarowy operator Laplace'a,
oznaczamy
dwuwymiarowy operator Laplace'a,
Równanie (11.1) nazywamy równaniem reakcji–dyfuzji, gdyż jeśli ![]() modelowałoby stężenie jakiejś substancji chemicznej, to
modelowałoby stężenie jakiejś substancji chemicznej, to ![]() byłoby jej współczynnikiem dyfuzji, a
byłoby jej współczynnikiem dyfuzji, a ![]() — członem odpowiedzialnym za szybkość reakcji chemicznej, zależną od wartości
— członem odpowiedzialnym za szybkość reakcji chemicznej, zależną od wartości ![]() . Dla ustalenia uwagi, przyjmiemy dalej, że
. Dla ustalenia uwagi, przyjmiemy dalej, że
Do rozwiązywania tego zadania zastosujemy tzw. metodę linii, w której (11.1) przybliżymy wielkim układem równań różniczkowych zwyczajnych względem czasu. Zaczniemy od samodzielnej dyskretyzacji
po zmiennych przestrzennych ![]() . Wybierzemy
tu najmniej efektywną, ale za to koncepcyjnie najprostszą metodę dyskretyzacji, opartą na równomiernej siatce węzłów
. Wybierzemy
tu najmniej efektywną, ale za to koncepcyjnie najprostszą metodę dyskretyzacji, opartą na równomiernej siatce węzłów
![]() . Przyjmiemy
. Przyjmiemy ![]() , gdzie
, gdzie ![]() jest krokiem siatki w kierunku
jest krokiem siatki w kierunku ![]() i analogicznie
i analogicznie ![]() .
.
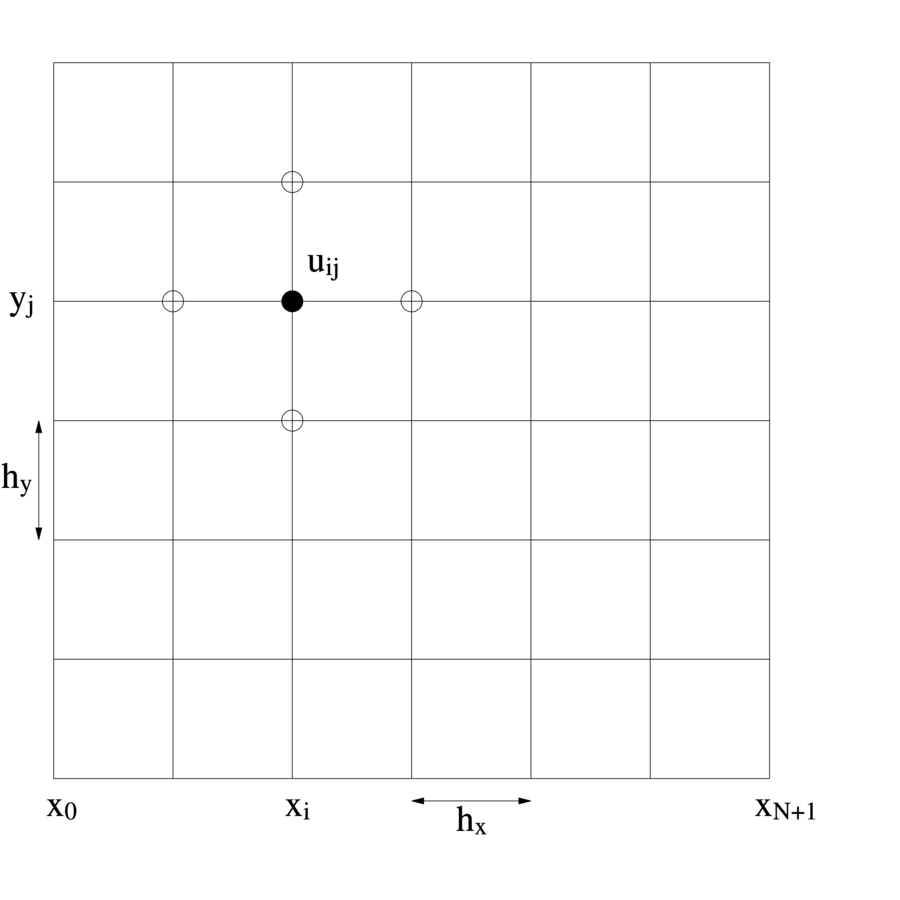
Oznaczając ![]() , a następnie
zastępując pochodne przestrzenne ilorazami różnicowymi [12]
, a następnie
zastępując pochodne przestrzenne ilorazami różnicowymi [12]
| (11.2) |
przybliżamy (11.1) układem równań różniczkowych zwyczajnych:
| (11.3) |
Macierz ![]() jest rozmiaru
jest rozmiaru ![]() o elementach będących
funkcjami czasu:
o elementach będących
funkcjami czasu: ![]() dla
dla ![]() ,
, ![]() , a operator
, a operator ![]() odpowiada macierzy dyskretnego dwuwymiarowego
laplasjanu (11.2). W węzłach brzegowych,
odpowiada macierzy dyskretnego dwuwymiarowego
laplasjanu (11.2). W węzłach brzegowych, ![]() jest oczywiście równe zero, z warunków zadania, więc nie musimy go wyznaczać.
jest oczywiście równe zero, z warunków zadania, więc nie musimy go wyznaczać.
Do uzyskanego układu równań różniczkowych zwyczajnych (11.3) nie możemy, z powodów natury praktycznej, zastosować wprost lsode. Rzeczywiście, otrzymany układ równań
zwyczajnych jest bardzo sztywny (im mniejsze ![]() , tym sztywniejszy układ!), a więc powinniśmy rozwiązywać go, korzystając ze schematu niejawnego. Jednak w przypadku schematu niejawnego ujawnia się kluczowy niedostatek
, tym sztywniejszy układ!), a więc powinniśmy rozwiązywać go, korzystając ze schematu niejawnego. Jednak w przypadku schematu niejawnego ujawnia się kluczowy niedostatek lsode: procedura DLSODE z biblioteki ODEPACK nie ma możliwości wykorzystania rozrzedzenia macierzy pochodnej i stosuje ,,w ciemno” solver dla macierzy gęstych, potężnie spowalniając działanie schematu niejawnego. Coś, co dotychczas było nieistotne (wcześniej rozważaliśmy układy co najwyżej kilku równań różniczkowych), w przypadku układu równań zwyczajnych (11.3), w którym mamy do czynienia z układem ![]() równań różniczkowych zwyczajnych, gdzie
równań różniczkowych zwyczajnych, gdzie
(przy czym rozsądne wartości zarówno ![]() , jak i
, jak i ![]() będą rzędu setek, a może nawet tysięcy), staje się ciężarem nie do udźwignięcia31Tak drastycznych ograniczeń nie mają funkcje MATLABa służące rozwiązywaniu sztywnych równań różniczkowych, np.
będą rzędu setek, a może nawet tysięcy), staje się ciężarem nie do udźwignięcia31Tak drastycznych ograniczeń nie mają funkcje MATLABa służące rozwiązywaniu sztywnych równań różniczkowych, np. ode15s — można (i trzeba!) wykorzystać tam rozrzedzenie macierzy pochodnej..
