10. Wykład X, 4.XII.2009
Pod koniec Wykładu IX poznaliśmy już pewne zastosowanie fundamentalnego
Twierdzenia 9.2 (pochodzącego od Karusha i Kuhna-Tuckera, podanego w
Wykładzie IX w w formacie `wteddy' w wersji z obiektami wklęsłymi/wypukłymi),
co prawda zastosowanie dość odległe od analizy portfelowej.
Nasuwa się przy tej okazji pytanie, czy może czytelnik umie rozwiązać
Ćwiczenie 9.5 (Wykład IX) bez Twierdzenia 9.2? Jeśli nie,
to skromniejsze pytanie mogłoby brzmieć tak: czy w rozwiązaniu Ćwiczenia 9.5
podanym w Wykładzie IX koniecznych jest dziesięć warunków nierównościowych?
Np zmniejszenie ilości węzłów z pięciu do trzech dałoby tylko sześć
warunków nierównościowych, lecz (chyba) byłoby to wylanie dziecka
razem z kąpielą.
Pora teraz na zastosowanie bliższe nurtowi (i nazwie) wykładu.
Przez chwilę będzie znowu o modelach ![]() doskonale skorelowanych.
doskonale skorelowanych.
Czytelnik nabierze wprawy w posługiwaniu się Twierdzeniem 9.2, rozwiązując samodzielnie (względnie śledząc rozwiązanie ukryte pod dodatkowym kliknięciem) następujące proste
Ćwiczenie 10.1
W modelu ![]() doskonale skorelowanym z Przykładu 3.1 w Wykładzie III,
w aspekcie M [z którym związany jest Rysunek 3.2; w Wykładzie III
jeszcze nie znaliśmy aspektu B] znaleźć wszystkie portfele
minimalnego ryzyka, przy czym specjalnie stosując w tym
celu Twierdzenie 9.2.
doskonale skorelowanym z Przykładu 3.1 w Wykładzie III,
w aspekcie M [z którym związany jest Rysunek 3.2; w Wykładzie III
jeszcze nie znaliśmy aspektu B] znaleźć wszystkie portfele
minimalnego ryzyka, przy czym specjalnie stosując w tym
celu Twierdzenie 9.2.
Chodzi o minimalizację wariancji portfela ![]() , która w tym
modelu
, która w tym
modelu ![]() doskonale skorelowanym wyraża się, jeśli pamiętamy to jeszcze
z Wykładu III, wzorem
doskonale skorelowanym wyraża się, jeśli pamiętamy to jeszcze
z Wykładu III, wzorem ![]() . To minimum jest bardzo
łatwo znaleźć tak po prostu, przy czym osiągane jest ono w punktach przecięcia
płaszczyzny krytycznej z sympleksem
. To minimum jest bardzo
łatwo znaleźć tak po prostu, przy czym osiągane jest ono w punktach przecięcia
płaszczyzny krytycznej z sympleksem ![]() (porównaj Przykład 6.2).
Teraz chodzi nam o uzyskanie tego samego jeszcze raz, wprost z twierdzenia
K-KT.
(porównaj Przykład 6.2).
Teraz chodzi nam o uzyskanie tego samego jeszcze raz, wprost z twierdzenia
K-KT.
Po odpowiednim wyspecyfikowaniu Twierdzenia 9.2, zresztą bardzo podobnym
do tego, które rozwijane jest niżej w tym wykładzie w kontekście relatywnego
minimum ryzyka, szukamy portfeli ![]() ,
dla których istnieje
,
dla których istnieje ![]() takie, że: po pierwsze
(używając nie całej, tylko połowy wariancji)
takie, że: po pierwsze
(używając nie całej, tylko połowy wariancji)
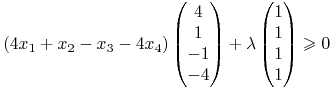 |
(10.1) |
jako wektor w ![]() (= nieujemność każdej składowej wektora
po lewej stronie), oraz, po drugie, iloczyn skalarny
wektora stojącego po lewej stronie (10.1) z wektorem
(= nieujemność każdej składowej wektora
po lewej stronie), oraz, po drugie, iloczyn skalarny
wektora stojącego po lewej stronie (10.1) z wektorem
![]() jest zero:
jest zero:
| (10.2) |
(warunek komplementarności przy przyjętej specyfikacji twierdzenia).
