Zagadnienia
2. Podstawy R i ćwiczenia komputerowe
Oczekuję, że Czytelnik uruchomił pakiet (lub ,,otoczenie”, environment) R. Nie zakładam żadnej wstępnej znajomości tego języka programowania. Oczywiście, podstaw programowania w R można się nauczyć z odpowiednich źródeł. Ale prawdę mówiąc, prostych rzeczy można się szybko domyślić i zacząć zabawę natychmiast.
2.1. Początki
Przykład 2.1 (Rozkład prawdopodobieństwa i próbka losowa)
Wylosujmy ,,próbkę” średniego rozmiaru, powiedzmy ![]() z rozkładu normalnego
z rozkładu normalnego ![]() :
:
> n <- 100
> X <- rnorm(n)
> X
(aby przyjrzeć się funkcji rnorm, napiszmy ?rnorm). Wektor X zawiera
,,realizacje” niezależnych zmiennych losowych ![]() .
Możemy obliczyć średnią
.
Możemy obliczyć średnią ![]() i wariancję próbkową
i wariancję próbkową
![]() . Jakich wyników oczekujemy? Zobaczmy:
. Jakich wyników oczekujemy? Zobaczmy:
> mean(X)
> var(X)
Porównajmy kwantyl empiryczny rzędu, powiedzmy ![]() , z teoretycznym:
, z teoretycznym:
> quantile(X,p)
> qnorm(p)
Możemy powtórzyć nasze ,,doświadczenie losowe” i zobaczyć jakie są losowe fluktuacje wyników. Warto wykonać nasz mini-programik jeszcze raz, albo parę razy. Teraz sprobujmy ,,zobaczyć” próbkę. Najlepiej tak:
> hist(X,prob=TRUE) ( proszę się dowiedzieć co znaczy parametr `prob' ! )
> rug(X)
Możemy łatwo narysować wykres gęstości. Funkcja obliczająca gęstość ![]() rozkładu
rozkładu ![]() nazywa
się dnorm, a curve jest funkcją rysującą wykresy.
nazywa
się dnorm, a curve jest funkcją rysującą wykresy.
> curve(dnorm(x),col="blue",add=TRUE)
(nawiasem mówiąc, zachęcam początkujących pRobabilistów do oznaczania wygenerowanych wektorów losowych dużymi literami, np. X, a deterministycznych zmiennych i wektorów – małymi, np. x, podobnie jak na rachunku prawdopodobieństwa).
Podobnie, możemy porównać dystrybuantę empiryczną z prawdziwą dystrybuantą ![]() .
Funkcja obliczająca dystrybuantę empiryczną nazywa się ecdf, zaś
dystrybuantę rozkładu
.
Funkcja obliczająca dystrybuantę empiryczną nazywa się ecdf, zaś
dystrybuantę rozkładu ![]() – pnorm.
– pnorm.
> plot(ecdf(X))
> curve(pnorm(x),from=xmin,to=xmax,col="blue",add=TRUE)
Test Kołmogorowa-Smirnowa oblicza maksymalną odległość ![]() , gdzie
, gdzie ![]() jest dystrybuantą empiryczną i
jest dystrybuantą empiryczną i ![]() .
.
> ks.test(X,pnorm,exact=TRUE)
Przypomnijmy sobie z wykładu ze statystyki, co znaczy podana przez test ![]() -wartość. Jakiego wyniku ,,spodziewaliśmy się”?
-wartość. Jakiego wyniku ,,spodziewaliśmy się”?
Jest teraz dobra okazja, aby pokazać jak się symulacyjnie bada rozkład zmiennej losowej. Przypuśćmy, że interesuje nas rozkład
prawdopodobieństwa ![]() -wartości w przeprowadzonym powyżej doświadczeniu (polegającym na wylosowaniu próbki
-wartości w przeprowadzonym powyżej doświadczeniu (polegającym na wylosowaniu próbki ![]() i przeprowadzeniu testu KS).