Oczywiście, alternatywnym rozwiązaniem mogłoby potencjalnie być zastosowanie schematu jawnego, w którym w ogóle nie trzeba rozwiązywać żadnych równań, ani liniowych, ani tym bardziej nieliniowych! Jednak niestety, także i ten pomysł nie jest zbyt rozsądny. Jak się okazuje na gruncie teorii [12], musielibyśmy wtedy użyć bardzo małej długości kroku czasowego ![]() , proporcjonalnego
do
, proporcjonalnego
do ![]() ! Dlatego, z wyjątkiem ekstremalnie krótkich czasów
! Dlatego, z wyjątkiem ekstremalnie krótkich czasów ![]() lub niewielkiego
lub niewielkiego ![]() (maksymalnie rzędu kilkuset), schemat jawny po prostu ,,zaliczy się”, zmuszony do wykonania bardzo wielu kroków czasowych.
(maksymalnie rzędu kilkuset), schemat jawny po prostu ,,zaliczy się”, zmuszony do wykonania bardzo wielu kroków czasowych.
11.1. Rozwiązanie numeryczne równania zdyskretyzowanego w przestrzeni
Do rozwiązania nieliniowego parabolicznego równań różniczkowego cząstkowego (11.1), a dokładniej — (11.3) — wykorzystania biblioteki CVODE. Biblioteka CVODE z pakietu SUNDIALS [30] to kolekcja narzędzi bardzo dobrej jakości służących do rozwiązywania dużych układów równań różniczkowych zwyczajnych. W szczególności, można ją także dostosować właśnie do rozwiązywania ewolucyjnych równań różniczkowych cząstkowych metodą linii.
CVODE jest rozwinięciem biblioteki LSODE z pakietu ODEPACK, używanej w Octave do rozwiązywania równań różniczkowych. Jednak w odróżnieniu od LSODE, dostajemy możliwość rozwiązywania naprawdę dużych układów równań metodami niejawnymi, gdyż do zadań zlinearyzowanych, jakie trzeba rozwiązywać na każdym kroku czasowym, biblioteka CVODE może użyć nie tylko standardowej eliminacji Gaussa, ale także metody iteracyjnej (np. GMRES) — również z wykorzystaniem zadanej przez użytkownika macierzy ściskającej (zob. wykład z Matematyki Obliczeniowej II. Drugie istotne rozszerzenie możliwości CVODE w stosunku do LSODE to możliwość pracy na komputerze wieloprocesorowym — lecz z niej nie będziemy tutaj korzystać.
Biblioteka CVODE jest bardzo dobrze udokumentowana, towarzyszy jej także zestaw przykładów wykorzystania jej możliwości. Właśnie najprostszym sposobem skorzystania z CVODE jest po prostu ostrożne i uważne zaadaptowanie przykładowego programu do własnych potrzeb.
Pierwszym krokiem powinno być ściągnięcie z internetu i zainstalowanie tej biblioteki w naszym systemie. W przypadku popularnych dystrybucji Linuxa będzie to bardzo proste, gdyż wystarczy zainstalować gotowy pakiet sundials (rzeczywiście, CVODE jest częścią większego pakietu, SUNDIALS). W przypadku bardziej egzotycznych systemów będziemy musieli samodzielnie skompilować kody źródłowe CVODE i następnie zainstalować w systemie. Na szczęście i ten proces jest szczegółowo opisany w podręczniku CVODE [2].
Poniżej pokazujemy zapis przykładowej instalacji biblioteki na oba sposoby.
Instalacja biblioteki Cvode z pakietu RPM w systemie Fedora Linux
Instalacja biblioteki Cvode w systemie Linux, wykorzystująca kody źródłowe. Procedura jest typowa dla instalacji innych bibliotek, których kod źródłowy pobraliśmy z internetu
Następnie, powinniśmy napisać program w języku C, który będzie rozwiązywać (11.3) z wykorzystaniem biblioteki CVODE. Typowy program wykorzystujący sekwencyjną wersję biblioteki CVODE ma mniej więcej następującą strukturę (por. podręcznik CVODE [2]):
/**************************************************
pliki nagłówkowe, w tym ---
dla funkcji biblioteki CVODE
**************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <cvode/cvode.h>
...itd...
/**************************************************
definicje niezbędnych makr i stałych
**************************************************/
#define T0 0.0 /* chwila początkowa */
#define TSTEP /* co jaki czas chcemy mieć rozwiązanie */
#define NSTEP /* ile takich rozwiązań? */
/* powyższe znaczy, że otrzymamy rozwiązania w chwilach T0 + i*TSTEP, i = 1..NSTEP */
#define RTOL RCONST(1.0e-5) /* parametr tolerancji błędu względnego */
#define ATOL RCONST(1.0e-6) /* parametr tolerancji błędu bezwzględnego */
#define NEQ (NX*NY) /* liczba równań w układzie, tutaj zadana jako $NX\cdot NY$ */
...itd...
/**************************************************
definicja struktury przechowującej dane,
jakie chcielibyśmy przekazywać do wewnątrz
solvera; przy rozsądnym wykorzystaniu zmiennych
globalnych i makrodefinicji, może być zbędna
**************************************************/
typedef struct {
realtype beta;
...inne obiekty...
} *UserData;
/**************************************************
prototypy najważniejszych funkcji
definiowanych przez użytkownika:
- prawej strony (F) i opcjonalnie:
- Jakobianu (DFxV),
- być może także preconditionera;
ich format jest szczegółowo wyspecyfikowany
w manualu.
**************************************************/
static int F(realtype t, N_Vector u, N_Vector udot, void *f_data);
static int DFxV(N_Vector V, N_Vector JV, realtype t,
N_Vector y, N_Vector fy, void *jac_data, N_Vector tmp);
/**************************************************
prototypy funkcji pomocniczych -
nazwy mówią same za siebie
**************************************************/
static UserData AllocUserData(void);
static void InitUserData(UserData data);
static void FreeUserData(UserData data);
static void SetInitialProfiles(N_Vector u);
static int PrintOutput(void *cvode_mem, N_Vector u, realtype t, int iout);
static void PrintFinalStats(void *cvode_mem);
...itd...
/* ewentualne zmienne globalne dla (nie)wygody programowania */
...definicje zmiennych globalnych...