Dodajmy teraz stronami na przykład dwie środkowe nierówności w
(10.1).27albo dwie skrajne, albo wszystkie cztery
Dostajemy nieujemność współczynnika ![]() . Lecz (10.2)
daje niedodatniość
. Lecz (10.2)
daje niedodatniość ![]() .
Zatem
.
Zatem ![]() , więc też, znowu z (10.2),
, więc też, znowu z (10.2),
![]() . Ryzyko w aspekcie M
minimalizują więc te portfele Markowitza, które … mają
zerowe ryzyko. (Porównaj też jeszcze raz Przykład 6.2.)
Niby nic, lecz ,,wycisnęliśmy tę” informację z Twierdzenia 9.2!
. Ryzyko w aspekcie M
minimalizują więc te portfele Markowitza, które … mają
zerowe ryzyko. (Porównaj też jeszcze raz Przykład 6.2.)
Niby nic, lecz ,,wycisnęliśmy tę” informację z Twierdzenia 9.2!
Już w tym rozwiązaniu wychodzą cechy charakterystyczne twierdzenia K-KT. Po bliższym przyjrzeniu się okazuje się, że jedna część jego tezy, tu zapisana jako (10.1), ciągnie niejako szukany współczynnik Lagrange'a (w ćwiczeniu jest on tylko jeden) w jedną stronę. Natomiast druga część tezy, tu (10.2), ciągnie ten współczynnik w drugą stronę. W efekcie wyłania się jakaś równowagowa wartość takiego współczynnika, która de facto jest zakodowanym opisem ekstremów. Nie przypadkiem w literaturze francuskojęzycznej, np w [25], twierdzenie K-KT jest nazywane twierdzeniem o punkcie siodłowym.
Ćwiczenie 10.2
Znaleźć przy pomocy Twierdzenia 9.2 wszystkie portfele
minimalnego ryzyka w aspekcie M w dowolnym modelu ![]() doskonale skorelowanym.
doskonale skorelowanym.
Naszym głównym celem w Wykładzie X jest zastosowanie Twierdzenia
Karusha-Kuhna-Tuckera 9.2 (w przyszłości będziemy już pisać
tylko krótko `K-KT') do zautomatyzowanego poszukiwania portfeli
relatywnie minimalnego ryzyka w modelach Markowitza,
które bliższe są warunkom giełdowym niż modele ![]() doskonale
skorelowane.
doskonale
skorelowane.
Dla (niezdegenerowanych) modeli Blacka w Wykładzie VI polegało to na dość standardowym zastosowaniu wiedzy z AM II, bo dwa warunki ograniczające były tylko równościowe. W efekcie gładko dostaliśmy (w Twierdzeniu 6.1) wszystkie portfele krytyczne Blacka układające się na prostej krytycznej Blacka.
Teraz jednak dochodzi ![]() ograniczeń nierównościowych związanych
z leżeniem portfeli w sympleksie
ograniczeń nierównościowych związanych
z leżeniem portfeli w sympleksie ![]() (nieujemność składowych
portfeli, brak krótkiej sprzedaży), co komplikuje sytuację. Jest
to jakościowo nowy problem. Czym teraz zastąpiona zostanie prosta
krytyczna Blacka?
(nieujemność składowych
portfeli, brak krótkiej sprzedaży), co komplikuje sytuację. Jest
to jakościowo nowy problem. Czym teraz zastąpiona zostanie prosta
krytyczna Blacka?
