Zagadnienia
10. Markowowskie Monte Carlo I. Wprowadzenie
10.1. Co to jest MCMC ?
W pewnych sytuacjach okazuje się, że wygenerowanie zmiennej losowej ![]() z interesującego nas
rozkładu prawdopodobieństwa
z interesującego nas
rozkładu prawdopodobieństwa ![]() jest praktycznie niemożliwe. Wyobraźmy sobie, że
jest praktycznie niemożliwe. Wyobraźmy sobie, że ![]() jest
bardzo skomplikowanym rozkładem na ,,ogromnej”, wielowymiarowej przestrzeni
jest
bardzo skomplikowanym rozkładem na ,,ogromnej”, wielowymiarowej przestrzeni ![]() .
Zazwyczaj ten rozkład jest dany poprzez podanie funkcji proporcjonalnej do gęstości,
.
Zazwyczaj ten rozkład jest dany poprzez podanie funkcji proporcjonalnej do gęstości, ![]() , ale
bez znajomości stałej normującej
, ale
bez znajomości stałej normującej ![]() . Przy tym ,,ogromna” przestrzeń
. Przy tym ,,ogromna” przestrzeń ![]() może być zbiorem
skończonym (ale bardzo licznym) zaś rozkład
może być zbiorem
skończonym (ale bardzo licznym) zaś rozkład ![]() może być… jednostajny, o gęstości
może być… jednostajny, o gęstości ![]() .
Jeśli jednak nośnik rozkładu
.
Jeśli jednak nośnik rozkładu ![]() jest bardzo ,,skomplikowanym” zbiorem, to metody typu eliminacji/akceptacji mogą zawieść. Właśnie z takim przypadkiem spotkaliśmy się już we wstępnym Rozdziale 1, w Przykładzie 1.5. Naszkicowany tam algorytm jest przedstawicielem metod,
którymi obecnie zajmiemy się dokładniej, czyli algorytmów MCMC. Ten skrót oznacza
Markov Chain Monte Carlo, czyli po polsku algorytmy MC wykorzystujące łańcuchy Markowa. Podstawowa idea jest taka: jeśli nie umiemy generować zmiennej losowej
jest bardzo ,,skomplikowanym” zbiorem, to metody typu eliminacji/akceptacji mogą zawieść. Właśnie z takim przypadkiem spotkaliśmy się już we wstępnym Rozdziale 1, w Przykładzie 1.5. Naszkicowany tam algorytm jest przedstawicielem metod,
którymi obecnie zajmiemy się dokładniej, czyli algorytmów MCMC. Ten skrót oznacza
Markov Chain Monte Carlo, czyli po polsku algorytmy MC wykorzystujące łańcuchy Markowa. Podstawowa idea jest taka: jeśli nie umiemy generować zmiennej losowej ![]() o rozkładzie
o rozkładzie ![]() to zadowolimy się generowaniem ciągu zmiennych losowych
to zadowolimy się generowaniem ciągu zmiennych losowych ![]() , który w pewnym sensie zbliża się, zmierza do rozkładu
, który w pewnym sensie zbliża się, zmierza do rozkładu ![]() . Podobnie jak w cytowanym przykładzie ,,plecakowym” ciąg
. Podobnie jak w cytowanym przykładzie ,,plecakowym” ciąg
![]() ma charakter ,,losowego błądzenia” po przestrzeni
ma charakter ,,losowego błądzenia” po przestrzeni ![]() .
.
To wszystko co dotychczas powiedzieliśmy jest bardzo niekonkretne i wymaga uściślenia. W moich wykładach ścisłe przedstawienie
tych zagadnień będzie możliwe tylko w ograniczonym zakresie. W obecnym rozdziale skupię się
na głównych ideach MCMC. Następnie, w Rozdziałach 11 i 12 przedstawię podstawowe algorytmy
i kilka motywujących przykładów, pokażę wyniki symulacji, ale niemal nic nie udowodnię. Sprobuję to częściowo naprawić
w Rozdziałach 14 i 15 , które w całości będą poświęcone łańcuchom Markowa i algorytmom MCMC na
skończonej przestrzeni ![]() . W tej uproszczonej sytuacji podam dowody (a przynajmniej szkice dowodów) podstawowych twierdzeń.
Zastosowania MCMC w przypadku ,,ciągłej”
przestrzeni
. W tej uproszczonej sytuacji podam dowody (a przynajmniej szkice dowodów) podstawowych twierdzeń.