/**************************************************
zaczyna się główny program
**************************************************/
int main(void)
{
/* KROK 0: niezbędne definicje zmiennych */
realtype abstol = ATOL; /* tolerancja błędu */
realtype reltol = RTOL;
realtype t, tout; /* obsługa czasu */
int iout;
UserData data = NULL; /* kontener na parametry użytkownika */
N_Vector U = NULL; /* tu znajdzie się rozwiązanie w chwili bieżącej */
void *cvode_mem = NULL; /* będzie wskazywać obszar roboczy dla CVODE */
/* KROK 1: alokacja i inicjalizacja danych użytkownika */
U = N_VNew_Serial(NEQ);
data = AllocUserData();
InitUserData(data);
SetInitialProfiles(U);
/* KROK 2: przygotowanie CVODE do pracy:
inicjalizacja obszarów roboczych, wybór parametrów solvera */
/* wybieramy opcje pracy solvera: schemat BDF;
równania nieliniowe będą rozwiązywane metodą Newtona */
cvode_mem = CVodeCreate(CV_BDF, CV_NEWTON);
CVodeSetFdata(cvode_mem, data);
/* uwaga: to tu podajemy chwilę początkową T0! */
CVodeMalloc(cvode_mem, f, T0, U, CV_SS, reltol, &abstol);
/* wybieramy solver iteracyjny (GMRES, bez macierzy ściskającej)
dla zadań zlinearyzowanych metodą Newtona */
CVSpgmr(cvode_mem, PREC_NONE, 20);
/* opcjonalnie - podajemy funkcję wyznaczającą Jakobian */
CVSpilsSetJacTimesVecFn(cvode_mem, DFxV, NULL);
/* KROK 3: wydruk warunku początkowego - nie zaszkodzi! */
iout = 0; tout = T0;
PrintOutput(cvode_mem, U, tout, iout);
/* KROK 4 (NAJWAŻNIEJSZY): rozwiązujemy równanie, a rozwiązania "drukujemy"! */
for (iout=1, tout = T0+TSTEP; iout <= NSTEP; iout++, tout += TSTEP)
{
flag = CVode(cvode_mem, tout, U, &t, CV_NORMAL);
PrintOutput(cvode_mem, U, t, iout);
/* zawsze sprawdzamy, czy ostatni cykl obliczeń zakończył się sukcesem */
if(check_flag(&flag, "CVode", 1)) break;
}
/* KROK 5: statystyki solvera i sprzątanie */
PrintFinalStats(cvode_mem);
N_VDestroy_Serial(U);
FreeUserData(data);
CVodeFree(&cvode_mem);
return(0);
}
Jak widzimy, nawet szkielet programu jest dość rozbudowany, a samo wywołanie biblioteki wymaga wielu przygotowań. Głównym zadaniem CVODE jest — mając zadaną funkcję prawej strony i dane początkowe — wyznaczyć wartość rozwiązania w danej chwili tout. Najważniejszą pętlą w powyższym kodzie jest więc
for (iout=1, tout = T0+TSTEP; iout <= NOUT; iout++, tout += TSTEP)
{
flag = CVode(cvode_mem, tout, U, &t, CV_NORMAL);
PrintOutput(cvode_mem, U, t, iout);
if(check_flag(&flag, "CVode", 1)) break;
}
w której funkcja CVode() wyznacza wartości rozwiązania w chwilach tout, powiększanych za każdym obrotem pętli o TSTEP. Oczywiście, nic nie stoi na przeszkodzie, by zamiast pętli for, wprowadzonej w celu wygenerowania rozwiązań w równych odstępach czasu, skorzystać np. z pętli while i w niej decydować według własnych reguł o tym, w jakich momentach należy wydobyć wartość rozwiązania podobnie, jak robiliśmy to w Octave.
CVODE może oczywiście mieć kłopoty z dotarciem do zadanego czasu tout (na przykład dlatego, że rozwiązanie wcześniej eksploduje…) — dlatego zmienna t zawiera faktyczny czas, do jakiego udało się dotrzeć funkcji CVode(); jeśli kod zakończenia funkcji, który zapisujemy do zmiennej flag, jest różny od zera, oznacza to wystąpienie kłopotów w pracy CVode() i, w naszym przypadku, jest powodem do przerwania obliczeń.
Szczęśliwie, nasza zadanie — równanie (11.3) — jest bardzo podobne do przykładowego zadania towarzyszącego dokumentacji CVODE [2], cvkryx.c — dlatego będziemy je rozwiązywać poprzez modyfikację tego pliku.
/* ====== Modyfikacja pliku examples/cvode/serial/cvkryx.c ======== */
/* ====== Modyfikacja pliku examples/cvode/serial/cvDiurnal_kry.c = */
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
#include <cvode/cvode.h> /* main integrator header file */
#include <cvode/cvode_spgmr.h> /* prototypes & constants for CVSPGMR solver */
#include <cvode/cvode_dense.h> /* prototypes & constants for CVDENSE solver */
#include <nvector/nvector_serial.h> /* serial N_Vector types, fct. and macros */
#include <sundials/sundials_types.h> /* definition of realtype */
#include <sundials/sundials_math.h> /* contains the macros ABS, SQR, and EXP */
#define OPENDX 0
#define PARAVIEW 1
#ifndef FORMAT
#define FORMAT OPENDX
#endif
#define BINARYOUT 1 /* czy wyniki w formacie binarnym (1) czy w tekstowym (0) */
#define ITLS 1 /* sposob rozwiazywania ukladow liniowych z Jakobianem;
ITLS == 0 ---> gesty solver;
ITLS > 0 ---> metoda iteracyjna */
#define USERJAC 1 /* czy jakobian dokladny (USERJAC > 0) czy aproksymowany automatycznie (USERJAC == 0) */
/* Problem Constants */
#define X 1.0 /* rozmiar obszaru */
#define Y 1.0
#define N 256 /* liczba wezlow w kierunku osi - liczba wierszy/kolumn w macierzy niewiadomych */
#define HX (X/(N+1)) /* krok siatki przestrzennej w kier. X */
#define HY (Y/(N+1)) /* krok siatki przestrzennej w kier. Y */
#define IHX (((N+1)/X)*((N+1)/X)) /* 1/krok siatki przestrzennej w kier. X do kwadratu */
#define IHY (((N+1)/Y)*((N+1)/Y)) /* 1/krok siatki przestrzennej w kier. Y do kwadratu */
#define NUM_SPECIES 1 /* niewiadome: temperatura */
#define BETA 5e-4
#define T0 0.0 /* initial time */
#define TMAX 15.0 /* final time */
#define NOUT 100 /* number of output times */
#define TSTEP ((TMAX-T0)/NOUT) /* output time interval */
/* CVodeMalloc Constants */
#define RTOL RCONST(1.0e-5) /* scalar relative tolerance */
#define FLOOR RCONST(0.1) /* value of C1 or C2 at which tolerances */
/* change from relative to absolute */
#define ATOL (RTOL*FLOOR) /* scalar absolute tolerance */
#define NEQ (N*N*NUM_SPECIES) /* NEQ = number of equations */
/*
Element U(i,j) macierzy U odpowiada u(x_i,y_j) - w ten sposob mamy
fizyczna odpowiedniosc wezlow siatki i elementow macierzy (transponowanej).
Wartosci rozwiazania na fizycznym brzegu obszaru sa rowne zero i nie sa uwzglednione w macierzy U; zawiera ona tylko niewiadome WEWNETRZNE.
Dostep do elementu U(i,j) daje makro IJth(DATA,i,j).