Zgodnie z tradycją przyjętą w analizie portfelowej, współczynniki
Lagrange'a związane z warunkami równościowymi ![]() ,
,
![]() (wartości
(wartości ![]() nie będą teraz dowolne, tylko
ograniczone do powłoki wypukłej wartości oczekiwanych stóp zwrotu
ze spółek numer
nie będą teraz dowolne, tylko
ograniczone do powłoki wypukłej wartości oczekiwanych stóp zwrotu
ze spółek numer ![]() ) piszemy jako, odpowiednio,
) piszemy jako, odpowiednio, ![]() i
i ![]() , zaś nierówności
, zaś nierówności ![]() (
(![]() )
kodujemy jako
)
kodujemy jako ![]() , gdzie
, gdzie
![]() ,
,
![]() ,
, ![]() . Jako funkcję
. Jako funkcję ![]() bierzemy
bierzemy
która dla ![]() jest wypukła i różniczkowalna w każdym
punkcie
jest wypukła i różniczkowalna w każdym
punkcie ![]() , zaś jej gradient to
, zaś jej gradient to ![]() . Twierdzenie K-KT
zastosowane w tej sytuacji mówi, że
. Twierdzenie K-KT
zastosowane w tej sytuacji mówi, że ![]() spełniający wymienione warunki
jest globalnym minimum
spełniający wymienione warunki
jest globalnym minimum ![]() przy podanych warunkach (ograniczeniach)
przy podanych warunkach (ograniczeniach)
![]() istnieją
istnieją ![]() takie,
że
takie,
że
Podamy teraz warunek dostateczny, przy którym takie
portfele relatywnie minimalnego ryzyka istnieją i są jednoznacznie
wyznaczone dla każdej wartości ![]() .
Jest on trochę za silny (mógłby być trochę osłabiony), co w praktyce
jednak nie przeszkadza, bo przy estymacji wartości oczekiwanych z
historycznych danych giełdowych praktycznie nigdy nie dostaniemy
pary równych wartości. W zamian zaś pozwala zręcznie opisać
procedurę poszukiwania.
.
Jest on trochę za silny (mógłby być trochę osłabiony), co w praktyce
jednak nie przeszkadza, bo przy estymacji wartości oczekiwanych z
historycznych danych giełdowych praktycznie nigdy nie dostaniemy
pary równych wartości. W zamian zaś pozwala zręcznie opisać
procedurę poszukiwania.
Mianowicie, w dalszym ciągu zakładamy, że ![]() oraz
oraz
| (10.3) |
tzn. wszystkie wartości oczekiwane ![]() są różne.
Te założenia będą obowiązywać do odwołania. (Zauważamy, że
są to silniejsze założenia niż dawna informacja (5.2),
która wystarczała w teorii Blacka. Przy różnych pod-zestawach
zmiennych będziemy w obecnym algorytmie wracać do (5.2).)
są różne.
Te założenia będą obowiązywać do odwołania. (Zauważamy, że
są to silniejsze założenia niż dawna informacja (5.2),
która wystarczała w teorii Blacka. Przy różnych pod-zestawach
zmiennych będziemy w obecnym algorytmie wracać do (5.2).)
Algorytm prowadzący do rozwiązania nie mówi od razu, dla jakich
konkretnie wartości ![]() rozwiązanie znajdziemy na konkretnej ścianie
sympleksu. Całość poszukiwań dzielimy (niestety lub stety) na etapy,
których jest
rozwiązanie znajdziemy na konkretnej ścianie
sympleksu. Całość poszukiwań dzielimy (niestety lub stety) na etapy,
których jest
| (10.4) |
Etap ![]() . Szukanie wśród portfeli
. Szukanie wśród portfeli
![]() .
.