Zastosowania MCMC w przypadku ,,ciągłej”
przestrzeni ![]() (powiedzmy,
(powiedzmy, ![]() ) są przynajmniej równie ważne i w gruncie rzeczy bardzo podobne. Zobaczymy to na paru przykładach. Algorytmy MCMC pracujące na przestrzeni
ciągłej są w zasadzie takie same jak te w przypadku przestrzeni skończonej, ale ich analiza
robi się trudniejsza, wymaga więcej abstrakcyjnej matematyki – i w rezultacie wykracza poza zakres mojego skryptu.
Ograniczę się w tej materii do kilku skromnych uwag. Bardziej systematyczne, a przy tym dość przystępne przedstawienie ogólnej teorii można znaleźć w
[20] lub [17].
) są przynajmniej równie ważne i w gruncie rzeczy bardzo podobne. Zobaczymy to na paru przykładach. Algorytmy MCMC pracujące na przestrzeni
ciągłej są w zasadzie takie same jak te w przypadku przestrzeni skończonej, ale ich analiza
robi się trudniejsza, wymaga więcej abstrakcyjnej matematyki – i w rezultacie wykracza poza zakres mojego skryptu.
Ograniczę się w tej materii do kilku skromnych uwag. Bardziej systematyczne, a przy tym dość przystępne przedstawienie ogólnej teorii można znaleźć w
[20] lub [17].
10.2. Łańcuchy Markowa
Klasyczne metody MCMC, jak sama nazwa wskazuje, opierają się na generowaniu łańcucha Markowa. Co prawda, rozwijają się obecnie bardziej wyrafinowane
metody MCMC (zwane adaptacyjnymi), które wykorzystują procesy niejednorodne a nawet nie-markowowskie. Na razie ograniczymy się do rozpatrzenia sytuacji, gdy generowany ciąg
zmiennych losowych ![]() jest jednorodnym łańcuchem Markowa na przestrzeni
jest jednorodnym łańcuchem Markowa na przestrzeni ![]() . Jeśli
. Jeśli ![]() jest zbiorem skończonym,
możemy posługiwać się Definicją 7.1, w ogólnym przypadku – Definicją 7.2. Przypomnijmy oznaczenie prawdopodobieństw przejścia łańcucha: dla
jest zbiorem skończonym,
możemy posługiwać się Definicją 7.1, w ogólnym przypadku – Definicją 7.2. Przypomnijmy oznaczenie prawdopodobieństw przejścia łańcucha: dla ![]() oraz
oraz ![]() ,
,
W przypadku przestrzeni skończonej wygodniej posługiwać się macierzą przejścia o elementach
Metoda generowania łańcuchów Markowa jest dość oczywista i sprowadza się do wzorów (7.2) w przypadku skończonym i (7.5) w przypadku ogólnym.
10.2.1. Rozkład stacjonarny
Niech ![]() oznacza docelowy rozkład prawdopodobieństwa. Chcemy tak generować łańcuch
oznacza docelowy rozkład prawdopodobieństwa. Chcemy tak generować łańcuch ![]() , czyli
tak wybrać prawdopodobieństwa przejścia
, czyli
tak wybrać prawdopodobieństwa przejścia ![]() , aby uzyskać zbieżność do rozkładu
, aby uzyskać zbieżność do rozkładu ![]() .
Spróbujemy uściślić co to znaczy, w jakim sensie rozumiemy zbieżność.
.
Spróbujemy uściślić co to znaczy, w jakim sensie rozumiemy zbieżność.