*/
/* makra dostepu do U jako macierzy */
#define IJth(a,i,j) (a[(j)-1 + ((i)-1)*N])
/* Type : UserData
contains preconditioner blocks, pivot arrays, and problem constants */
/* U nas ta struktura nie bedzie wykorzystywana */
typedef struct {
realtype param;
} *UserData;
/* Private Helper Functions */
static UserData AllocUserData(void);
static void InitUserData(UserData data);
static void FreeUserData(UserData data);
static void SetInitialProfiles(N_Vector u);
static int PrintOutput(void *cvode_mem, N_Vector u, realtype t, int iout);
static void PrintFinalStats(void *cvode_mem);
static int check_flag(void *flagvalue, char *funcname, int opt);
/* Functions Called by the Solver */
static int F(realtype t, N_Vector u, N_Vector udot, void *f_data);
static int AddLaplacian(realtype *U, realtype *LapU, realtype a);
static int DFxV(N_Vector v, N_Vector Jv, realtype t, N_Vector y, N_Vector fy, void *jac_data, N_Vector tmp);
FILE *outfile; /* uchwyt do pliku z wynikami */
int main(void)
{
realtype abstol, reltol, t, tout;
N_Vector U;
UserData data;
void *cvode_mem;
int iout, flag;
if( (BINARYOUT>0) && (FORMAT==PARAVIEW) )
{
fprintf(stderr, "Blad parametrow: BINARYOUT = %d, FORMAT = %d.\n",
BINARYOUT, FORMAT);
fprintf(stderr, "Zapis do pliku binarnego w formacie PARAVIEW nie jest wspierany!\n");
return(-2);
}
U = NULL;
data = NULL;
cvode_mem = NULL;
/* Allocate memory, and set problem data, initial values, tolerances */
U = N_VNew_Serial(NEQ);
if(check_flag((void *)U, "N_VNew_Serial", 0))
return(-1);
data = AllocUserData();
if(check_flag((void *)data, "AllocUserData", 2))
return(-1);
InitUserData(data);
SetInitialProfiles(U);
abstol=ATOL;
reltol=RTOL;
/* Call CvodeCreate to create the solver memory
CV_BDF specifies the Backward Differentiation Formula
CV_NEWTON specifies a Newton iteration
A pointer to the integrator memory is returned and stored in cvode_mem. */
cvode_mem = CVodeCreate(CV_BDF, CV_NEWTON);
if(check_flag((void *)cvode_mem, "CVodeCreate", 0))
return(-1);
CVodeSetMaxNumSteps(cvode_mem, 2000);
/* Set the pointer to user-defined data */
#if CVODE_VERSION == 230
flag = CVodeSetFdata(cvode_mem, data);
if(check_flag(&flag, "CVodeSetFdata", 1))
return(-1);
/* Call CVodeMalloc to initialize the integrator memory:
f is the user's right hand side function in u'=f(t,u)
T0 is the initial time
U is the initial dependent variable vector
CV_SS specifies scalar relative and absolute tolerances
reltol is the relative tolerance
&abstol is a pointer to the scalar absolute tolerance */
flag = CVodeMalloc(cvode_mem, F, T0, U, CV_SS, reltol, &abstol);
if(check_flag(&flag, "CVodeMalloc", 1))
return(-1);
#endif
#if CVODE_VERSION == 260
flag = CVodeSetUserData(cvode_mem, data);
if(check_flag(&flag, "CVodeSetUserData", 1)) return(-1);
/* Call CVodeInit to initialize the integrator memory and specify the
* user's right hand side function in u'=f(t,u), the inital time T0, and
* the initial dependent variable vector u. */
flag = CVodeInit(cvode_mem, F, T0, U);
if(check_flag(&flag, "CVodeInit", 1)) return(-1);
/* Call CVodeSStolerances to specify the scalar relative tolerance
* and scalar absolute tolerances */
flag = CVodeSStolerances(cvode_mem, reltol, abstol);
if (check_flag(&flag, "CVodeSStolerances", 1)) return(-1);
#endif
if (ITLS == 0)
{
/* Call CVDense for first-time debugging */
flag = CVDense(cvode_mem, NEQ);
if(check_flag(&flag, "CVDense", 1)) return(-1);
}
else
{
/* Call CVSpgmr to specify the linear solver CVSPGMR
with no preconditioning */
flag = CVSpgmr(cvode_mem, PREC_NONE, 10);
if(check_flag(&flag, "CVSpgmr", 1)) return(-1);
if(USERJAC > 0)
#if CVODE_VERSION == 230
CVSpilsSetJacTimesVecFn(cvode_mem, DFxV, NULL);
#endif
#if CVODE_VERSION == 260
CVSpilsSetJacTimesVecFn(cvode_mem, DFxV);
if(check_flag(&flag, "CVSpilsSetJacTimesVecFn", 1)) return(-1);
#endif
}
/* In loop over output points, call CVode, print results, test for error */
printf(" \nReakcja-dyfuzja\n\n");
if(FORMAT==OPENDX)
{
char basename[64];
char filename[64];
/* przygotowujemy plik z opisem danych .general */
sprintf(basename,"cvrd-N%d-rtol%e",N, RTOL);
strcpy(filename, basename);
strcat(filename, ".general");
outfile = fopen(filename, "w");
strcpy(filename, basename);
strcat(filename, ".out"); /* nazwa pliku z danymi */
fprintf(outfile, "file = %s\n", filename);
fprintf(outfile, "grid = %d x %d\n", N, N);
fprintf(outfile, "format = %s\n", BINARYOUT ? "lsb ieee" : "ascii");
fprintf(outfile, "interleaving = record\n");
fprintf(outfile, "majority = row\n");
fprintf(outfile, "series = %d, %f, %f\n", NOUT+1, (float)T0, (float)TMAX);
fprintf(outfile, "field = temperatura\n");
fprintf(outfile, "structure = scalar\n");
fprintf(outfile, "type = double\n");
fprintf(outfile, "dependency = positions\n");
fprintf(outfile, "positions = regular, regular, 0, %f, 0, %f\n", (float)HX, (float)HY);
fprintf(outfile, "\n");
fprintf(outfile, "end\n");
fclose(outfile);
/* otwieramy plik z wlasciwymi danymi .out */
outfile = fopen(filename, BINARYOUT ? "wb" : "w");
}
PrintOutput(cvode_mem, U, 0.0, 0);
for (iout=1, tout = TSTEP; iout <= NOUT; iout++, tout += TSTEP) {
flag = CVode(cvode_mem, tout, U, &t, CV_NORMAL);
PrintOutput(cvode_mem, U, t, iout);
if(check_flag(&flag, "CVode", 1)) break;
}
PrintFinalStats(cvode_mem);
if(FORMAT==OPENDX)
fclose(outfile);
/* Free memory */
N_VDestroy_Serial(U);
FreeUserData(data);
CVodeFree(&cvode_mem);
return(0);
}
/*
*-------------------------------
* Private helper functions
*-------------------------------
*/
/* Allocate memory for data structure of type UserData */
static UserData AllocUserData(void)
{
UserData data;
data = (UserData) malloc(sizeof *data);
return(data);
}
/* Load problem constants in data */
static void InitUserData(UserData data)
{
int i;
double s;
data->param = BETA;
}
/* Free data memory */
static void FreeUserData(UserData data)
{
free(data);