Warunek komplementarności pociąga wtedy wektorową równość
co łącznie z dwoma ograniczeniami równościowymi w problemie
zapisujemy przy pomocy tzw. macierzy Lagrange'a, tu wymiaru ![]() :
:
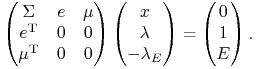 |
Dawne założenie (5.2) oczywiście wynika z (10.3),
więc dostajemy tu jedyne rozwiązanie ![]() ,
na temat którego rozwiązujemy następnie układ nierówności
,
na temat którego rozwiązujemy następnie układ nierówności
![]() .
Wynikiem jest jakiś przedział otwarty wartości
.
Wynikiem jest jakiś przedział otwarty wartości ![]() (być może pusty)
i odpowiadające portfele
(być może pusty)
i odpowiadające portfele ![]() . Macierz Lagrange'a, która tu została
przywołana i użyta, to tylko przeformułowanie i pewne uzwarcenie metody
Blacka i noblistów z Wykładu VI. Portfele
. Macierz Lagrange'a, która tu została
przywołana i użyta, to tylko przeformułowanie i pewne uzwarcenie metody
Blacka i noblistów z Wykładu VI. Portfele ![]() ewentualnie
wyłaniające się w tym etapie są tożsame z portfelami Blacka (6.2)
z Wykładu VI leżącymi wewnątrz sympleksu
ewentualnie
wyłaniające się w tym etapie są tożsame z portfelami Blacka (6.2)
z Wykładu VI leżącymi wewnątrz sympleksu ![]() . Na dalszych etapach
tak już być nie musi (i najczęściej nie będzie); jednak patrz też
Ćwiczenia 11.1 i 11.2 oraz Uwaga 11.2 w Wykładzie XI. Uzwarcenie
metody dawane przez macierz Lagrange'a będzie nam pomocne w
dalszych etapach.
. Na dalszych etapach
tak już być nie musi (i najczęściej nie będzie); jednak patrz też
Ćwiczenia 11.1 i 11.2 oraz Uwaga 11.2 w Wykładzie XI. Uzwarcenie
metody dawane przez macierz Lagrange'a będzie nam pomocne w
dalszych etapach.
Wreszcie nazwa tego etapu, ![]() , oznacza, że pusty jest
w nim zbiór indeksów zmiennych, które przyjmujemy za zero.
, oznacza, że pusty jest
w nim zbiór indeksów zmiennych, które przyjmujemy za zero.
Ogólniej, etap OUT, gdzie
![]() ,
,
![]() , polega na szukaniu
, polega na szukaniu![]() dla
dla ![]() , natomiast
, natomiast ![]() dla
dla
![]() ,
spełniających warunki w omawianej tu wersji twierdzenia K-KT, tzn.
,
spełniających warunki w omawianej tu wersji twierdzenia K-KT, tzn.
| (10.5) |
dla jakichś ![]() . Równości w (10.5)
wynikają z warunku komplementarności, zaś nierówności w (10.5)
wynikają z warunku na gradient minimalizowanej funkcji. Oznacza to
konkretnie, że w takim etapie OUT najpierw rozwiązujemy układ
. Równości w (10.5)
wynikają z warunku komplementarności, zaś nierówności w (10.5)
wynikają z warunku na gradient minimalizowanej funkcji. Oznacza to
konkretnie, że w takim etapie OUT najpierw rozwiązujemy układ
![]() równań liniowych
równań liniowych
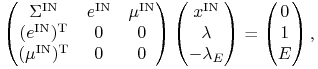 |
(10.6) |
gdzie ![]() to macierz
to macierz ![]() po wyrzuceniu wierszy i
kolumn o numerach z OUT oraz
po wyrzuceniu wierszy i
kolumn o numerach z OUT oraz ![]() ,
, ![]() to wektory
to wektory ![]() po odrzuceniu składowych o numerach z OUT.
po odrzuceniu składowych o numerach z OUT.
Ważne jest, że ![]() oraz
oraz ![]() , a więc stosuje się teoria Blacka
i współautorów, tyle, że w wymiarze
, a więc stosuje się teoria Blacka
i współautorów, tyle, że w wymiarze ![]() , nie zaś
, nie zaś ![]() .