Tak naprawdę powinniśmy znać odpowiedź bez żadnych doświadczeń, ale możemy udawać niewiedzę i symulować.
i przeprowadzeniu testu KS).
Tak naprawdę powinniśmy znać odpowiedź bez żadnych doświadczeń, ale możemy udawać niewiedzę i symulować.
Przykład 2.2 (Powtarzanie doświadczenia symulacyjnego)
Symulacje polegają na
powtórzeniu całego doświadczenia wiele razy, powiedzmy ![]() razy, zanotowaniu wyników i uznaniu powstałego rozkładu
empirycznego za przybliżenie badanego rozkładu prawdopodobieństwa. Bardzo ważne jest zrozumienie różnej roli jaką pełni tu
razy, zanotowaniu wyników i uznaniu powstałego rozkładu
empirycznego za przybliżenie badanego rozkładu prawdopodobieństwa. Bardzo ważne jest zrozumienie różnej roli jaką pełni tu ![]() (rozmiar próbki
w pojedynczym doświadczeniu, a więc ,,parametr badanego zjawiska”) i
(rozmiar próbki
w pojedynczym doświadczeniu, a więc ,,parametr badanego zjawiska”) i ![]() (liczba powtórzeń, która powinna być możliwie największa aby
zwiększyć dokładność badania symulacyjnego).
Następujący progarmik podkreśla logiczną konstrukcję powtarzanego doświadczenia:
(liczba powtórzeń, która powinna być możliwie największa aby
zwiększyć dokładność badania symulacyjnego).
Następujący progarmik podkreśla logiczną konstrukcję powtarzanego doświadczenia:
> m <- 10000
> n <- 100
>
> # Przygotowujemy wektory w którym zapiszemy wyniki:
> D <- c()
> P <- c()
>
> for (i in 1:m)
> {
> X <- rnorm(n)
> Test <- ks.test(X,pnorm,exact=TRUE)
> D[i] <- Test$statistic
> P[i] <- Test$p.value
> } # koniec pętli for
>
> # Analizujemy wyniki:
> hist(D, prob=TRUE)
> hist(P, prob=TRUE)
Co prawda powyższy programik spełnia swoją rolę, jednak struktura pakiektu R jest dostosowana do innego stylu pisania programów. Zamiast pętli for zalecane jest używanie funkcji które powtarzają pewne operacje i posługiwanie się, kiedykolwiek to możliwe, całymi wektorami a nie pojedynczymi komponentami. Poniższy fragment kodu zastępuje pętlę for
> DiP <- replicate(m, ks.test(rnorm(n),pnorm,exact=TRUE)[1:2]))
>
> DiP <- t(DiP) # transpozycja macierzy ułatwia oglądanie wyników
> D <- as.numeric((DiP)[,1]) # pierwsza kolumna macierzy
> P <- as.numeric((DiP)[,2]) # druga kolumna macierzy
> # obiekty typu ,,list'' przerobimy na wektory liczbowe:
> D <- as.numeric(D); P <- as.numeric(D)
Symulacje dają okazję ,,namacalnego” przedstawienia twierdzeń probabilistycznych (i nie tylko twierdzeń, ale także stwierdzeń, przypuszczeń prawdziwych lub fałszywych).
Przykład 2.3 (Mocne Prawo Wielkich Liczb)
Wylosujmy próbkę z ,,jakiegoś” rozkładu prawdopodobieństwa. Weźmy na przykład niezależne zmienne o rozkładzie wykładniczym,
![]() . Obliczmy średnie empiryczne
. Obliczmy średnie empiryczne
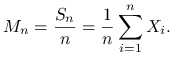 |
Zróbmy wykres ciągu średnich ![]() .
.