}
/* Set initial conditions in u */
static void SetInitialProfiles(N_Vector u)
{
realtype *udata, losU;
int i,j,k;
float x, y;
/* Set pointer to data array in vector u. */
udata = NV_DATA_S(u);
/* Load initial profiles of c1 and c2 into u vector */
/* randomize */
//srand( time(NULL) );
srand( 10 );
for (i = 1; i <= N; i++)
{
for (j = 1; j <= N; j++)
{
x = i*HX; y = j*HY;
losU = 2.0*rand()/(double)RAND_MAX - 1.0;
/****** temperatura */
IJth(udata, i,j) = (fmax(fabs(i-N/2),fabs(j-N/2))< N/8) ? 1.0 : losU-0.3;
IJth(udata, i,j) = (fmax(fabs(i-N/5),fabs(j-N/5))< N/8) ? 1.0 : IJth(udata, i,j);
IJth(udata, i,j) = 0.1*losU;
//if(j <= (N/2)) IJth(udata, i,j) -= 0.2;
IJth(udata, i,j) = 0.0;
if ((x >= X/4) && (x <= X/2) && (y >= Y/4) && (y <= 3*Y/4))
IJth(udata, i,j) = 1.0;
if ((x >= 4*X/12) && (x <= X/2) && (y >= Y/4) && (y <= Y/2))
IJth(udata, i,j) = -0.5;
if ((x >= 4*X/12) && (x <= 5*X/12) && (y >= 7*Y/12) && (y <= 8*Y/12))
IJth(udata, i,j) = -0.5;
if ((x >= 7*X/12) && (x <= 10*X/12) && (y >= Y/4) && (y <= 3*Y/4))
IJth(udata, i,j) = -1.0;
if ((x >= 8*X/12) && (x <= 10*X/12) && (y >= 4*Y/12) && (y <= 8*Y/12))
IJth(udata, i,j) = 0.6;
}
}
}
/* Print current t, step count, order, stepsize, and sampled c1,c2 values */
static int PrintOutput(void *cvode_mem, N_Vector u, realtype t, int iout)
{
long int nst;
int qu, flag, i,j,k;
realtype hu, *udata;
udata = NV_DATA_S(u);
flag = CVodeGetNumSteps(cvode_mem, &nst);
check_flag(&flag, "CVodeGetNumSteps", 1);
flag = CVodeGetLastOrder(cvode_mem, &qu);
check_flag(&flag, "CVodeGetLastOrder", 1);
flag = CVodeGetLastStep(cvode_mem, &hu);
check_flag(&flag, "CVodeGetLastStep", 1);
printf("t = %.2e | U(mid) = %12.3le\n", t, IJth(udata,N/2,N/2));
/* zapis wynikow do pliku outfile */
if(FORMAT==OPENDX)
/* zapisujemy wartosci "wierszami", to znaczy tak,
ze najszybciej zmienia sie wspolrzedna y;
wobec tego, w OpenDX wybieramy "majority = row" */
for(i = 1; i <= N; i++)
{
for( j = 1; j <= N; j++)
{
if(BINARYOUT)
fwrite(&IJth(udata,i,j), sizeof(realtype),
1, outfile);
else
fprintf(outfile, "%e ", IJth(udata,i,j));
}
if (!BINARYOUT)
fprintf(outfile, "\n");
}
if(FORMAT==PARAVIEW)
{
char filename[64];
sprintf(filename,"cvrd-N%d-rtol%e-step%d.vtk",N, RTOL, iout);
fprintf(stderr, "%s\n", filename);
outfile = fopen(filename, BINARYOUT ? "wb" : "w");
fprintf(outfile, "# vtk DataFile Version 3.0\n");
fprintf(outfile, "CVRD wyniki dla siatki %d x %d. Krok czasowy: %d/%d RTOL: %e\n", N, N, iout, NOUT, RTOL);
fprintf(outfile, BINARYOUT ? "BINARY\n" : "ASCII\n"); //BINARY nie dziala!
fprintf(outfile, "DATASET STRUCTURED_POINTS\n");
fprintf(outfile, "DIMENSIONS %d %d %d\n", N, N, 1);
fprintf(outfile, "ORIGIN %g %g %g\n", HX, HY, 0);
fprintf(outfile, "SPACING %g %g %g\n", HX, HY, 0.0);
fprintf(outfile, "POINT_DATA %d\n", N*N);
fprintf(outfile, "SCALARS Temperatura double\n");
fprintf(outfile, "LOOKUP_TABLE default\n");
/* paraview domyslnie zaklada column-major-order,
tzn. najszybciej zmienia sie pierwsza wspolrzedna siatki */
for( j = 1; j <= N; j++)
{
for(i = 1; i <= N; i++)
{
if(BINARYOUT)
fwrite(&IJth(udata,i,j), sizeof(realtype), 1, outfile);
else
fprintf(outfile, "%e\n", IJth(udata,i,j));
}
}
fclose(outfile);
}
return(0);
}
/* Get and print final statistics */
static void PrintFinalStats(void *cvode_mem)
{
long int lenrw, leniw ;
long int lenrwLS, leniwLS;
long int nst, nfe, nsetups, nni, ncfn, netf;
long int nli, npe, nps, ncfl, nfeLS;
int flag;
flag = CVodeGetWorkSpace(cvode_mem, &lenrw, &leniw);
check_flag(&flag, "CVodeGetWorkSpace", 1);
flag = CVodeGetNumSteps(cvode_mem, &nst);
check_flag(&flag, "CVodeGetNumSteps", 1);
flag = CVodeGetNumRhsEvals(cvode_mem, &nfe);
check_flag(&flag, "CVodeGetNumRhsEvals", 1);
flag = CVodeGetNumLinSolvSetups(cvode_mem, &nsetups);
check_flag(&flag, "CVodeGetNumLinSolvSetups", 1);
flag = CVodeGetNumErrTestFails(cvode_mem, &netf);
check_flag(&flag, "CVodeGetNumErrTestFails", 1);
flag = CVodeGetNumNonlinSolvIters(cvode_mem, &nni);
check_flag(&flag, "CVodeGetNumNonlinSolvIters", 1);
flag = CVodeGetNumNonlinSolvConvFails(cvode_mem, &ncfn);
check_flag(&flag, "CVodeGetNumNonlinSolvConvFails", 1);
flag = CVSpilsGetWorkSpace(cvode_mem, &lenrwLS, &leniwLS);
check_flag(&flag, "CVSpilsGetWorkSpace", 1);
flag = CVSpilsGetNumLinIters(cvode_mem, &nli);
check_flag(&flag, "CVSpilsGetNumLinIters", 1);
flag = CVSpilsGetNumPrecEvals(cvode_mem, &npe);
check_flag(&flag, "CVSpilsGetNumPrecEvals", 1);
flag = CVSpilsGetNumPrecSolves(cvode_mem, &nps);
check_flag(&flag, "CVSpilsGetNumPrecSolves", 1);
flag = CVSpilsGetNumConvFails(cvode_mem, &ncfl);
check_flag(&flag, "CVSpilsGetNumConvFails", 1);
flag = CVSpilsGetNumRhsEvals(cvode_mem, &nfeLS);
check_flag(&flag, "CVSpilsGetNumRhsEvals", 1);
printf("\nFinal Statistics.. \n\n");
printf("lenrw CVodeWorkSpace = %5ld leniw CVodeWorkSpace = %5ld\n", lenrw, leniw);
printf("lenrwLS CVSpilsWorkSpace = %5ld leniwLS CVSpilsWorkSpace = %5ld\n", lenrwLS, leniwLS);
printf("nst CVodeNumSteps = %5ld\n" , nst);
printf("nfe CVodeNumRhsEvals = %5ld nfeLS CVSpilsNumRhsEvals = %5ld\n" , nfe, nfeLS);
printf("nni CVodeNumNonlinSolvIters = %5ld nli CVSpilsNumLinIters = %5ld\n" , nni, nli);
printf("nsetups CVodeNumLinSolvSetups = %5ld netf CVodeNumErrTestFails = %5ld\n" , nsetups, netf);
printf("npe CVSpilsNumPrecEvals = %5ld nps CVSpilsNumPrecSolves = %5ld\n" , npe, nps);
printf("ncfn CVodeNumNonlinSolvConvFails = %5ld ncfl CVSpilsNumConvFails = %5ld\n\n", ncfn, ncfl);
( ITLS>0 ) ? printf("Metoda iteracyjna\n") : printf("Metoda bezposrednia\n");
( USERJAC>0 ) ? printf("Jakobian z funkcji\n") : printf("Jakobian z roznic dzielonych\n");
printf("Wyniki w pliku %s w formacie ", ( BINARYOUT>0 ) ? "binarnym" : "tekstowym");
switch(FORMAT)
{
case OPENDX:
printf("OpenDX\n"); break;
case PARAVIEW:
printf("ParaView\n"); break;
default:
printf("nieznanym\n");
}
}
/* Check function return value...