Tu właśnie pracuje zestaw założeń (10.3),
.
Tu właśnie pracuje zestaw założeń (10.3), ![]() i
i ![]() .
.
Ćwiczenie 10.3
Uzasadnić, że istotnie, założenia ![]() i
i ![]() pociągają
pociągają ![]() .
.
Uzasadnić też, że założenia (10.3) i ![]() pociągają
pociągają ![]() .
.
Tym sposobem wiemy, że rozwiązania ![]() układu (10.6) istnieją i są jedyne. Z pomocą przyszedł nam,
dosyć niespodziewanie, Wykład VI.
układu (10.6) istnieją i są jedyne. Z pomocą przyszedł nam,
dosyć niespodziewanie, Wykład VI.
Mając już te rozwiązania, rozwiązujemy następnie
ze względu na ![]() układ nierówności
układ nierówności
![\left\{\begin{array}[]{ll}x_{i}(E)>0,&\hbox{$i\in\text{IN}$,}\\
\big(\Sigma x(E)+\lambda(E)e-\lambda _{E}(E)\mu\big)_{j}\ge 0,&\hbox{$j\in\text{OUT}$.}\end{array}\right.](wyklady/pk1/mi/mi1106.png) |
W wyniku otrzymujemy przecięcie ![]() półprostych domkniętych i/lub
otwartych, czyli, ogólnie rzecz biorąc, przedział postaci
półprostych domkniętych i/lub
otwartych, czyli, ogólnie rzecz biorąc, przedział postaci
![]() , lub
, lub ![]() , lub
, lub ![]() , lub
, lub ![]() , albo też
, albo też ![]() .
.
Definicja 10.1
Przedział ten będziemy w dalszym ciągu nazywać ![]() ;
uprości nam to w przyszłości przedstawienie kluczowego dla tych
wykładów Algorytmu Prostej Krytycznej (skrót nazwy angielskiej,
nieomalże powszechnie przyjętej, to: CLA).
;
uprości nam to w przyszłości przedstawienie kluczowego dla tych
wykładów Algorytmu Prostej Krytycznej (skrót nazwy angielskiej,
nieomalże powszechnie przyjętej, to: CLA).
Tak przebiegamy wszystkie ![]() etapów, w których
etapów, w których
![]() . (Przypominamy, że takie ograniczenie
z dołu na liczebność zbiorów IN było ważne i gwarantowało,
oczywiście przy założeniu (10.3), nierównoległość
zredukowanych wektorów
. (Przypominamy, że takie ograniczenie
z dołu na liczebność zbiorów IN było ważne i gwarantowało,
oczywiście przy założeniu (10.3), nierównoległość
zredukowanych wektorów ![]() oraz
oraz ![]() ,
a w efekcie możliwość stosowania na każdym etapie OUT
klasycznej teorii Blacka i współautorów.)
,
a w efekcie możliwość stosowania na każdym etapie OUT
klasycznej teorii Blacka i współautorów.)
Przykład 10.1 (ważny; wracamy do niego już po raz czwarty, za każdym razem w innym kontekście, po Wykładach: V (Przykład 5.2), VII (Ćwiczenie 7.3) i IX (Przykład 9.1))
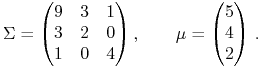 |
Etap ![]() . Nieostre nierówności stają się
(warunek komplementarności!) równościami – w tym etapie szukamy
ewentualnych punktów prostej krytycznej leżących wewnątrz
sympleksu standardowego. Rozwiązujemy zatem równanie (patrz Twierdzenie 5.1)
. Nieostre nierówności stają się
(warunek komplementarności!) równościami – w tym etapie szukamy
ewentualnych punktów prostej krytycznej leżących wewnątrz
sympleksu standardowego. Rozwiązujemy zatem równanie (patrz Twierdzenie 5.1)
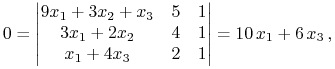 |
oczywiście z zerowym skutkiem. Ten etap nic nie daje, bo
prosta krytyczna nie przechodzi tu przez wnętrze sympleksu:
![]() .28Zamiast liczyć wyznacznik,
można sobie przypomnieć, że prosta krytyczna muska tylko trójkąt
w wierzchołku
.28Zamiast liczyć wyznacznik,
można sobie przypomnieć, że prosta krytyczna muska tylko trójkąt
w wierzchołku ![]() – patrz pierwszy z filmików w Wykładzie V.