Definicja 10.1
Mówimy, że ![]() jest rozkładem stacjonarnym (lub rozkładem równowagi) łańcucha Markowa o prawdopodobieństwach przejścia
jest rozkładem stacjonarnym (lub rozkładem równowagi) łańcucha Markowa o prawdopodobieństwach przejścia
![]() , jeśli dla każdego (mierzalnego) zbioru
, jeśli dla każdego (mierzalnego) zbioru ![]() mamy
mamy
W przypadku skończonej przestrzeni ![]() równoważne sformułowanie jest takie:
dla każdego stanu
równoważne sformułowanie jest takie:
dla każdego stanu ![]() ,
,
Jeśli rozkład początkowy jest rozkładem
stacjonarnym, ![]() , to mamy
, to mamy ![]() dla
każdego
dla
każdego ![]() . Co więcej, w takiej sytuacji
łączny rozkład zmiennych
. Co więcej, w takiej sytuacji
łączny rozkład zmiennych ![]() jest taki sam, jak
rozkład zmiennych
jest taki sam, jak
rozkład zmiennych ![]() . Mówimy, że łańcuch jest w położeniu równowagi lub, ze jest procesem stacjonarnym. To uzasadnia nazwę rozkładu
stacjonarnego. Oczywiście, łańcuchy generowane przez algorytmy MCMC nie są w stanie równowagi, bo z założenia nie umiemy wygenerować
. Mówimy, że łańcuch jest w położeniu równowagi lub, ze jest procesem stacjonarnym. To uzasadnia nazwę rozkładu
stacjonarnego. Oczywiście, łańcuchy generowane przez algorytmy MCMC nie są w stanie równowagi, bo z założenia nie umiemy wygenerować ![]() . Generujemy
. Generujemy ![]() z pewnego innego rozkładu
z pewnego innego rozkładu ![]() , nazywanego rozkładem początkowym. Gdy zajdzie potrzeba, żeby uwidocznić zależność od
rozkładu początkowego, będziemy używali oznaczeń
, nazywanego rozkładem początkowym. Gdy zajdzie potrzeba, żeby uwidocznić zależność od
rozkładu początkowego, będziemy używali oznaczeń ![]() i
i ![]() . Przeważnie start jest po prostu deterministyczny, czyli
. Przeważnie start jest po prostu deterministyczny, czyli ![]() jest rozkładem skupionym w pewnym punkcie
jest rozkładem skupionym w pewnym punkcie ![]() . Piszemy wtedy
. Piszemy wtedy ![]() i
i ![]() .
.
Jeśli ![]() jest rozkładem stacjonarnym, to przy pewnych dodatkowych założeniach uzyskuje się tak zwane Słabe Twierdzenie Ergodyczne (STE). Jego tezą jest zbieżność rozkładów prawdopodobieństwa zmiennych losowych
jest rozkładem stacjonarnym, to przy pewnych dodatkowych założeniach uzyskuje się tak zwane Słabe Twierdzenie Ergodyczne (STE). Jego tezą jest zbieżność rozkładów prawdopodobieństwa zmiennych losowych ![]() do
do ![]() w następującym sensie: dla dowolnego (mierzalnego) zbioru
w następującym sensie: dla dowolnego (mierzalnego) zbioru ![]() i dowolnego rozkładu początkowego
i dowolnego rozkładu początkowego ![]() mamy
mamy
| (10.1) |
Dla skończonej przestrzeni ![]() równoważne jest stwierdzenie, że dla każdego
równoważne jest stwierdzenie, że dla każdego ![]() ,
,
Pewną wersję STE dla skończonej przestrzeni ![]() udowodnimy w następnym rozdziale (Twierdzenie 14.5). Na razie poprzestańmy na następującym prostym spostrzeżeniu.
udowodnimy w następnym rozdziale (Twierdzenie 14.5). Na razie poprzestańmy na następującym prostym spostrzeżeniu.
Uwaga 10.1
Jeżeli zachodzi teza STE dla pewnego rozkładu granicznego ![]() , czyli
, czyli
![]() dla dowolnych
dla dowolnych ![]() ,
, ![]() ,
to
,
to ![]() jest rozkładem stacjonarnym. W istocie, wystarczy przejść do granicy
w równości
jest rozkładem stacjonarnym. W istocie, wystarczy przejść do granicy
w równości
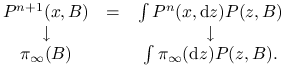 |
Co więcej, ![]() jest jedynym rozkładem stacjonarnym.
jest jedynym rozkładem stacjonarnym.
Uwaga 10.2
W teorii łańcuchów Markowa rozważa się różne pojęcia zbieżności
rozkładów. Zauważmy, że w powyżej przytoczonej tezie STE oraz w Uwadze 10.1 mamy do czynienia z silniejszym rodzajem zbieżności, niż poznana
na rachunku prawdopodobieństwa zbieżność słaba (według rozkładu), oznaczana ![]() .
.
10.2.2. Twierdzenia graniczne dla łańcuchów Markowa
Naszkicujemy podstawowe twierdzenia graniczne dla łańcuchów Markowa. Dokładniejsze sformułowania i dowody pojawią się w następnym rozdziale i będą ograniczone do przypadku skończonej przestrzeni ![]() .
Bardziej dociekliwych Czytelników muszę odesłać do przeglądowych prac [20, 13].
.
Bardziej dociekliwych Czytelników muszę odesłać do przeglądowych prac [20, 13].