opt == 0 means SUNDIALS function allocates memory so check if
returned NULL pointer
opt == 1 means SUNDIALS function returns a flag so check if
flag >= 0
opt == 2 means function allocates memory so check if returned
NULL pointer */
static int check_flag(void *flagvalue, char *funcname, int opt)
{
int *errflag;
/* Check if SUNDIALS function returned NULL pointer - no memory allocated */
if (opt == 0 && flagvalue == NULL) {
fprintf(stderr, "\nSUNDIALS_ERROR: %s() failed - returned NULL pointer\n\n",
funcname);
return(1); }
/* Check if flag < 0 */
else if (opt == 1) {
errflag = (int *) flagvalue;
if (*errflag < 0) {
fprintf(stderr, "\nSUNDIALS_ERROR: %s() failed with flag = %d\n\n",
funcname, *errflag);
return(1); }}
/* Check if function returned NULL pointer - no memory allocated */
else if (opt == 2 && flagvalue == NULL) {
fprintf(stderr, "\nMEMORY_ERROR: %s() failed - returned NULL pointer\n\n",
funcname);
return(1); }
return(0);
}
/*
*-------------------------------
* Functions called by the solver
*-------------------------------
*/
double nonlin(double phi)
{
// return((phi*phi)*(1.0 - (phi*phi)));
return((phi)*(1.0 - (phi*phi)));
}
double dnonlin(double phi)
{
// return(phi*(2.0 - 4.0*phi*phi));
return(1.0 - 3.0*phi*phi);
}
/* f routine. Compute RHS function udot = F(t,u). */
static int F(realtype t, N_Vector u, N_Vector udot, void *f_data)
{
realtype *udata, *dudata, UIJ;
UserData data;
int i,j;
data = (UserData) f_data;
udata = NV_DATA_S(u);
dudata = NV_DATA_S(udot);
N_VConst(0.0, udot); /* zerujemy wszystkie wspolrzedne udot - potem to mozna zastapic przez zamiane kolejnosci operacji */
AddLaplacian(udata, dudata, BETA);
for (i = 1; i <= N; i++)
{
for (j= 1; j <= N; j++)
{
UIJ = IJth(udata,i,j);
IJth(dudata,i,j) += nonlin(UIJ);
}
}
return(0);
}
/*
operacja przylozenia laplasjanu: wykorzystywana w funkcji prawej strony f();
LapU += a*Laplasjan2D(U)
*/
static int AddLaplacian(realtype *U, realtype *LapU, realtype a)
{
int i,j;
/* najpierw w punktach wewnetrznych */
for(i = 2; i <= N-1 ; i++)
for(j = 2; j <= N-1; j++)
IJth(LapU,i,j) -= a*((2.0*IJth(U,i,j) - IJth(U,i+1,j) - IJth(U,i-1,j))*IHX + (2.0*IJth(U,i,j) - IJth(U,i,j+1) - IJth(U,i,j-1))*IHY);
/* w punktach skrajnych: j=1 i j=N */
for(i = 2; i <= N-1 ; i++)
{
IJth(LapU,i,1) -= a*((2.0*IJth(U,i,1) - IJth(U,i+1,1) - IJth(U,i-1,1))*IHX + (2.0*IJth(U,i,1) - IJth(U,i,2))*IHY);
IJth(LapU,i,N) -= a*((2.0*IJth(U,i,N) - IJth(U,i+1,N) - IJth(U,i-1,N))*IHX + (2.0*IJth(U,i,N) - IJth(U,i,N-1))*IHY);
}
/* w punktach skrajnych: i=1 i i=N */
for(j = 2; j <= N-1 ; j++)
{
IJth(LapU,1,j) -= a*((2.0*IJth(U,1,j) - IJth(U,2,j))*IHX + (2.0*IJth(U,1,j) - IJth(U,1,j+1) - IJth(U,1,j-1))*IHY);
IJth(LapU,N,j) -= a*((2.0*IJth(U,N,j) - IJth(U,N-1,j))*IHX + (2.0*IJth(U,N,j) - IJth(U,N,j+1) - IJth(U,N,j-1))*IHY);
}
/* w punktach naroznych */
IJth(LapU,1,1) -= a*((2.0*IJth(U,1,1) - IJth(U,2,1))*IHX + (2.0*IJth(U,1,1) - IJth(U,1,2))*IHY);
IJth(LapU,1,N) -= a*((2.0*IJth(U,1,N) - IJth(U,2,N))*IHX + (2.0*IJth(U,1,N) - IJth(U,1,N-1))*IHY);
IJth(LapU,N,1) -= a*((2.0*IJth(U,N,1) - IJth(U,N-1,1))*IHX + (2.0*IJth(U,N,1) - IJth(U,N,2))*IHY);
IJth(LapU,N,N) -= a*((2.0*IJth(U,N,N) - IJth(U,N-1,N))*IHX + (2.0*IJth(U,N,N) - IJth(U,N,N-1))*IHY);
return(0);
}
/* DFxV mnozy macierz jakobianu przez zadany wektor; oczywiscie w tym celu nie trzeba konstruowac pelnej macierzy Jakobianu! */
static int DFxV(N_Vector v, N_Vector Jv, realtype t, N_Vector y, N_Vector fy, void *jac_data, N_Vector tmp)
{
realtype *vdata, *Jvdata, *ydata, *fydata, yUIJ, UIJ;
int i,j;
vdata = NV_DATA_S(v);
Jvdata = NV_DATA_S(Jv);
ydata = NV_DATA_S(y);
fydata = NV_DATA_S(fy);
N_VConst(0.0, Jv);
AddLaplacian( vdata, Jvdata, BETA);
for( i = 1; i <= N; i++)
{
for( j = 1; j <= N; j++)
{
UIJ = IJth(vdata,i,j);
yUIJ = IJth(ydata,i,j);
IJth(Jvdata, i, j) += dnonlin(yUIJ)*UIJ;
}
}
return(0);
}
Aby skompilować nasz plik do programu wykonywalnego, najwygodniej skorzystać z polecenia make, dla którego należy uprzednio przygotować plik z instrukcjami i opcjami kompilacji. Więcej o poleceniu make można przeczytać w [17] lub na przykład na Ważniaku (przedmiot Środowisko programisty). Przykładowy taki Makefile podajemy poniżej:
CC = gcc -std=c99 ARCHFLAGS= -march=native CFLAGS = -O3 -msse2 -mfpmath=sse $(ARCHFLAGS) -funroll-loops \ -finline-functions -malign-double \ -ftree-vectorize -ftree-vectorizer-verbose=2 LIBS = -lm all: cvrd cvrd: cvrd.o $(CC) $(CFLAGS) -o $@ $< -lsundials_cvode -lsundials_nvecserial -lm %.o: %.c Makefile $(CC) $(CFLAGS) -c $< clean: rm -f *.o rm -f cvrd
Jak widzimy, w odróżnieniu do króciutkich plików Octave, gdzie na wyznaczenie rozwiązania (i jego wizualizację!) układu równań różniczkowych potrzebowaliśmy kilkunastu linii kodu, końcowa wersja pliku źródłowego w C jest bardzo obszerna. Dlatego ograniczymy się tutaj zwrócenia uwagi na kilka istotnych fragmentów głównego programu.