– patrz pierwszy z filmików w Wykładzie V.
Etap ![]() , w którym
, w którym ![]() ,
, ![]() ,
, ![]() .
Piszemy odpowiedni układ równań (10.6)
.
Piszemy odpowiedni układ równań (10.6)
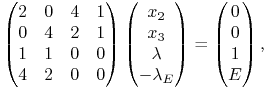 |
którego rozwiązania to
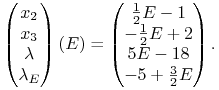 |
Dodatniość ![]() i
i ![]() oznacza, że
oznacza, że ![]() . Co teraz
z pierwszą nierównością
. Co teraz
z pierwszą nierównością ![]() ,
która też musi być spełniona przez portfele relatywnie minimalnego
ryzyka? Po podstawieniu rozwiązań jest to nierówność
,
która też musi być spełniona przez portfele relatywnie minimalnego
ryzyka? Po podstawieniu rozwiązań jest to nierówność ![]() ,
spełniona przez
,
spełniona przez ![]() ze wskazanego przedziału otwartego.
Wniosek:
ze wskazanego przedziału otwartego.
Wniosek: ![]() .
.
Etap ![]() , w którym
, w którym ![]() ,
, ![]() ,
, ![]() .
Odpowiedni układ równań (10.6) to teraz
.
Odpowiedni układ równań (10.6) to teraz
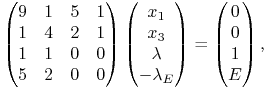 |
którego rozwiązania to z kolei
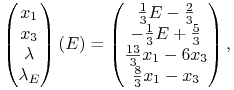 |
gdzie celowo ![]() i
i ![]() zostały uzależnione `tylko'
od
zostały uzależnione `tylko'
od ![]() . Dodatniość
. Dodatniość ![]() i
i ![]() oznacza, że
oznacza, że ![]() .
Co tym razem z drugą nierównością
.
Co tym razem z drugą nierównością ![]() ?
Po podstawieniu rozwiązań jej lewa strona to
?
Po podstawieniu rozwiązań jej lewa strona to ![]() ,
a więc wielkość ujemna. Wniosek:
,
a więc wielkość ujemna. Wniosek: ![]() .
.
Jeśli chodzi o etap ![]() , to analogiczne rachunki
dają w efekcie
, to analogiczne rachunki
dają w efekcie ![]() . Zatem, podsumowując, z
całego przedziału
. Zatem, podsumowując, z
całego przedziału ![]() dostajemy tutaj
dostajemy tutaj
![]() . Jest to cały
. Jest to cały ![]() bez
trzech węzłów wyróżnionych, w terminologii wprowadzanej
w Twierdzeniu 10.1 na końcu tego wykładu.
bez
trzech węzłów wyróżnionych, w terminologii wprowadzanej
w Twierdzeniu 10.1 na końcu tego wykładu.
Ćwiczenie 10.4
Skoro, w tym jednym modelu, dla wszystkich, lub prawie wszystkich
wartości ![]() znaleźliśmy portfele relatywnie minimalnego ryzyka w
aspekcie M, bez trudu możemy już wskazać portfele, które
przechodzą na granicę minimalną
znaleźliśmy portfele relatywnie minimalnego ryzyka w
aspekcie M, bez trudu możemy już wskazać portfele, które
przechodzą na granicę minimalną ![]() w tym modelu i aspekcie.