Sformułujemy najpierw odpowiednik Mocnego Prawa Wielkich Liczb (PWL) dla łańcuchów Markowa. Rozważmy funkcję ![]() . Wartość oczekiwana funkcji
. Wartość oczekiwana funkcji ![]() względem rozkładu
względem rozkładu ![]() jest określona jako całka
jest określona jako całka
Jeżeli rozkład ![]() ma gęstość
ma gęstość ![]() względem miary Lebesgue'a to jest to ,,zwyczajna
całka”,
względem miary Lebesgue'a to jest to ,,zwyczajna
całka”,
W przypadku dyskretnej przestrzeni ![]() jest to suma
jest to suma
Jeśli załóżmy ![]() jest rozkładem stacjonarnym łańcucha Markowa
jest rozkładem stacjonarnym łańcucha Markowa ![]() , to możemy oczekiwać, że zachodzi zbieżność średnich do granicznej wartości oczekiwanej,
, to możemy oczekiwać, że zachodzi zbieżność średnich do granicznej wartości oczekiwanej,
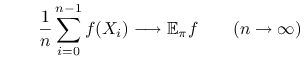 |
(10.2) |
z prawdopodobieństwem 1.
W istocie, można udowodnić (10.2) przy pewnych dodatkowych założeniach.
Mówimy wtedy, że zachodzi PWL lub Mocne Twierdzenie Ergodyczne.
Ze względu na zastosowania MCMC, wymagamy aby (10.2) zachodziło dla
dowolnego rozkładu początkowego ![]() (a nie dla
(a nie dla ![]() , czyli dla łańcucha stacjonarnego).
Jedną z wersji PWL dla łańcuchów Markowa przedstawimy, wraz z pięknym i prostym dowodem, w Rozdziale 14 rozdziale (Twierdzenie 14.3).
, czyli dla łańcucha stacjonarnego).
Jedną z wersji PWL dla łańcuchów Markowa przedstawimy, wraz z pięknym i prostym dowodem, w Rozdziale 14 rozdziale (Twierdzenie 14.3).
Centralne Twierdzenie Graniczne (CTG) dla łańcuchów Markowa ma
tezę następującej postaci. Dla dowolnego rozkładu początkowego ![]() zachodzi zbieżność według rozkładu:
zachodzi zbieżność według rozkładu:
![\qquad\frac{1}{\sqrt{n}}\left(\sum _{{i=0}}^{{n-1}}[f(X_{i})-\mathbb{E}_{\pi}f]\right)\longrightarrow{\rm N}\big(0,{\sigma _{{\rm as}}^{{2}}(f)}\big)\quad(n\to\infty).](wyklady/sst/mi/mi1283.png) |
(10.3) |
Liczba ![]() , zwana asymptotyczną wariancją, nie zależy od rozkładu początkowego
, zwana asymptotyczną wariancją, nie zależy od rozkładu początkowego ![]() , zależy zaś od macierzy przejścia
, zależy zaś od macierzy przejścia ![]() i funkcji
i funkcji ![]() .
Ponadto można udowodnić następujący fakt: dla dowolnego rozkładu początkowego
.
Ponadto można udowodnić następujący fakt: dla dowolnego rozkładu początkowego ![]() ,
,
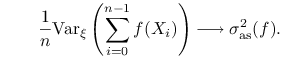 |
(10.4) |
Przy pewnych dodatkowych założeniach, asymptotyczną wariancję można wyrazić w terminach ,,stacjonarnych kowariancji” jak następuje. Mamy
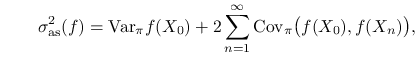 |
(10.5) |
gdzie ![]() i
i ![]() oznaczają, oczywiście, wariancję i
kowariancję obliczoną przy założeniu, że łańcuch jest stacjonarny. Niech
oznaczają, oczywiście, wariancję i
kowariancję obliczoną przy założeniu, że łańcuch jest stacjonarny. Niech
Przyjmijmy jeszcze, że ![]() . To określenie jest naturalne bo łańcuch stacjonarny można ,,przedłużyć wstecz”. Wzór (10.5) można przepisać tak:
. To określenie jest naturalne bo łańcuch stacjonarny można ,,przedłużyć wstecz”. Wzór (10.5) można przepisać tak:
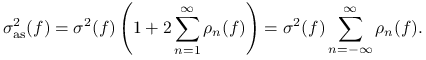 |
Później pojawi się kilka innych wzorów na asymptotyczną wariancję.