Wykorzystanie makr
Zacznijmy od ogólnej uwagi, dotyczącej niebezpieczeństwa, jakie za sobą niesie używanie wyrażeń #definiowanych, takich jak np.
#define HX (X/(N+1)) /* krok przestrzenny */
Gdybyśmy napisali makro inaczej, #define HX X/(N+1) (różnica: brak nawiasów okalających), to potem spotkałaby nas niemiła niespodzianka:
#define HX X/(N+1) /* źle! */ z = a/HX;
Rzeczywiście, po podstawieniu makra do wyrażenia, dostajemy
z = a/X/(N+1) i — ponieważ w języku C wartość wyrażenia oblicza się od lewej do prawej — zostałoby to obliczone jako ![]() . To zapewne nie jest wynik, jakiego się spodziewalibyśmy….
. To zapewne nie jest wynik, jakiego się spodziewalibyśmy….
Dostęp do macierzy niewiadomych
Podobnie jak w Octave, dla danej chwili czasu, niewiadome traktujemy jako macierz ![]() o rozmiarach
o rozmiarach ![]() . Jej elementy odpowiadają wartościom rozwiązania w punktach siatki przestrzennej. Ponieważ CVODE spodziewa się wektora, a nie macierzy niewiadomych — zastosujemy technikę rozwijania macierzy w wektor (por. [17]). Makro
. Jej elementy odpowiadają wartościom rozwiązania w punktach siatki przestrzennej. Ponieważ CVODE spodziewa się wektora, a nie macierzy niewiadomych — zastosujemy technikę rozwijania macierzy w wektor (por. [17]). Makro
#define IJth(a,i,j) (a[(j)-1 + ((i)-1)*N])
pozwoli nam w funkcjach użytkownika (np. F() i DFxV()) patrzeć na ![]() jak na macierz
jak na macierz ![]() i jednocześnie pozwoli CVODE wewnętrznie traktować
i jednocześnie pozwoli CVODE wewnętrznie traktować ![]() jako wektor długości
jako wektor długości ![]() . Wszędzie, gdzie było to możliwe, pętle po wszystkich elementach macierzy
. Wszędzie, gdzie było to możliwe, pętle po wszystkich elementach macierzy ![]() zapisujemy
zapisujemy
for(i = 1; i <= N; i++)
{
for( j = 1; j <= N; j++)
{
...wyrażenie zawierające IJth(u,i,j)...
}
}
Z punktu widzenia lokalności dostępu do danych, indeksowanie elementów macierzy ![]() wierszami (właśnie tak, jak zapisano w makrze
wierszami (właśnie tak, jak zapisano w makrze IJth powyżej) powinno być korzystniejsze niż analogiczne indeksowanie kolumnami. I rzeczywiście, pomiary czasu wykonania programu dla ![]() wykazują, że gdy wybierzemy indeksowanie wierszami, oszczędność czasu może sięgnąć kilkunastu procent. Jeśli zaś wybierzemy indeksowanie kolumnami i, bardziej złośliwie,
wykazują, że gdy wybierzemy indeksowanie wierszami, oszczędność czasu może sięgnąć kilkunastu procent. Jeśli zaś wybierzemy indeksowanie kolumnami i, bardziej złośliwie, ![]() (potęgę dwójki), wówczas spotyka nas spadek szybkości działania programu nawet o 40%. Jeszcze raz widzimy więc, jak ważne jest efektywne wykorzystanie pamięci podręcznej procesora (ang. cache).
(potęgę dwójki), wówczas spotyka nas spadek szybkości działania programu nawet o 40%. Jeszcze raz widzimy więc, jak ważne jest efektywne wykorzystanie pamięci podręcznej procesora (ang. cache).
Opcje wykorzystania innych metod
W naszym kodzie zostawiliśmy sobie możliwość wykorzystania eliminacji Gaussa dla rozwiązywania układów równań z macierzą Jakobianu, w zależności od wartości parametru ITLS:
if (ITLS == 0)
CVDense(cvode_mem, NEQ);
else
{
CVSpgmr(cvode_mem, PREC_NONE, 10);
if(USERJAC > 0)
CVSpilsSetJacTimesVecFn(cvode_mem, DFxV, NULL);
}
Dzięki temu, prowadząc próby dla niezbyt wielkich wartości ![]() , zawsze możemy zbadać, czy ewentualne trudności solvera mają jakiś związek z kłopotami metody iteracyjnej. Dodatkowo, zwróćmy uwagę na opcję skorzystania — lub nie — z własnej procedury mnożenia przez Jakobian. Często bowiem opcja automatycznego wyznaczenia wyniku na podstawie różnic dzielonych jest w ostatecznym rachunku tańsza, zwłaszcza, gdy nieliniowości nie są dokuczliwe. Poza tym zawsze warto upewnić się, że faktycznie wykorzystanie funkcji
, zawsze możemy zbadać, czy ewentualne trudności solvera mają jakiś związek z kłopotami metody iteracyjnej. Dodatkowo, zwróćmy uwagę na opcję skorzystania — lub nie — z własnej procedury mnożenia przez Jakobian. Często bowiem opcja automatycznego wyznaczenia wyniku na podstawie różnic dzielonych jest w ostatecznym rachunku tańsza, zwłaszcza, gdy nieliniowości nie są dokuczliwe. Poza tym zawsze warto upewnić się, że faktycznie wykorzystanie funkcji DFxV() powoduje zmniejszenie, a nie zwiększenie liczby iteracji Newtona w stosunku do wariantu z automatyczną aproksymacją Jakobianu (pogorszenie zbieżności metody Newtona jest najczęściej objawem naszego błędu w definicji DFxV()).
Zapis wyników do pliku i ich wizualizacja
Wreszcie, rozwiązując równanie różniczkowe, musimy mieć świadomość, że wynikiem będzie mrowie liczb. Sensowne jest więc pomyśleć o ich zapisie do pliku, a następnie — wizualizacji.