> nmax <- 1000 # komputerowy odpowiednik ,,![]() ''
''
> n <- (1:nmax)
> lambda <- 2
> X <- rexp(nmax,rate=lambda)
> S <- cumsum(X) # ciąg narastających sum
> M <- S/n # działania w R (np. dzielenie) są wykonywane ,,po współrzędnych''
> plot(n,M,type="l") # ,,zaklęcie'' type="l" powoduje narysowanie łamanej
Teraz spóbujmy podobne doświadczenie zrobić dla zmiennych ![]() , gdzie
, gdzie ![]() (
(![]() są próbką z tak zwanego rozkładu Pareto).
są próbką z tak zwanego rozkładu Pareto).
> # potrzebujemy dużej próbki, żeby się zorientować, co się dzieje...
> nmax <- 100000
> n <- (1:nmax)
> X <- 1/runif(nmax)-1
> M <- cumsum(X)/n
> plot(log(n),M,type="l") # i zrobimy wykres w skali logarytmicznej
Przykład 2.4 (Centralne Twierdzenie Graniczne)
CTG jest jednym ze ,,słabych” twierdzeń granicznych rachunku prawdopodobieństwa, to znaczy dotyczy zbieżności rozkładów. Symulacyne ,,sprawdzenie” lub ilustracja takich twierdzeń wymaga powtarzania doświadczenia wiele razy, podobnie jak w Przykładzie 2.2. Pojedyncze doświadczenie polega na obliczeniu sumy
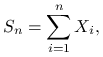 |
gdzie ![]() jest próbką z ,,jakiegoś” rozkładu prawdopodobieństwa i
jest próbką z ,,jakiegoś” rozkładu prawdopodobieństwa i ![]() jest ,,duże”.
Weźmy na przykład niezależne zmienne o rozkładzie wykładniczym, jak w Przykładzie 2.3.
jest ,,duże”.
Weźmy na przykład niezależne zmienne o rozkładzie wykładniczym, jak w Przykładzie 2.3.
> m <- 10000
> n <- 100
> lambda <- 2
> S <- replicate(m, sum(rexp(n,rate=lambda)))
> hist(S,prob=TRUE)
> curve(dnorm(x,mean=n/lambda,sd=sqrt(n)/lambda),col="blue",add=TRUE)
> # wydaje się na podstawie obrazka, że dopasowanie jest znakomite
> ks.test(S,pnorm,mean=n/lambda,sd=sqrt(n)/lambda)
> # ale test Kołmogorowa-Smirnowa ,,widzi'' pewne odchylenie od rozkładu normalnego
>
2.2. Ćwiczenia
Ćwiczenie 2.1
Wyjaśnić dlaczego w Przykładzie 2.4 nie musieliśmy (choć mogliśmy) rozpatrywać unormowanych zmiennych losowych
gdzie ![]() i
i ![]() .
.
Ćwiczenie 2.2
W Przykładzie 2.4 znany jest dokładny rozkład prawdopodobieństwa sumy ![]() . Co to za rozkład? Sprawdzić symulacyjnie zgodność z tym rozkładem.
. Co to za rozkład? Sprawdzić symulacyjnie zgodność z tym rozkładem.
Ćwiczenie 2.3
Przeprowadzić podobne doświadczenie jak w Przykładzie 2.4 (CTG), dla ![]() i
i ![]() .
Skomentować wynik.
.
Skomentować wynik.
Ćwiczenie 2.4
Przeprowadzić podobne doświadczenie jak w Ćwiczeniu 2.3, ale zastępując sumę przez medianę dla
![]() i
i ![]() . Wypróbować przybliżenie normalne
(jeśli teoretyczna wartość wariancji mediany nie jest znana, można zastąpić ją przez przybliżenie empiryczne). Skomentować wynik.
. Wypróbować przybliżenie normalne
(jeśli teoretyczna wartość wariancji mediany nie jest znana, można zastąpić ją przez przybliżenie empiryczne). Skomentować wynik.
Ćwiczenie 2.5
W Ćwiczeniu 2.3, znany jest dokładny rozkład prawdopodobieństwa mediany. Co to za rozkład?
Sprawdzić symulacyjnie zgodność z tym rozkładem. Można wziąć mniejsze, nieparzyste ![]() . Dlaczego nieparzyste?
. Dlaczego nieparzyste?