W tym miejscu chcę podkreślić różnicę między stacjonarną wariancją ![]() i asymptotyczną wariancją
i asymptotyczną wariancją ![]() . W większości zastosowań kowariancje we wzorze (10.5) są
dodatnie (zmienne losowe
. W większości zastosowań kowariancje we wzorze (10.5) są
dodatnie (zmienne losowe ![]() i
i ![]() są dodatnio skorelowane). W rezultacie
są dodatnio skorelowane). W rezultacie ![]() jest dużo większa od
jest dużo większa od ![]() . To jest cena, którą płacimy za używanie łańcucha Markowa zamiast ciągu zmiennych niezależnych, jak
w Rozdziale 8.
. To jest cena, którą płacimy za używanie łańcucha Markowa zamiast ciągu zmiennych niezależnych, jak
w Rozdziale 8.
Zauważmy, że algorytmy Monte Carlo przeważnie mają za zadanie obliczyć pewną
wartość oczekiwaną, a więc wielkość postaci ![]() . Jeśli potrafimy generować łańcuch Markowa zbieżny do
. Jeśli potrafimy generować łańcuch Markowa zbieżny do ![]() , to naturalnym estymatorem
, to naturalnym estymatorem ![]() jest
jest
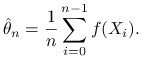 |
Możemy tezy PWL oraz CTG zapisać w skrócie tak:
PWL gwarantuje zgodność estymatora, a więc w pewnym sensie poprawność metody. Jest to, rzecz jasna, zaledwie wstęp do dokładniejszej analizy algorytmu.
Zauważmy, że CTG może służyć do budowania asymptotycznych przedziałów ufności
dla estymowanej wielkości ![]() : jeśli przyjmiemy poziom ufności
: jeśli przyjmiemy poziom ufności ![]() i dobierzemy odpowiedni kwantyl
i dobierzemy odpowiedni kwantyl ![]() rozkładu normalnego, to
rozkładu normalnego, to
Oczywiście, ![]() oznacza to dystrybuantę rozkładu
oznacza to dystrybuantę rozkładu ![]() i
i ![]() . Potrzebne jest jeszcze oszacowanie asymptotycznej wariancji
. Potrzebne jest jeszcze oszacowanie asymptotycznej wariancji ![]() , co nie jest wcale łatwe. Co więcej, CTG nie daje żadnej informacji o tym, dla jakich
, co nie jest wcale łatwe. Co więcej, CTG nie daje żadnej informacji o tym, dla jakich ![]() przybliżenie rozkładem normalnym jest rozsądne.
przybliżenie rozkładem normalnym jest rozsądne.
Graniczne zachowanie wariancji estymatora ![]() wyjaśnia wzór (10.4). Uzupełnijmy to (pomijając chwilowo uzasadnienie) opisem granicznego zachowania obciążenia:
przy
wyjaśnia wzór (10.4). Uzupełnijmy to (pomijając chwilowo uzasadnienie) opisem granicznego zachowania obciążenia:
przy ![]() ,
,
Oczywiście, naturalną miarą jakości estymatora jest
błąd średniokwadratowy (BŚK). Ponieważ BŚK jest sumą wariancji i kwadratu obciążenia to, przynajmniej w granicy dla ![]() , wariancja ma dominujący wpływ, zaś obciążenie staje się zaniedbywalne:
, wariancja ma dominujący wpływ, zaś obciążenie staje się zaniedbywalne:
| (10.6) |
Powtóżmy jednak zastrzeżenie dotyczące wszystkich wyników zawartych w tym podrozdziale, Wzór (10.6) tylko sugeruje pewne przybliżenie interesującej nas wielkości.
Sławne i ważne twierdzenia graniczne sformułowane w tym podrozdziale nie są, niestety, całkowicie zadowalającym narzędziem analizy algorytmów Monte Carlo. Algorytmy wykorzystujące łańcuchy Markowa są użyteczne wtedy, gdy osiągają wystarczającą
dokładność dla liczby kroków ![]() znikomo małej w porównaniu
z rozmiarem przestrzeni stanów. W przeciwnym przypadku można po prostu
deterministycznie ,,przejrzeć wszystkie stany” i dokładnie obliczyć
interesującą nas wielkość.
znikomo małej w porównaniu
z rozmiarem przestrzeni stanów. W przeciwnym przypadku można po prostu
deterministycznie ,,przejrzeć wszystkie stany” i dokładnie obliczyć
interesującą nas wielkość.
Niemniej, twierdzenia graniczne są interesujące z jakościowego punktu widzenia. Ponadto, ważne dla nas oszacowania dotyczące zachowania łańcucha w skończonym czasie można porównać z wielkościami granicznymi, aby ocenić ich jakość.