Nasza procedura jest tak skonstruowana, by zapisany plik z danymi bez trudu można było wczytać do zewnętrznego programu wizualizacyjnego OpenDX:
outfile = fopen("cvrd.out", "w");
/* ...pominięte instrukcje... */
for(i = 1; i <= N; i++)
{
for( j = 1; j <= N; j++)
{
fprintf(outfile, "%e ", IJth(udata,i,j));
}
fprintf(outfile, "\n");
}
/* ...pominięte instrukcje... */
fclose(outfile);
Dane z macierzy, odpowiadające ich ułożeniu na siatce dwuwymiarowej, zapisujemy dla kolejnych kroków czasowych. Gdyby danych było bardzo dużo, możemy je skompresować, zapisując je w postacji binarnej, także akceptowanej przez OpenDX.
Aby zapisać dane w formacie strawnym dla innego popularnego systemu, Paraview, należy użyć nieco innego kodu, powodującego utworzenie serii plików zawierających ,,zdjęcie” układu dla danej chwili czasowej, indeksowanej w naszym programie, jak pamiętamy, zmienną iout. Na każdym kroku czasowym, macierz wartości rozwiązania w punktach siatki przestrzennej, ![]() musimy zapisać w specjalnym formacie. W tym celu możemy użyć następującego kodu, który zamieścimy wewnątrz funkcji
musimy zapisać w specjalnym formacie. W tym celu możemy użyć następującego kodu, który zamieścimy wewnątrz funkcji PrintOutput() programu cvrd.c:
{
char filename[26];
sprintf(filename,"cvrd%d.vtk",iout);
outfile = fopen(filename, "w");
fprintf(outfile, "# vtk DataFile Version 3.0\n");
fprintf(outfile, "CVRD wyniki dla siatki %d x %d. Krok czasowy: %d/%d\n", N, N, iout, NOUT);
fprintf(outfile, "ASCII\n");
fprintf(outfile, "DATASET STRUCTURED_POINTS\n");
fprintf(outfile, "DIMENSIONS %d %d %d\n", N, N, 1);
fprintf(outfile, "ORIGIN %g %g %g\n", 0.0, 0.0, 0.0);
fprintf(outfile, "SPACING %g %g %g\n", HX, HY, 0.0);
fprintf(outfile, "POINT_DATA %d\n", N*N);
fprintf(outfile, "SCALARS U float\n");
fprintf(outfile, "LOOKUP_TABLE default\n");
for( j = 1; j <= N; j++)
{
for(i = 1; i <= N; i++)
{
fprintf(outfile, "%e\n", IJth(udata,i,j));
}
}
fclose(outfile);
}
Nie będziemy tu dyskutować, dlaczego właśnie warto użyć takiej, a nie innej reprezentacji danych dla ich późniejszej wizualizacji w systemie OpenDX albo ParaView. Zainteresowanych odsyłamy do dokumentacji tych środowisk lub do podręcznika [17].
W zamian, w rozdziale 11.2 przyjrzymy się (dosłownie, śledząc zapis działań na komputerze), jak wizualizować tak spreparowane dane.
11.2. Wizualizacja wyników
Poniżej przedstawiamy zapis sesji wizualizacyjnej, w której dane wygenerowane podczas symulacji wczytamy do dwóch narzędzi wizualizacyjnych: OpenDX i ParaView. Ich instalacja nie powinna nastręczać żadnych problemów, pod warunkiem, że używana przez nas dystrybucja Linuxa dostarcza gotowe pakiety instalacyjne (por. demo instalacji CVODE z pakietów RPM w Fedorze wcześniej w tym rozdziale); kompilacja tych pakietów z plików źródłowych może być źródłem frustracji i poważnego bólu głowy.
11.2.1. Wizualizacja w OpenDX
Demonstracja sposobu wizualizacji wygenerowanego pola w systemie OpenDX
11.2.2. Wizualizacja w ParaView
Wizualizacja danych z symulacji równania reakcji–dyfuzji w ParaView
Korzystając z dodatkowych możliwości ParaView, możemy zwizualizować nie tylko samo pole, ale także na przykład jego gradient i dywergencję.
Wizualizacja gradientu i dywergencji pola z symulacji równania reakcji–dyfuzji w ParaView
11.3. Weryfikacja wyników
Na zakończenie warto, abyśmy wstępnie zewryfikowali uzyskane wyniki. Do testów użyliśmy warunku początkowego przedstawionego na rysunku 11.2.

Korzystając z CVODE i wizualizując rozwiązanie w ParaView, dostaliśmy w chwili ![]() rozwiązanie przedstawione na rysunku 11.3.
rozwiązanie przedstawione na rysunku 11.3.

RTOL=1e-5.
Oczywiście po wcześniejszych naszych doświadczeniach nasuwa się pytanie, ile pewności możemy mieć co do jakości otrzymanych rozwiązań? Ponieważ nie mamy czasu ani siły na opracowanie bardziej wyrafinowanego testu, możemy skorzystać ze standardowego tricku: należy dwukrotnie (lub więcej razy!) zmniejszyć wszystkie parametry dyskretyzacji i tolerancji błędu — i sprawdzić, czy dalej dostajemy ,,te same” wyniki.
W naszym przypadku:
-
czterokrotnie zmniejszymy krok dyskretyzacji przestrzennej, czyli zmienimy parametr
Nz256na1024; -
stukrotnie zmniejszymy parametry tolerancji błędu po czasie, czyli zmienimy
RTOLz1e-5na1e-7;
i ponownie przeprowadzimy symulację i wizualizację wyników. Jak widać32Znacznie korzystniej jest zmierzyć różnicę pomiędzy wynikami. Oko ludzkie może nie dostrzec niewielkich, lokalnie występujących, ale systematycznie utrzymujących się różnic, będących symptomem kłopotów solvera. z rysunków 11.3 oraz 11.4, uzyskane wyniki są bardzo podobne, a więc (prawdopodobnie!) sensownie przybliżają one prawdziwe rozwiązanie.

RTOL=1e-7.
Ćwiczenie 11.1
Zapisywanie wyników na potrzeby wizualizacji w formie liczb podwójnej precyzji zazwyczaj jest grubą przesadą. Zmodyfikuj więc procedurę eksportu rozwiązania do pliku w taki sposób, by zapisywać wartości jedynie w pojedynczej precyzji (float) i tym samym dwukrotnie zmniejszyć objętość plików.
Ćwiczenie 11.2
Rozwiąż równanie Swifta–Hohenberga, modelujące powstawanie wzorzystych struktur z początkowego chaosu,
Eksperymentuj z różnymi obszarami ![]() (na początek: z kwadratem), różnymi nieujemnymi (w tym: zerowymi) wartościami parametru
(na początek: z kwadratem), różnymi nieujemnymi (w tym: zerowymi) wartościami parametru ![]() i różnymi warunkami brzegowymi dla
i różnymi warunkami brzegowymi dla ![]() . Startując z losowego rozkładu
. Startując z losowego rozkładu ![]() odpowiedz na pytanie, jaka jest wartość uzyskanych wyników. (Trudne.)
odpowiedz na pytanie, jaka jest wartość uzyskanych wyników. (Trudne.)