Należy to zrobić teraz, po czym porównać odpowiedź
z łamaną efektywną w tym samym modelu, będącą przedmiotem
Ćwiczenia 7.3 w Wykładzie VII. Zbiór portfeli wyłaniający się
z bieżącego ćwiczenia to przykład łamanej portfeli relatywnie
minimalnego ryzyka ilustrujący Twierdzenie 10.1 poniżej.
w tym modelu i aspekcie.
Należy to zrobić teraz, po czym porównać odpowiedź
z łamaną efektywną w tym samym modelu, będącą przedmiotem
Ćwiczenia 7.3 w Wykładzie VII. Zbiór portfeli wyłaniający się
z bieżącego ćwiczenia to przykład łamanej portfeli relatywnie
minimalnego ryzyka ilustrujący Twierdzenie 10.1 poniżej.
Zanim sformułujemy zapowiadane twierdzenie ogólne, przyjrzymy się
jeszcze autentycznie przełomowemu przykładowi modelu Markowitza
w wymiarze 4, pochodzącemu od K. Więcha [29], w którym
każdy etap OUT przynosi niepusty zbiór rozwiązań ![]() .
Przykład ten był (tylko) anonsowany w Wykładzie VII. Mianowicie
.
Przykład ten był (tylko) anonsowany w Wykładzie VII. Mianowicie
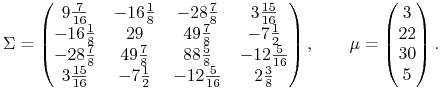 |
(10.7) |
Wówczas po wykonaniu wszystkich ![]() etapów
OUT uzyskuje się następujące rozwiązania:
etapów
OUT uzyskuje się następujące rozwiązania:
| Przedział wartości |
Skrajne wartości parametru |
Etap OUT |
Nawet w tej chwili (w roku akademickim 2009/10) przykład ten wygląda
wspaniale, a co dopiero w roku 2001, gdy się pojawił. Proszę np zwrócić
uwagę, jaką formalną symetrię środkową ma ciąg typów przedziałów
wartości ![]() w lewej kolumnie:
w lewej kolumnie:
Ćwiczenie 10.5 (sprawdzające)
Narysować wykres funkcji
której węzły wykresu są zakodowane w powyższej tabeli. (Pomiędzy
węzłami, jak wynika z opisu etapów algorytmu, funkcja ![]() jest liniowa. Ogólnie jest więc ona kawałkami liniowa.)
jest liniowa. Ogólnie jest więc ona kawałkami liniowa.)
Zadanie to jest rozwiązane w ostatnim Wykładzie XV (Rysunek 15.2). Wszystkie dane do rysunku są jednak dostępne już teraz i każdy czytelnik może wykonać własną wersję wykresu.
Ogólne twierdzenie na temat zbiorów portfeli relatywnie minimalnego
ryzyka w modelach Markowitza musi … poczekać jeszcze chwilę,
bo właśnie teraz nadarza się najlepsza okazja, by ugruntować
jednocześnie i model Więcha i twierdzenie K-KT.
Portfeli minimalnego ryzyka szukaliśmy dotąd przy pomocy tego twierdzenia
w modelach ![]() doskonale skorelowanych (Ćwiczenia 10.1 i 10.2 powyżej).
Natomiast w modelach niezdegenerowanych – jak ten koronny przykład
Więcha – jeszcze nie.
doskonale skorelowanych (Ćwiczenia 10.1 i 10.2 powyżej).
Natomiast w modelach niezdegenerowanych – jak ten koronny przykład
Więcha – jeszcze nie.
Ćwiczenie 10.6
W modelu Więcha znaleźć, oczywiście w aspekcie M, portfel
![]() o najmniejszej wariancji. (Jest to równocześnie,
warto wiedzieć, portfel efektywny w aspekcie M o najmniejszej
wartości oczekiwanej; więcej o tych sprawach będzie w Wykładzie XI.)
o najmniejszej wariancji. (Jest to równocześnie,
warto wiedzieć, portfel efektywny w aspekcie M o najmniejszej
wartości oczekiwanej; więcej o tych sprawach będzie w Wykładzie XI.)
Zastosować algorytm bazujący na twierdzeniu K-KT, tym razem z jednym
ograniczeniem równościowym ![]() zamiast dwóch i z
czterema ograniczeniami nierównościowymi
zamiast dwóch i z
czterema ograniczeniami nierównościowymi ![]() ,
,
![]() .
.
Inne niż sugerowane we wskazówce rozwiązanie, mniej eleganckie (zo to wykorzystujące Tabelę powyżej), jest podane w Przykładzie 11.2.
Twierdzenie 10.1 (nt zbioru portfeli relatywnie minimalnego ryzyka w modelach Markowitza)
![]() Przy założeniach
Przy założeniach ![]() oraz (10.3), portfele
relatywnie minimalnego ryzyka w modelu Markowitza tworzą łamaną Ł
o nie więcej niż
oraz (10.3), portfele
relatywnie minimalnego ryzyka w modelu Markowitza tworzą łamaną Ł
o nie więcej niż ![]() rozłącznych bokach. Każdy bok jest
odcinkiem
rozłącznych bokach. Każdy bok jest
odcinkiem ![]() lub
lub ![]() lub
lub ![]() lub
lub ![]() , i każdy leży
w innej ścianie sympleksu
, i każdy leży
w innej ścianie sympleksu ![]() (będącej krawędzią, bądź trójkątem,
bądź czworościanem, bądź …, bądź wnętrzem
(będącej krawędzią, bądź trójkątem,
bądź czworościanem, bądź …, bądź wnętrzem ![]() ). Portfele
na różnych bokach Ł mają więc różne składy jakościowe, a na
danym boku niezmienny skład jakościowy.
). Portfele
na różnych bokach Ł mają więc różne składy jakościowe, a na
danym boku niezmienny skład jakościowy.
![]() Nie wszystkie końce boków łamanej Ł należą do
Ł. Takich wyróżnionych przez nienależenie wierzchołków Ł zawsze
jest nie mniej niż dwa i nie więcej niż
Nie wszystkie końce boków łamanej Ł należą do
Ł. Takich wyróżnionych przez nienależenie wierzchołków Ł zawsze
jest nie mniej niż dwa i nie więcej niż ![]() – są to niektóre
z wierzchołków sympleksu
– są to niektóre
z wierzchołków sympleksu ![]() , przy czym zawsze – wierzchołki
o najmniejszej i największej wartości oczekiwanej. Te wyróżnione
wierzchołki łamanej Ł odpowiadają wartościom parametru
, przy czym zawsze – wierzchołki
o najmniejszej i największej wartości oczekiwanej. Te wyróżnione
wierzchołki łamanej Ł odpowiadają wartościom parametru
![]() ,
które pozostają nieobsłużone po wykonaniu wszystkich
,
które pozostają nieobsłużone po wykonaniu wszystkich ![]() etapów OUT dla
etapów OUT dla ![]() ,
,
![]() .
Takie wartości
.
Takie wartości ![]() nazywamy węzłami wyróżnionymi.
nazywamy węzłami wyróżnionymi.
![]() Po domknięciu w wierzchołkach wyróżnionych
łamana
Po domknięciu w wierzchołkach wyróżnionych
łamana ![]() jest łamaną spójną. Ł, czy też częściej
jest łamaną spójną. Ł, czy też częściej
![]() , jest nazywana łamaną wierzchołkową
w danym modelu Markowitza (dużo rzadziej nazywa się ją ”łamaną
portfeli relatywnie minimalnego ryzyka”).
, jest nazywana łamaną wierzchołkową
w danym modelu Markowitza (dużo rzadziej nazywa się ją ”łamaną
portfeli relatywnie minimalnego ryzyka”).


